


Article original : Stateful vs Stateless Architecture – Explained for Beginners
En programmation, le terme "état" fait référence à la condition d'un système, d'un composant ou d'une application à un moment donné.
Par exemple, si vous faites des achats sur amazon.com, le fait que vous soyez connecté au site ou que vous ayez des articles dans votre panier sont des exemples d'état.
L'état représente les données qui sont stockées et utilisées pour suivre l'état actuel de l'application. Comprendre et gérer l'état est crucial pour construire des applications web interactives et dynamiques.
Le concept d'« état » traverse de nombreuses frontières en architecture. Les modèles de conception (comme REST et GraphQL), les protocoles (comme HTTP et TCP), les pare-feu et les fonctions peuvent être avec ou sans état. Mais le principe sous-jacent de l'« état » traversant tous ces domaines reste le même.
Cet article expliquera ce que signifie l'état. Il expliquera également les architectures avec et sans état avec quelques analogies ainsi que les avantages et les compromis des deux.
Qu'est-ce que l'architecture avec état ?
Imaginez que vous allez dans un restaurant de pizza pour manger. Dans ce restaurant, il n'y a qu'un seul serveur, et ce serveur prend des notes détaillées sur votre numéro de table, ce que vous avez commandé, vos préférences basées sur les commandes passées, comme le type de croûte de pizza que vous aimez ou les garnitures auxquelles vous êtes allergique, et ainsi de suite.
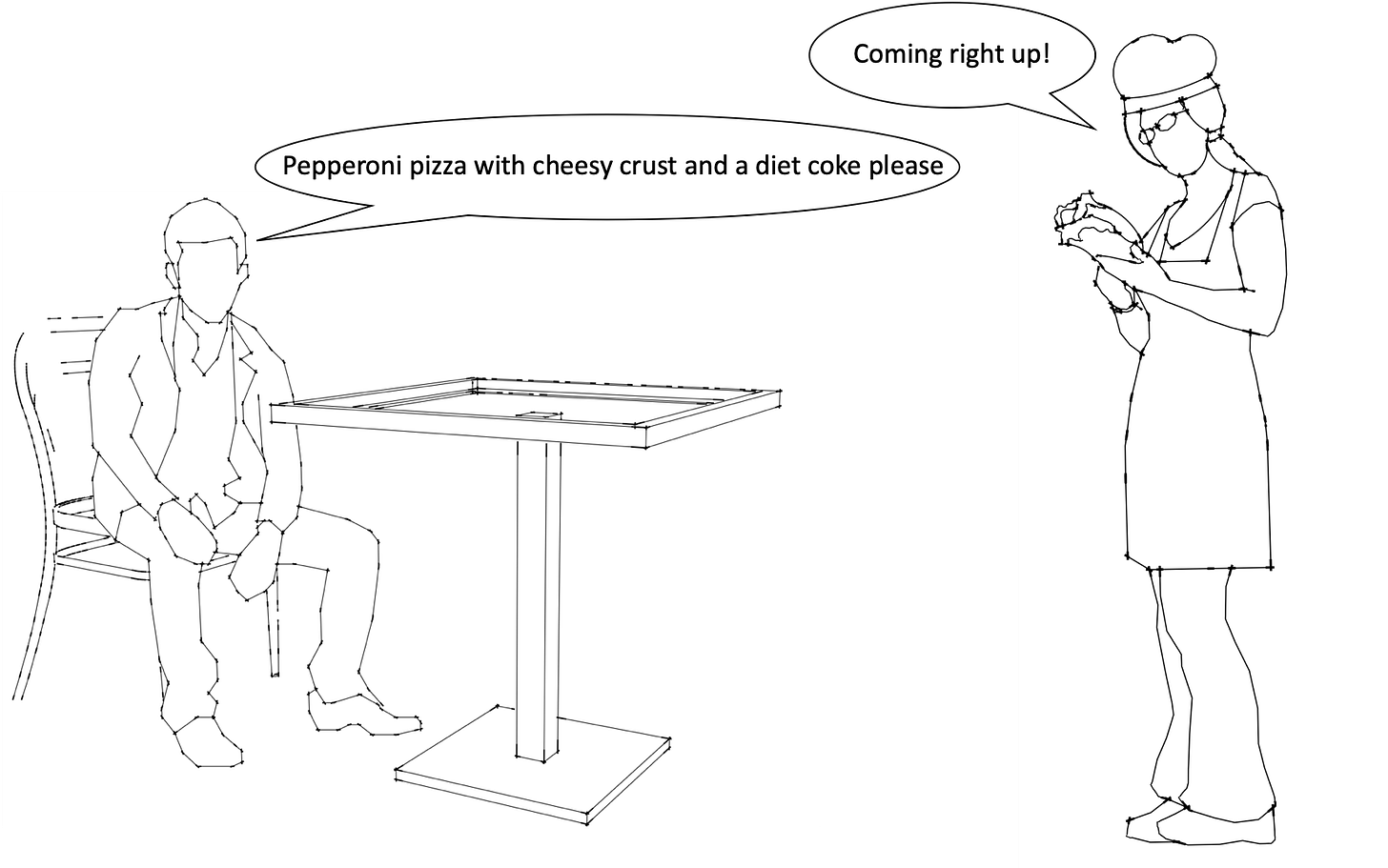
Illustration d'un serveur prenant la commande d'une personne dans un restaurant de pizza
Toutes ces informations que le serveur note dans son carnet sont l'état du client. Seul le serveur qui vous sert a accès à ces informations. Si vous souhaitez modifier votre commande ou vérifier son avancée, vous devez parler au même serveur qui a pris votre commande. Mais comme il n'y a qu'un seul serveur, ce n'est pas un problème.
Maintenant, supposons que le restaurant commence à être plus fréquenté. Votre serveur doit répondre à d'autres clients, donc plus de serveurs sont appelés à travailler. Vous souhaitez maintenant vérifier l'état de votre commande et y apporter une petite modification – une croûte simple au lieu d'une croûte fromagée. Le seul serveur disponible est différent de celui qui a initialement pris votre commande.
