


Article original : Learn Clustering in Python – A Machine Learning Engineering Handbook
Vous souhaitez apprendre à découvrir et analyser les motifs cachés dans vos données ? Le clustering, une technique essentielle de l'apprentissage non supervisé (Unsupervised Machine Learning), est la clé pour découvrir des insights précieux qui peuvent révolutionner votre compréhension des jeux de données complexes.
Dans ce manuel complet, nous allons explorer les algorithmes et techniques de clustering incontournables, accompagnés de la théorie nécessaire pour bien comprendre le sujet. Vous verrez ensuite comment tout cela fonctionne avec de nombreux exemples, des implémentations en Python et des visualisations.
Que vous soyez débutant ou data scientist expérimenté, ce manuel est une ressource inestimable pour maîtriser les techniques de clustering. Vous pouvez également télécharger le manuel ici.
Si vous appréciez également l'apprentissage par l'écoute, voici un podcast de 15 minutes où nous discutons du clustering plus en détail. Dans cet épisode, nous explorons les concepts fondamentaux du clustering, offrant une compréhension plus approfondie de la manière dont ces techniques peuvent être appliquées aux données du monde réel.
Voici ce que nous allons couvrir :
Comment préparer les données pour l'apprentissage non supervisé
Comment utiliser t-SNE pour visualiser les clusters avec Python
À la fin de ce livre, vous serez capable de :
Comprendre les fondamentaux de l'apprentissage non supervisé – Vous saisirez les différences clés entre l'apprentissage supervisé et non supervisé, et comment le clustering s'intègre dans le domaine plus large du machine learning.
Maîtriser la terminologie importante du clustering – Vous serez familier avec les concepts essentiels tels que les points de données, les centroïdes, les métriques de distance et les méthodes d'évaluation des clusters.
Préparer les données pour le clustering – Vous apprendrez à gérer les valeurs manquantes, à normaliser les jeux de données, à supprimer les valeurs aberrantes (outliers) et à appliquer des techniques de réduction de dimensionnalité comme la PCA et t-SNE.
Acquérir une compréhension approfondie des techniques de clustering – Vous explorerez diverses méthodes de clustering, notamment K-Means, le clustering hiérarchique et DBSCAN, et comprendrez quand utiliser chaque approche.
Implémenter le clustering K-Means en Python – Vous apprendrez à appliquer l'algorithme K-Means en utilisant Python, à optimiser le nombre de clusters avec la méthode du coude (Elbow Method) et à visualiser les résultats des clusters efficacement.
Appliquer le clustering hiérarchique – Vous comprendrez le clustering agglomératif et divisif, apprendrez à construire des dendrogrammes et utiliserez Python pour implémenter le clustering hiérarchique.
Utiliser DBSCAN pour le clustering basé sur la densité – Vous maîtriserez l'approche de DBSCAN, y compris sa capacité à identifier les points de bruit et les clusters de formes arbitraires.
Visualiser les résultats du clustering – Vous serez capable de générer des visualisations significatives pour les résultats de clustering en utilisant Matplotlib, Seaborn et t-SNE pour analyser et interpréter les données efficacement.
Évaluer la performance du clustering – Vous apprendrez à évaluer la qualité des clusters en utilisant des techniques telles que le score de Silhouette, l'indice de Davies-Bouldin et l'indice de Calinski-Harabasz.
Travailler avec des jeux de données réels – Vous acquerrez une expérience pratique en appliquant des techniques de clustering à des jeux de données réels, y compris la segmentation client, la détection d'anomalies et la reconnaissance de motifs.
Élargir vos connaissances au-delà du clustering – Vous serez initié à d'autres techniques d'apprentissage non supervisé, telles que les modèles de mélange (mixture models) et la modélisation thématique (topic modeling), élargissant ainsi votre expertise en machine learning.
À la fin de ce manuel, vous disposerez d'une base solide en clustering et en apprentissage non supervisé, vous permettant d'analyser des jeux de données complexes et de découvrir des motifs cachés avec confiance !
Prérequis
Avant de plonger dans ce manuel sur le clustering et l'apprentissage non supervisé, vous devriez avoir une solide compréhension des concepts de machine learning, des techniques de prétraitement des données et des compétences de base en programmation Python. Ces prérequis vous aideront à saisir les fondements théoriques et les implémentations pratiques abordés tout au long de l'ouvrage.
