

Article original : Skewness and Kurtosis – Positively Skewed and Negatively Skewed Distributions in Statistics Explained
Par Rishit Dagli
Dans cet article, je vais expliquer deux concepts importants en statistiques : l'asymétrie et le kurtosis. Et ne vous inquiétez pas – vous n'aurez pas besoin de connaître beaucoup de mathématiques pour comprendre ces concepts et apprendre à les appliquer.
Qu'est-ce que les Courbes de Densité ?
Parlons d'abord un peu des courbes de densité, car l'asymétrie et le kurtosis sont basés sur elles. Elles sont simplement un moyen pour nous de représenter une distribution. Voyons ce que je veux dire à travers un exemple.
Supposons que vous devez enregistrer les tailles de beaucoup de personnes. Donc, votre distribution a, disons, 20 catégories représentant la plage des résultats (58-59 pouces, 59-60 pouces ... 78-79). Vous pouvez tracer un histogramme représentant ces catégories et le nombre de personnes dont la taille tombe dans chaque catégorie.
 Histogramme de la taille par rapport à la population
Histogramme de la taille par rapport à la population
Eh bien, vous pourriez faire cela pour des milliers de personnes, donc vous n'êtes pas intéressé par le nombre exact – plutôt par le pourcentage ou la probabilité de ces catégories.
J'ai également explicitement mentionné que vous avez une distribution plutôt grande puisque les pourcentages sont souvent inutiles pour les petites distributions.
Si vous utilisez des pourcentages avec des nombres plus petits, je fais souvent référence à cela comme mentir avec des statistiques – c'est une déclaration qui est techniquement correcte mais crée la mauvaise impression dans nos esprits.
Permettez-moi de vous donner un exemple : un étudiant est extrêmement excité et dit à tout le monde dans sa classe qu'il a fait une amélioration de 100 % dans ses notes ! Mais ce qu'il ne dit pas, c'est que ses notes sont passées de 2/30 à 4/30 😂.
J'espère que vous voyez maintenant clairement le problème de l'utilisation des pourcentages avec des nombres plus petits.
Revenons aux courbes de densité, lorsque vous travaillez avec une grande distribution, vous voulez avoir des catégories plus granulaires. Donc, vous faites de chaque catégorie qui était large de 1 pouce, maintenant 2 catégories chacune large de (\frac{1}{2}) pouce. Peut-être que vous voulez obtenir encore plus granulaire et commencer à utiliser des catégories larges de (\frac{1}{4}) pouce. Pouvez-vous deviner où je veux en venir avec cela ?
À un moment donné, nous obtenons un nombre infini de telles catégories avec une longueur infiniment petite. Cela nous permet de créer une courbe à partir de cet histogramme que nous avions précédemment divisé en catégories discrètes. Voyez notre courbe de densité ci-dessous tracée à partir de l'histogramme.
 Courbe de densité de probabilité pour notre distribution
Courbe de densité de probabilité pour notre distribution
Pourquoi faire tout cet effort ?
Excellente question ! Comme vous l'avez peut-être deviné, j'aime expliquer avec des exemples, alors regardons une autre courbe de densité pour que ce soit un peu plus facile à comprendre. N'hésitez pas à sauter l'équation de la courbe à ce stade si vous n'avez pas travaillé avec des distributions auparavant.
Vous pouvez également suivre et créer les graphiques et visualisations de cet article vous-même via ce projet Geogebra (il fonctionne dans le navigateur).
$$ f(x) = \frac{1}{0.4 \sqrt{2 \pi} } \cdot e^{-\frac{1}{2} (\frac{x - 1.6}{0.4})^2} $$

Alors maintenant, si je vous demande "Quel pourcentage de ma distribution se trouve dans la catégorie 1 - 1.6 ?" Eh bien, vous calculez simplement l'aire sous la courbe entre 1 et 1.6, comme ceci :
$$ \int_{1}^{1.6} f(x) \,dx $$

Il serait également relativement facile pour vous de répondre à des questions similaires à partir de la courbe de densité comme : "Quel pourcentage de la distribution est inférieur à 1.2 ?" ou "Quel pourcentage de la distribution est supérieur à 1.2 ?"
Vous pouvez maintenant probablement voir pourquoi l'effort de créer cette courbe de densité en vaut la peine et comment elle vous permet de faire des inférences facilement 🚀.