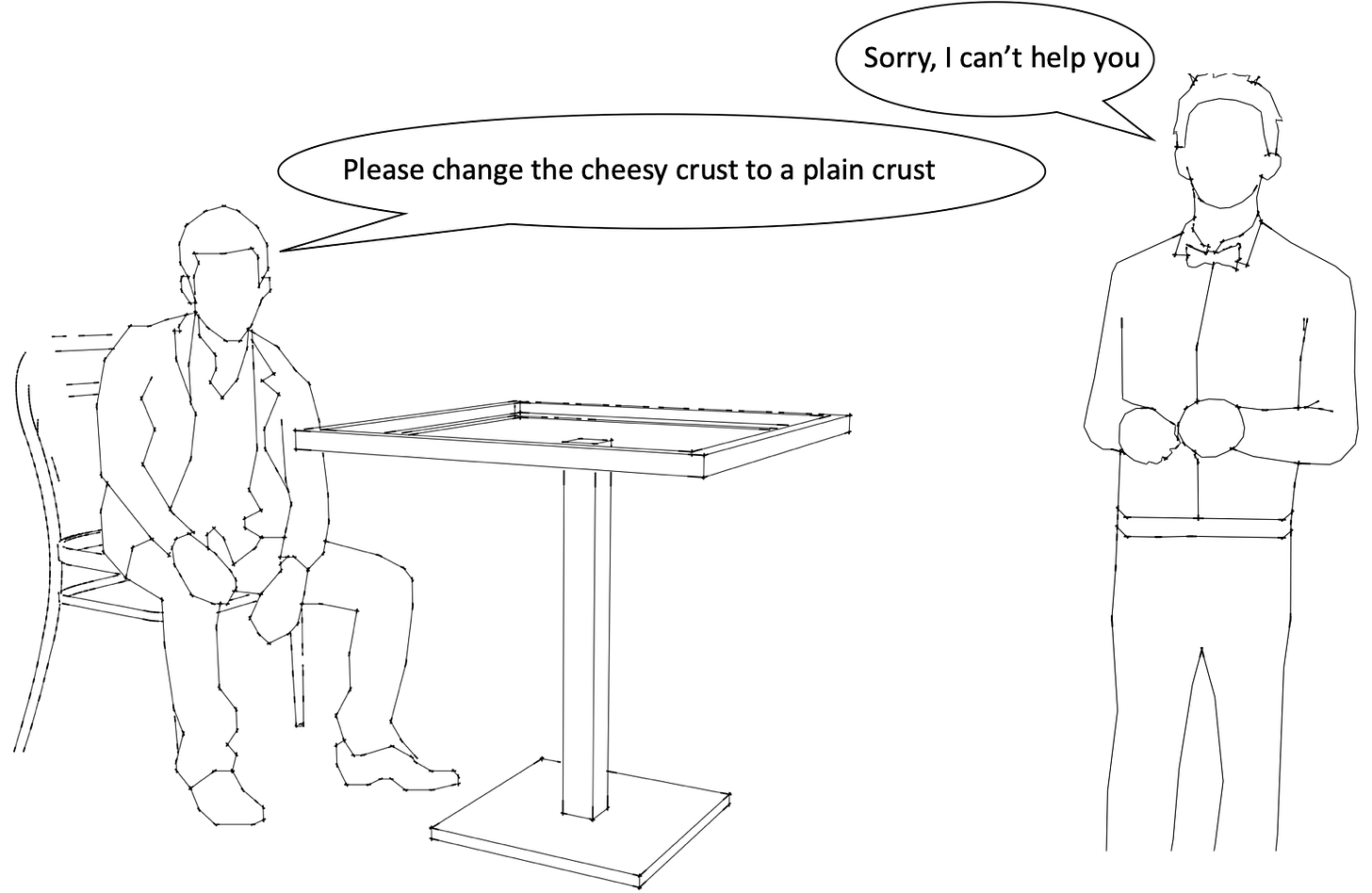
Illustration montrant un serveur différent incapable d'aider le client à modifier sa commande
Ce nouveau serveur n'a pas les détails de votre commande, c'est-à-dire votre état. Naturellement, il ne pourra pas vérifier l'état de votre commande ou y apporter des modifications. Un restaurant qui fonctionne ainsi, où seul le serveur qui a initialement pris votre commande peut vous donner des mises à jour ou y apporter des modifications, suit une conception avec état.
De même, une application avec état aura un serveur qui se souvient des données des clients (c'est-à-dire leur état). Toutes les futures requêtes seront routées vers le même serveur en utilisant un équilibreur de charge avec des sessions persistantes activées. De cette manière, le serveur est toujours conscient du client.
Le diagramme ci-dessous montre deux utilisateurs différents essayant d'accéder à un serveur web via un équilibreur de charge. Comme l'état de l'application est maintenu sur les serveurs, les utilisateurs doivent toujours être routés vers le même serveur pour chaque requête afin de préserver l'état.