Avant tout, il est important d'être familier avec les fondamentaux du machine learning. Vous devez comprendre la différence entre l'apprentissage supervisé et non supervisé, ainsi que les principes de base des techniques de clustering.
Des concepts tels que les points de données, les caractéristiques (features), les métriques de distance (Euclidienne, Manhattan) et les mesures de similarité jouent un rôle important dans les algorithmes de clustering. Une compréhension de base des probabilités, des statistiques et de l'algèbre linéaire sera également bénéfique, car ces concepts mathématiques forment la base de nombreux modèles de machine learning.
Ensuite, les techniques de prétraitement des données sont essentielles pour travailler avec des jeux de données réels. Étant donné que les algorithmes de clustering dépendent fortement de données bien structurées, vous devez savoir comment gérer les valeurs manquantes, normaliser ou standardiser les caractéristiques numériques et supprimer les valeurs aberrantes qui pourraient fausser les résultats du clustering.
Des techniques comme la mise à l'échelle des caractéristiques (normalisation Min-Max, standardisation) et la réduction de dimensionnalité (PCA, t-SNE) peuvent améliorer la précision et l'efficacité du clustering, facilitant ainsi l'interprétation des résultats.
Enfin, une maîtrise de la programmation Python et des bibliothèques de data science est requise pour suivre les implémentations pratiques de ce manuel. Vous devriez être à l'aise avec des bibliothèques comme NumPy et Pandas pour la manipulation des données, Matplotlib et Seaborn pour la visualisation, et Scikit-learn pour l'implémentation des algorithmes de machine learning.
Comme vous appliquerez des techniques de clustering telles que K-Means, le clustering hiérarchique et DBSCAN, la familiarité avec l'écriture et l'exécution de scripts Python via des Jupyter Notebooks, ainsi que l'interprétation des sorties de clustering, enrichira votre expérience d'apprentissage.
En bâtissant une base solide dans ces domaines, vous serez bien préparé pour exploiter la puissance du clustering et obtenir des insights plus profonds de vos données.
Introduction à l'apprentissage non supervisé
L'apprentissage non supervisé est une technique puissante en machine learning. Il nous permet de découvrir des motifs et des structures cachés au sein des données sans aucune étiquette prédéfinie ni variable cible. Contrairement à l'apprentissage supervisé, qui repose sur des données étiquetées pour l'entraînement, l'apprentissage non supervisé nous permet d'explorer et de comprendre la structure intrinsèque des jeux de données non étiquetés.
Une application clé de l'apprentissage non supervisé est le clustering. Le clustering est le processus de regroupement de points de données similaires en fonction de leurs caractéristiques intrinsèques et de leurs similitudes. En identifiant des motifs et des relations au sein des jeux de données, le clustering nous aide à obtenir des insights précieux et à donner du sens à des données complexes.
Le clustering trouve son importance dans divers domaines, notamment la segmentation client, la détection d'anomalies, la reconnaissance d'images et les systèmes de recommandation. Il nous permet d'identifier des groupes distincts au sein des données, de classer les données dans des catégories significatives et de comprendre les tendances sous-jacentes qui animent les jeux de données.
Dans les sections suivantes, nous approfondirons différents algorithmes de clustering, tels que K-Means, le clustering hiérarchique et DBSCAN, en explorant leurs théories, leurs implémentations et leurs visualisations. À la fin de ce manuel, vous aurez une compréhension complète de l'apprentissage non supervisé et serez équipé des connaissances et des compétences nécessaires pour appliquer diverses techniques de clustering à vos propres tâches d'analyse de données.
Rappelez-vous, le clustering n'est qu'un aspect de l'apprentissage non supervisé, qui offre une gamme d'autres techniques et applications. Alors, plongeons et découvrons le monde passionnant de l'apprentissage non supervisé et le pouvoir qu'il détient pour extraire des insights à partir de données non étiquetées.