Distributions Asymétriques
Parlons maintenant un peu des distributions asymétriques – c'est-à-dire celles qui ne sont pas aussi agréables et symétriques que les courbes que nous avons vues précédemment. Nous en parlerons de manière plus intuitive en utilisant les idées de moyenne et de médiane.
À partir de l'image du graphique de la courbe de densité, essayez de déterminer où se situerait la médiane de cette distribution. Peut-être était-il facile pour vous de le déterminer – la courbe est symétrique et vous avez peut-être conclu que la médiane est 1.6 puisqu'elle était symétrique autour de (x=1.6).
Une autre façon de procéder serait de dire que la médiane est la valeur où l'aire sous la courbe à gauche de celle-ci et l'aire sous la courbe à droite de celle-ci sont égales.
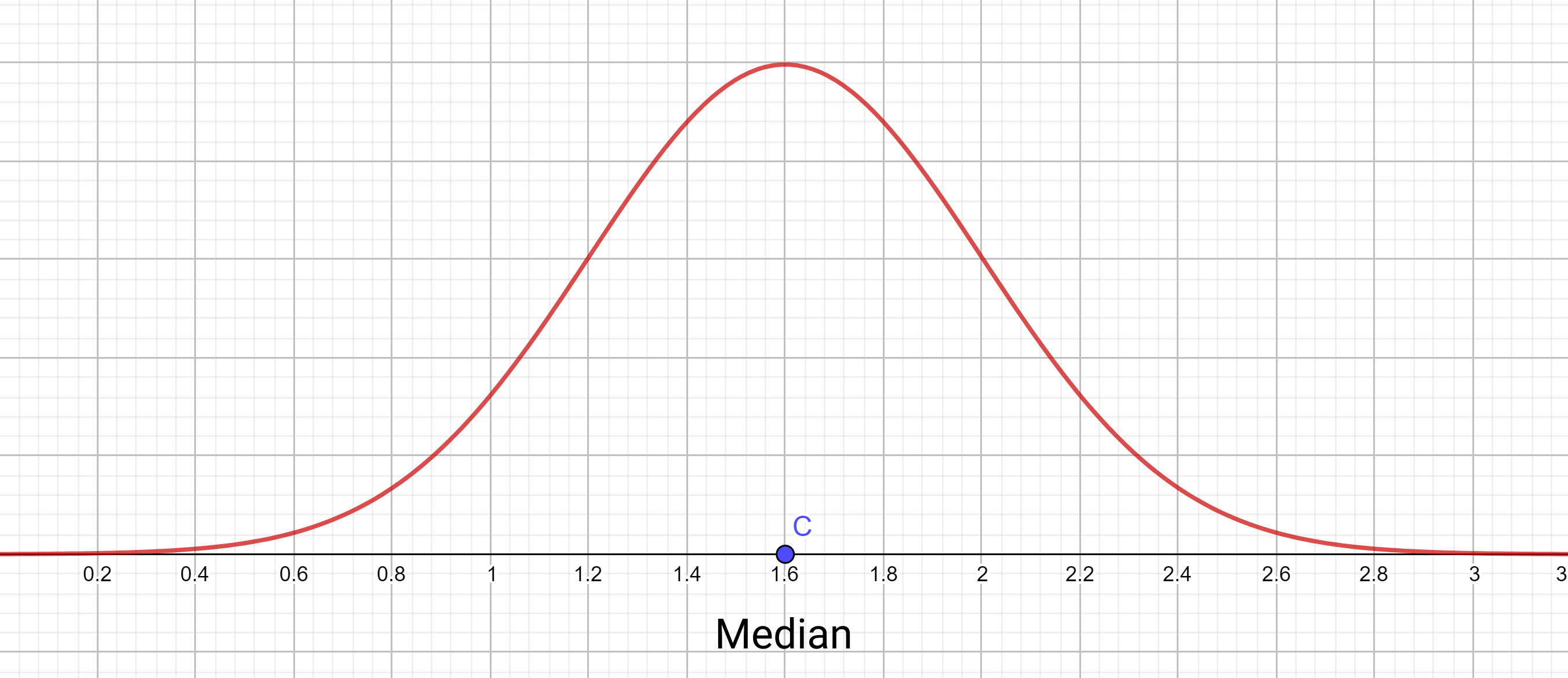
Nous parlons de cette idée car elle nous permet également de calculer la médiane pour les courbes de densité non symétriques.