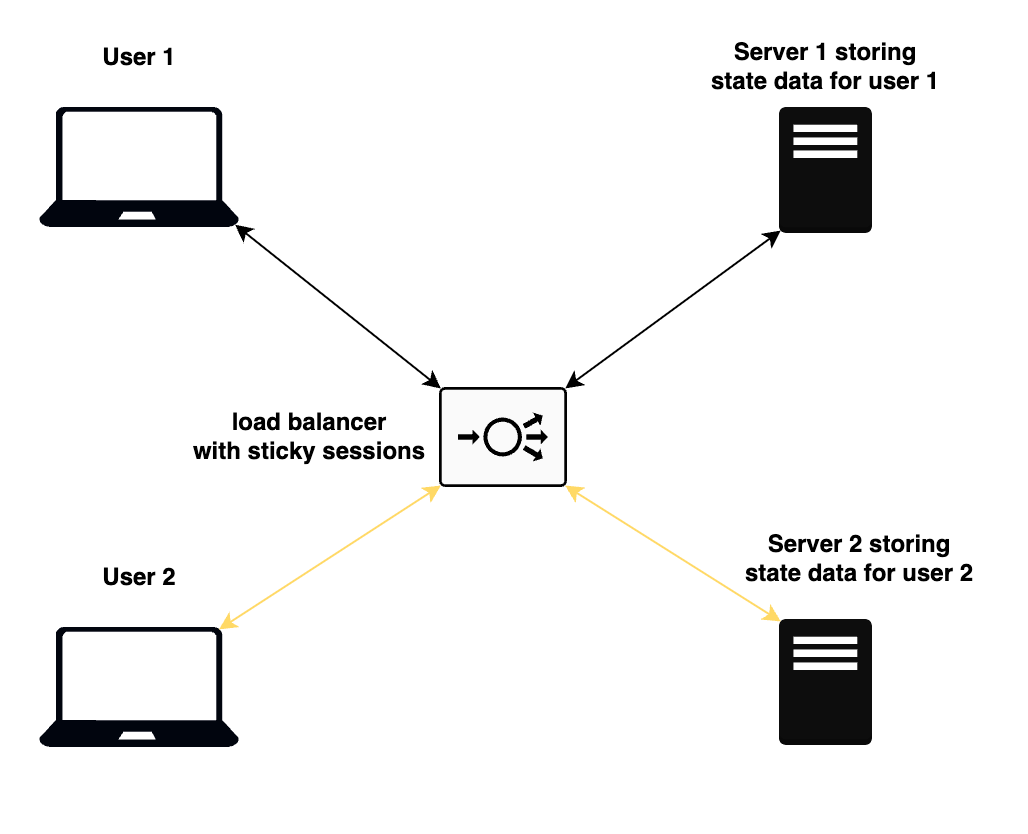
Diagramme montrant comment fonctionne une application avec état
Les sessions persistantes sont une configuration qui permet à l'équilibreur de charge de router les requêtes d'un utilisateur de manière cohérente vers le même serveur backend pour la durée de leur session. Cela contraste avec l'équilibrage de charge traditionnel, où les requêtes d'un utilisateur peuvent être dirigées vers n'importe quel serveur backend disponible selon un modèle de distribution de charge en round-robin ou autre.
Quel est le problème avec une architecture avec état ? Imaginez un restaurant géré de cette manière. Bien que cela puisse être idéal et facile à mettre en œuvre pour un petit restaurant familial avec seulement quelques clients, une telle conception n'est pas tolérante aux pannes et n'est pas scalable.
Que se passe-t-il si le serveur qui a pris la commande d'un client a une urgence et doit partir ? Toutes les informations concernant cette commande partent avec ce serveur. Cela perturbe l'expérience du client, car tout nouveau serveur amené à remplacer l'ancien n'a aucune connaissance des commandes précédentes. Il s'agit d'une conception qui n'est pas tolérante aux pannes.
De plus, devoir distribuer les requêtes de sorte que le même client ne puisse parler qu'au même serveur signifie que la charge sur les différents serveurs n'est pas également répartie. Certains serveurs seront submergés de requêtes si vous avez un client très exigeant qui modifie ou ajoute toujours des choses à sa commande. Certains des autres serveurs n'auront rien à faire et ne pourront pas intervenir pour aider. Encore une fois, il s'agit d'une conception non scalable.
De même, stocker les données d'état pour différents clients sur différents serveurs n'est pas tolérant aux pannes et n'est pas scalable. Une panne de serveur entraînera la perte des données d'état. Ainsi, si un utilisateur est connecté et sur le point de finaliser une commande importante sur Amazon.com par exemple, l'utilisateur sera forcé de se réauthentifier et le panier de l'utilisateur sera vide. Il devrait se reconnecter et remplir son panier à partir de zéro – une mauvaise expérience utilisateur.
La scalabilité sera également difficile à atteindre pendant les périodes de pointe comme le Black Friday avec une conception avec état. De nouveaux serveurs seront ajoutés au groupe de mise à l'échelle automatique, mais comme les sessions persistantes sont activées, les clients seront routés vers le même serveur, ce qui les submergera, ce qui peut entraîner une augmentation des temps de réponse - une mauvaise expérience utilisateur.