En guise d'exemple ici, je montre deux distributions asymétriques très courantes et comment l'idée des aires égales que nous venons de discuter nous aide à trouver leurs médianes. Si nous avons essayé de déterminer notre médiane à l'œil nu, voici ce que nous obtiendrions puisque nous voulons que les aires de chaque côté soient égales.
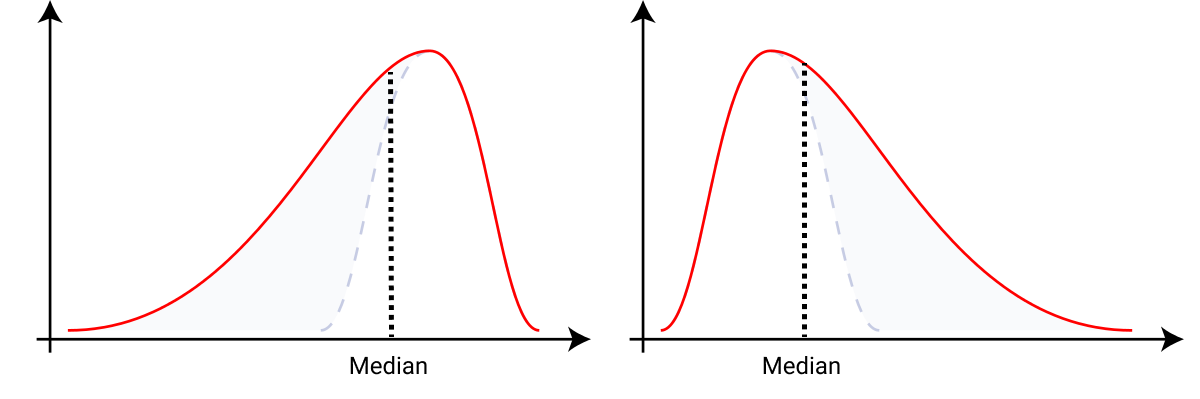 Détermination de la médiane à l'œil nu pour les courbes asymétriques
Détermination de la médiane à l'œil nu pour les courbes asymétriques
Vous pouvez également calculer la moyenne à travers ces courbes de densité. Peut-être avez-vous déjà essayé de calculer la moyenne vous-même, mais remarquez que si vous utilisez la formule générale pour calculer la moyenne :
$$ moyenne = \frac{\sum a_n}{n} $$
vous pourriez remarquer un défaut : nous prenons en compte les valeurs ( x ) mais nous avons également des probabilités associées à ces valeurs. Et il est logique de tenir compte de cela également.
Nous modifions donc la manière dont nous calculons la moyenne en utilisant des moyennes pondérées. Nous aurons maintenant également un terme (w_n) représentant les poids associés :
$$ moyenne = \frac{\sum{a_n \cdot w_n}}{n} $$
Nous utiliserons donc l'idée que nous venons de discuter pour calculer la moyenne à partir de notre courbe de densité.
Vous pouvez également comprendre cela de manière plus intuitive comme le point sur l'axe des x où vous pourriez placer un point d'appui et équilibrer la courbe si elle était un objet solide. Cette idée devrait vous aider à mieux comprendre la recherche de la moyenne à partir de notre courbe de densité.
Mais une autre façon vraiment intéressante de voir cela serait comme la coordonnée x du point sur cette courbe où l'inertie rotationnelle serait nulle.
Vous avez peut-être déjà compris comment nous pouvons localiser la moyenne pour les courbes symétriques : notre médiane et notre moyenne se situent au même point, le point de symétrie.
Nous utiliserons l'idée que nous venons de discuter, en plaçant un point d'appui sur l'axe des x et en équilibrant la courbe, pour déterminer à l'œil nu la moyenne pour les graphiques asymétriques comme ceux que nous avons vus précédemment lors du calcul de la médiane.
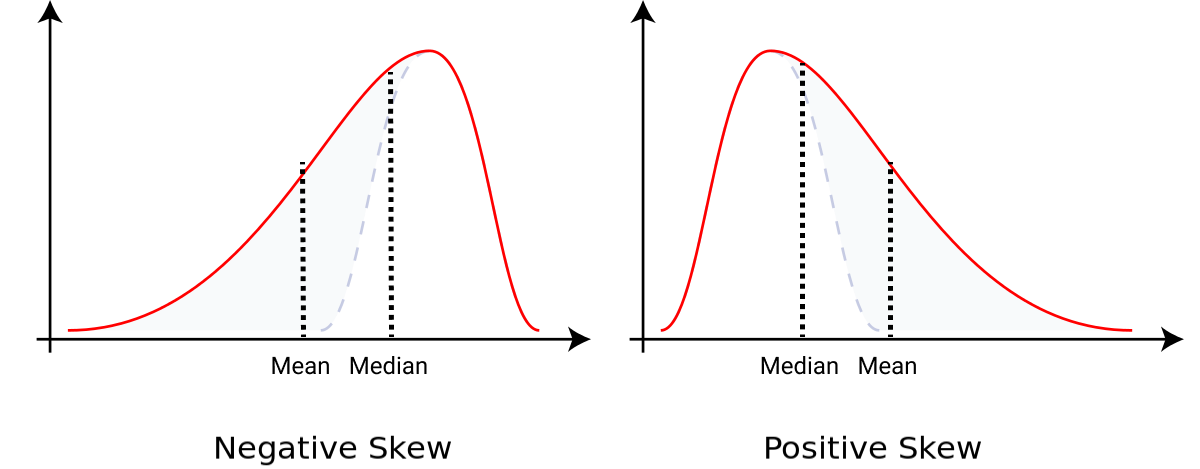
Nous allons bientôt discuter de l'idée d'asymétrie plus en détail. Mais à ce stade, généralement parlant, vous pouvez identifier la direction où votre courbe est asymétrique. Si la médiane est à droite de la moyenne, alors elle est asymétrique négativement. Et si la moyenne est à droite de la médiane, alors elle est asymétrique positivement.
Plus tard dans cet article, pour simplifier, nous appellerons également la partie étroite de ces courbes une "queue".
Qu'est-ce que les Moments ?
Avant de parler davantage de l'asymétrie et du kurtosis, explorons un peu l'idée des moments. Plus tard, nous utiliserons ce concept pour développer une idée de mesure de l'asymétrie et du kurtosis dans notre distribution.
Nous utiliserons un petit ensemble de données, [1, 2, 3, 3, 3, 6]. Ces nombres signifient que vous avez des points qui sont à 1 unité de l'origine, 2 unités de l'origine, et ainsi de suite.
Nous nous soucions donc beaucoup des distances par rapport à l'origine dans notre ensemble de données. Nous pouvons représenter la distance moyenne par rapport à l'origine dans nos données en écrivant :
$$ \frac{\sum a_n -0}{n} = \frac{\sum a_n}{n} $$
C'est ce que nous appelons notre premier moment. En calculant cela pour notre ensemble de données d'exemple, nous obtenons 3, mais si nous changeons notre ensemble de données et rendons tous les éléments égaux à 3,
$$ [1, 2, 3, 3, 3, 6] \rightarrow [3, 3, 3, 3, 3, 3] $$
vous verrez que notre premier moment reste le même. Pouvez-nous concevoir quelque chose pour différencier nos deux ensembles de données qui ont des premiers moments égaux ? (PS : C'est le deuxième moment.)
Nous allons calculer la somme moyenne des distances au carré plutôt que la somme moyenne des distances :
$$ \frac{\sum (a_n)^2}{n} $$
Notre deuxième moment pour notre ensemble de données original est 11,33 et pour notre nouvel ensemble de données est 9. Remarquez que la magnitude du deuxième moment est plus grande pour notre ensemble de données original que pour le nouveau. De plus, nous avons une valeur plus élevée pour le deuxième moment dans l'ensemble de données original car il est plus étalé et a une distance quadratique moyenne plus grande.
Essentiellement, nous disons que nous avons quelques valeurs dans notre ensemble de données original plus grandes que la valeur moyenne, qui, lorsqu'elles sont élevées au carré, augmentent notre deuxième moment de beaucoup.
Voici une façon intéressante de penser aux moments – supposons que notre distribution est une masse, et alors le premier moment serait le centre de la masse, et le deuxième moment serait l'inertie rotationnelle.
Vous pouvez également voir que notre deuxième moment dépend fortement de notre premier moment. Mais nous sommes intéressés à connaître les informations que le deuxième moment peut nous donner indépendamment.
Pour ce faire, nous calculons les distances au carré par rapport à la moyenne ou au premier moment plutôt que par rapport à l'origine.
$$ \frac{\sum (a_n- \mu_{1}^{'})^2 }{n} $$
Avez-vous remarqué que nous avons également dérivé intuitivement une formule pour la variance ? À l'avenir, vous verrez comment nous utilisons les idées dont nous venons de parler pour mesurer l'asymétrie et le kurtosis.