Les architectures sans état résolvent beaucoup de ces problèmes.
Qu'est-ce que l'architecture sans état ?
Le terme « sans état » est un terme déroutant, car il implique que le système est sans état. Une architecture sans état ne signifie pas, cependant, que les informations d'état ne sont pas stockées. Cela signifie simplement que les informations d'état sont stockées en dehors du serveur. Par conséquent, l'état d'être sans état ne s'applique qu'au serveur.
En revenant à l'analogie du restaurant, les serveurs dans un restaurant sans état peuvent être considérés comme ayant des mémoires parfaitement oublieuses. Ils ne reconnaissent pas les anciens clients et ne peuvent pas se rappeler ce que vous avez commandé ou comment vous aimez votre pizza. Ils prendront simplement note des commandes des clients sur un système séparé, disons un ordinateur, accessible par tous les serveurs. Ils peuvent ensuite revenir à l'ordinateur pour obtenir les détails d'une commande et y apporter des modifications si nécessaire.
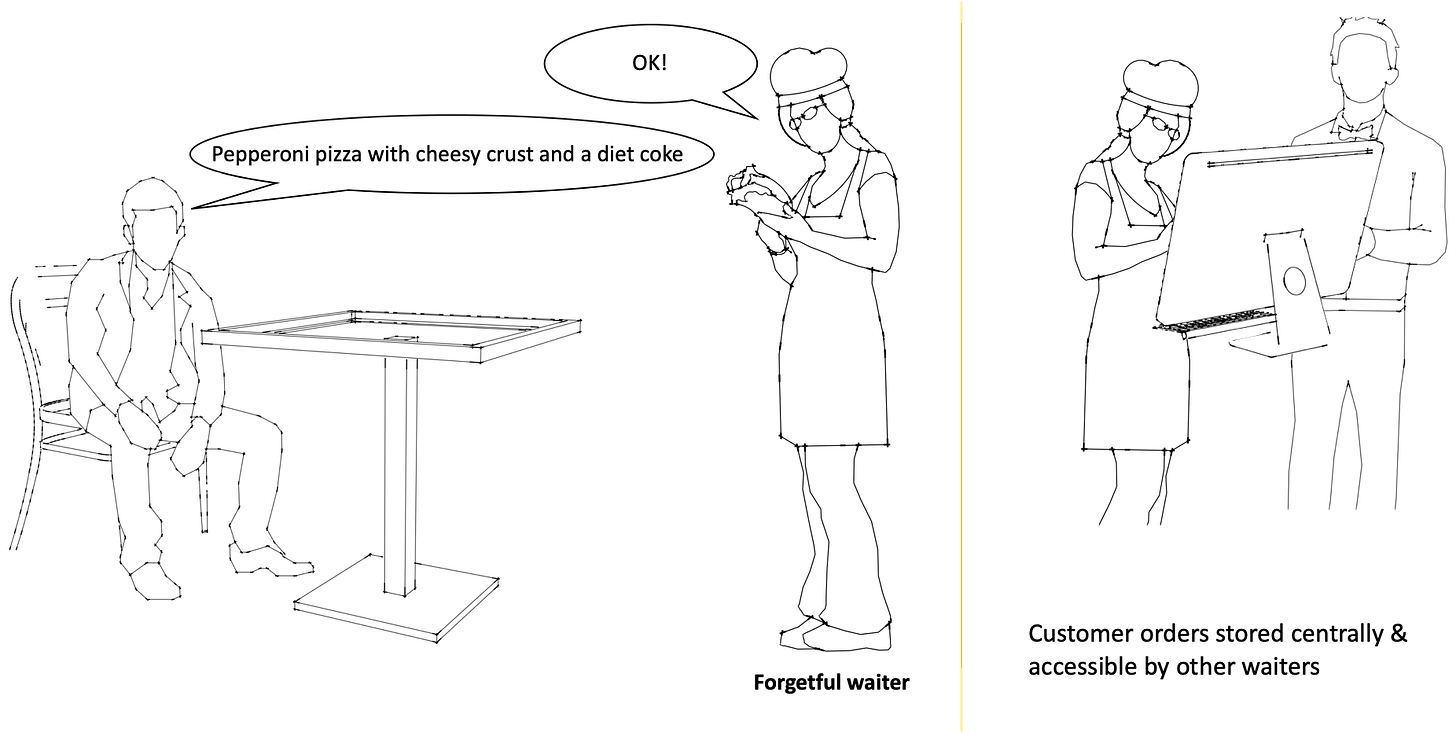
Illustration d'un serveur "oublieux" prenant une commande puis consultant l'ordinateur sur les commandes
En stockant l'« état » d'une commande client sur un système central accessible par d'autres serveurs, n'importe quel serveur peut servir n'importe quel client.