Introduction à l'Asymétrie et au Kurtosis
Voyons comment nous pouvons utiliser l'idée des moments dont nous avons parlé précédemment pour déterminer comment nous pouvons mesurer l'asymétrie (dont vous avez déjà une certaine idée) et le kurtosis.
Qu'est-ce que l'Asymétrie ?
Prenons l'idée des moments dont nous avons parlé il y a un instant et essayons de calculer le troisième moment. Comme vous l'avez peut-être deviné, nous pouvons calculer les cubes de nos distances. Mais comme nous en avons discuté ci-dessus, nous sommes plus intéressés à voir les informations supplémentaires que le troisième moment fournit.
Nous voulons donc soustraire le deuxième moment de notre troisième moment. Plus tard, nous appellerons également ce facteur l'ajustement du moment. Notre moment ajusté ressemblera à ceci :
$$ asymétrie = \frac{\sum (a_n - \mu)^3 }{n \cdot \sigma ^3} $$
Ce moment ajusté est ce que nous appelons asymétrie. Il nous aide à mesurer l'asymétrie dans les données.
Des données parfaitement symétriques auraient une valeur d'asymétrie de 0. Une valeur d'asymétrie négative implique qu'une distribution a sa queue du côté gauche de la distribution, tandis qu'une valeur d'asymétrie positive a sa queue du côté droit de la distribution.
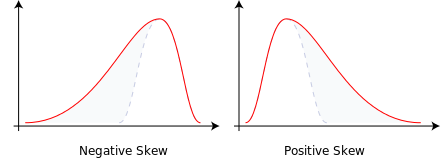 Asymétrie positive et asymétrie négative
Asymétrie positive et asymétrie négative
À ce stade, il peut sembler que le calcul de l'asymétrie serait assez difficile à faire puisque dans les formules nous utilisons la moyenne de la population ( \mu ) et l'écart-type de la population ( \sigma ) auxquels nous n'aurions pas accès lors de la prise d'un échantillon.
Au lieu de cela, vous n'avez que la moyenne de l'échantillon et l'écart-type de l'échantillon, donc nous verrons bientôt comment vous pouvez utiliser ceux-ci.
Qu'est-ce que le Kurtosis ?
Comme vous l'avez peut-être deviné, cette fois nous allons calculer notre quatrième moment ou utiliser la quatrième puissance de nos distances. Et comme nous en avons parlé plus tôt, nous sommes intéressés à voir les informations supplémentaires que cela fournit, donc nous allons également soustraire le facteur d'ajustement.
C'est ce que nous appelons kurtosis ou une mesure de savoir si nos données ont beaucoup de valeurs aberrantes ou très peu de valeurs aberrantes. Cela ressemblera à ceci :
$$ kurtosis = \frac{\sum (a_n - \mu)^4 }{n \cdot \sigma ^4} $$
Un meilleur terme pour ce qui se passe ici est de déterminer si la distribution est à queue lourde ou à queue légère. Nous pouvons comparer cela à une distribution normale.
Si vous faites une simple substitution, vous verrez que le kurtosis pour une distribution normale est 3. Et puisque nous sommes intéressés à comparer le kurtosis à la distribution normale, souvent nous utilisons l'excès de kurtosis qui soustrait simplement 3 de l'équation ci-dessus.