Dans une architecture sans état, les requêtes HTTP d'un client peuvent être envoyées à n'importe quel serveur.
L'état est généralement stocké dans une base de données séparée, accessible par tous les serveurs. Cela crée une architecture tolérante aux pannes et scalable, car des serveurs web peuvent être ajoutés ou supprimés selon les besoins, sans impact sur les données d'état.
La charge sera également répartie de manière égale sur tous les serveurs, car l'équilibreur de charge n'aura pas besoin d'une configuration de session persistante pour router les mêmes clients vers les mêmes serveurs.
Le diagramme ci-dessous montre deux utilisateurs différents essayant d'accéder à un serveur web via un équilibreur de charge. Comme l'état de l'application est maintenu séparément des serveurs, les utilisateurs peuvent être routés vers n'importe quel serveur, qui obtiendra ensuite les informations d'état à partir d'une base de données externe accessible par les deux serveurs.
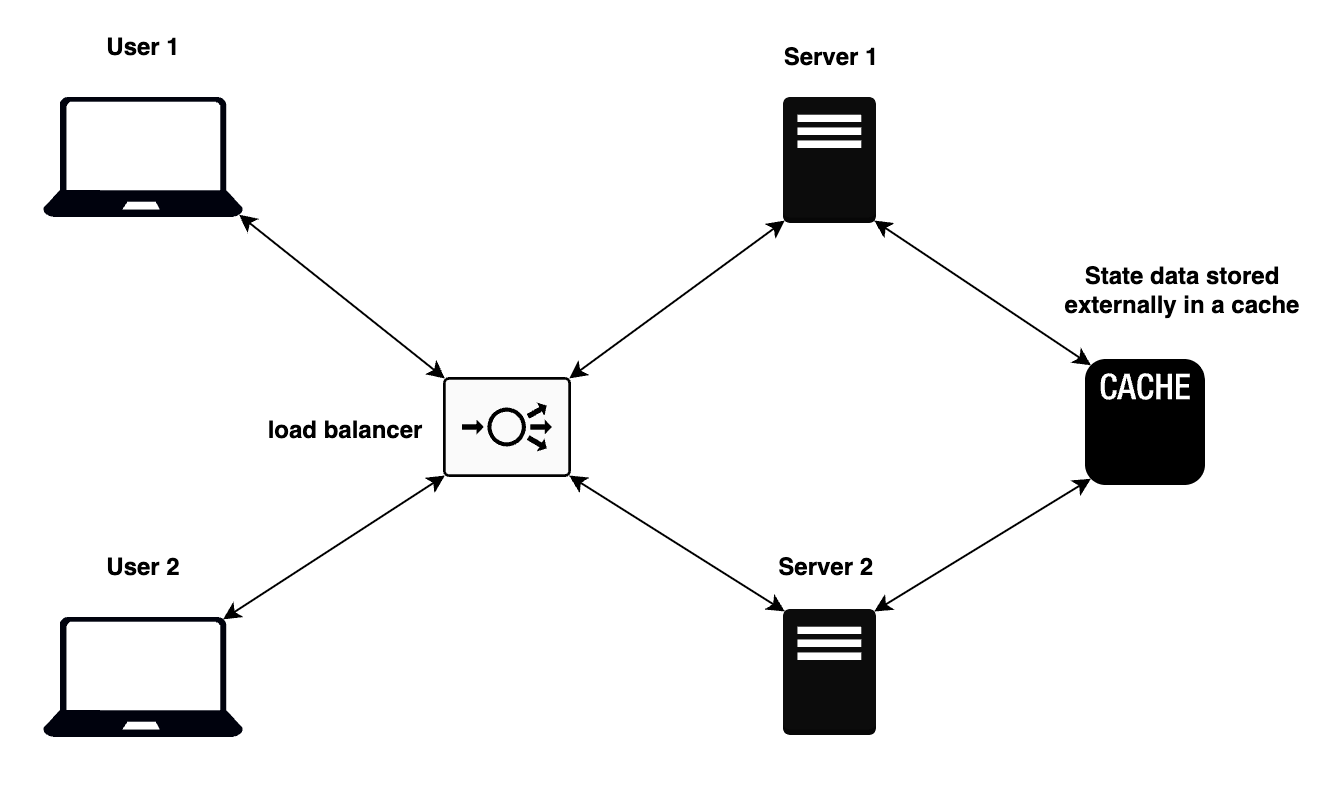
Illustration montrant un diagramme d'architecture sans état
Généralement, les données d'état sont stockées dans un cache comme Redis, un magasin de données en mémoire. Stocker les données d'état en mémoire améliore les temps de lecture et d'écriture, par rapport au stockage sur disque, comme expliqué ici.
Mettre tout ensemble
Cet article a décrit comment fonctionnent les applications web avec et sans état et les compromis des deux. Mais le principe de l'état et de l'absence d'état s'applique au-delà des applications web.
Si nous prenons les protocoles réseau comme exemple, HTTP est un protocole sans état. Cela signifie que chaque requête HTTP d'un client à un serveur est indépendante et ne porte aucune connaissance des requêtes précédentes ou de leur contexte. Le serveur traite chaque requête comme une transaction séparée et isolée, et il ne maintient pas intrinsèquement d'informations sur l'état du client entre les requêtes.