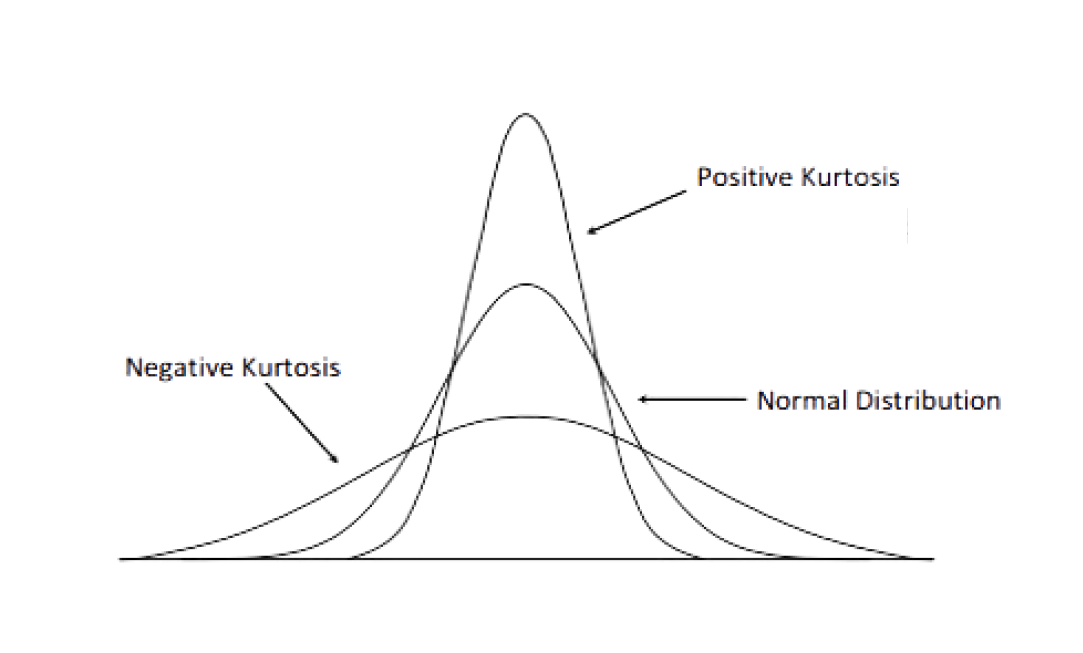 Kurtosis positif et négatif (Adapté de Analytics Vidhya)
Kurtosis positif et négatif (Adapté de Analytics Vidhya)
Cela revient essentiellement à forcer le kurtosis de notre distribution normale à être 0 pour une comparaison plus facile. Donc, si notre distribution a un kurtosis positif, cela indique une distribution à queue lourde tandis qu'un kurtosis négatif indique une distribution à queue légère. Graphiquement, cela ressemblerait à quelque chose comme l'image ci-dessus.
Ajustement de l'Échantillonnage
Un problème avec les équations que nous venons de construire est qu'elles contiennent deux termes, la moyenne de la distribution ( \mu ) et l'écart-type de la distribution ( \sigma ). Mais nous prenons un échantillon d'observations, donc nous n'avons pas les paramètres pour toute la distribution. Nous n'aurions que la moyenne de l'échantillon et l'écart-type de l'échantillon.
Pour garder cet article concentré, nous ne parlerons pas en détail des termes d'ajustement de l'échantillonnage puisque les degrés de liberté ne sont pas dans le cadre de cet article.
L'idée est d'utiliser notre moyenne d'échantillon ( \bar{x} ) et notre écart-type d'échantillon ( s ) pour estimer ces valeurs pour notre distribution. Nous devrons également ajuster notre degré de liberté dans ces équations.
Ne vous inquiétez pas si vous ne comprenez pas complètement ce concept à ce stade. Nous pouvons continuer quand même. Cela nous amène à modifier les équations dont nous avons parlé précédemment comme suit :
$$ asymétrie = \frac{\sum (a_n - \bar{x})^3 }{s^3} \cdot \frac{n}{(n-1)(n-2)} $$
$$ kurtosis = \frac{\sum (a_n - \bar{x})^4 }{s^4} \cdot \frac{n(n+1)}{(n-1)(n-2)(n-3)} - \frac{3(n-1)^2}{(n-2)(n-3)} $$
Comment Implémenter cela en Python
Enfin, terminons en voyant comment vous pouvez mesurer l'asymétrie et le kurtosis en Python avec un exemple. Au cas où vous voudriez suivre et essayer le code, vous pouvez suivre avec ce Notebook Colab où nous mesurons l'asymétrie et le kurtosis d'un ensemble de données.
Il est assez simple de l'implémenter en Python avec Scipy. Il dispose de méthodes pour mesurer facilement l'asymétrie et le kurtosis pour une distribution avec des méthodes pré-construites.
Le bloc de code ci-dessous montre comment mesurer l'asymétrie et le kurtosis pour l'ensemble de données Boston housing dataset, mais vous pourriez également l'utiliser pour vos propres distributions.
from scipy.stats import skew
from scipy.stats import kurtosis
skew(data["MEDV"].dropna())
kurtosis(data["MEDV"].dropna())
Merci d'avoir lu !
Merci d'être resté avec moi jusqu'à la fin. J'espère que vous avez beaucoup appris de cet article.
Je suis ravi de voir si cet article vous a aidé à mieux comprendre ces deux idées très importantes. Si vous avez des commentaires ou des suggestions pour moi, n'hésitez pas à me contacter sur Twitter.