L'état est soit maintenu sur les serveurs (architecture avec état), soit dans une base de données séparée en dehors des serveurs (architecture sans état). Le protocole HTTP lui-même ne maintient pas l'état.
Contrairement à la nature sans état de HTTP, le protocole TCP est orienté connexion et avec état. Il établit une connexion entre deux appareils (généralement un client et un serveur) et maintient un canal de communication continu jusqu'à ce que la connexion soit terminée.
La même logique s'applique aux pare-feu, qui peuvent être avec ou sans état.
Dans AWS, un groupe de sécurité est un pare-feu virtuel qui contrôle le trafic entrant et sortant pour les machines virtuelles ou les instances dans un environnement cloud. Les groupes de sécurité sont avec état. Lorsque vous autorisez un flux de trafic entrant spécifique, le flux de trafic sortant correspondant est automatiquement autorisé. En d'autres termes, l'état de la connexion est suivi.
Les listes de contrôle d'accès réseau (NACL) sont utilisées pour contrôler le trafic entrant et sortant au niveau du sous-réseau dans AWS. Les NACL sont sans état. Être sans état signifie que vous devez définir explicitement des règles pour le trafic entrant et sortant.
Contrairement aux groupes de sécurité, où le trafic de réponse est automatiquement autorisé lorsque vous autorisez le trafic entrant, les NACL vous obligent à définir des règles séparées pour le trafic entrant et sortant.
Les fonctions et les modèles de conception peuvent également être avec ou sans état.
Le principe clé derrière quelque chose qui est avec état est qu'il a une mémoire parfaite ou une connaissance des appels ou requêtes précédents, tandis que quelque chose qui est sans état n'a aucune mémoire ou connaissance des appels ou requêtes précédents.
Espérons que vous avez maintenant une bonne compréhension de comment fonctionnent les applications avec et sans état et pouvez décider quelle option est la meilleure pour vos applications.