Apprentissage supervisé vs non supervisé
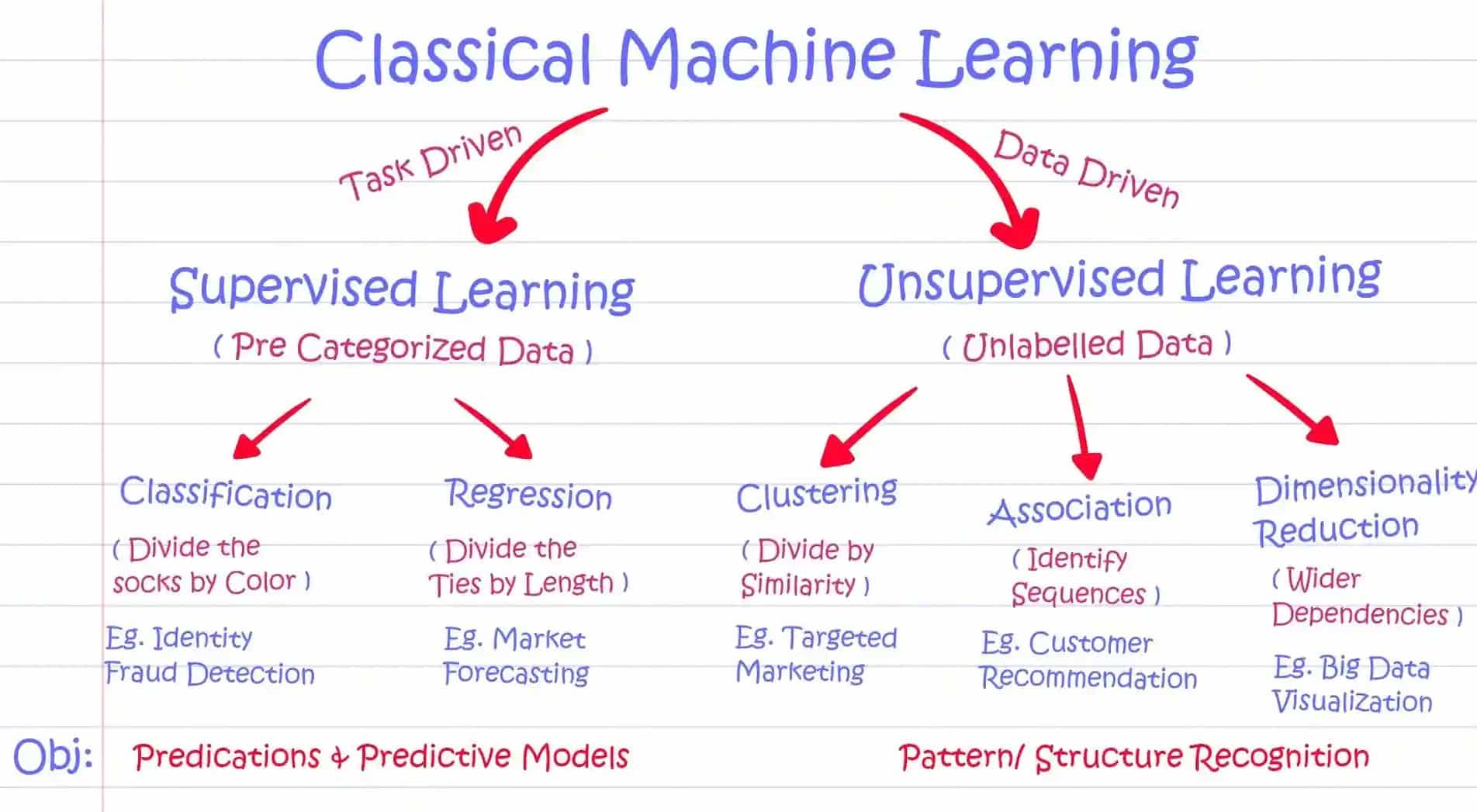
En machine learning, il existe deux approches principales : l'apprentissage supervisé et l'apprentissage non supervisé. Comprendre les différences entre ces deux approches est crucial pour sélectionner la bonne technique pour vos besoins d'analyse de données.
L'apprentissage supervisé, comme son nom l'indique, implique l'entraînement d'un modèle de machine learning sur des données étiquetées. Dans cette approche, les données d'entrée consistent en des caractéristiques (également appelées attributs ou variables) et des valeurs cibles ou étiquettes correspondantes. Le modèle apprend de ces données étiquetées et effectue des prédictions ou des classifications basées sur de nouvelles données non vues.
D'un autre côté, l'apprentissage non supervisé consiste à explorer des données non étiquetées. Avec l'apprentissage non supervisé, les données ne sont pas accompagnées d'étiquettes ou de valeurs cibles prédéfinies. Au lieu de cela, l'algorithme recherche par lui-même des motifs, des structures et des relations au sein des données. L'objectif est de découvrir des insights cachés et d'acquérir une compréhension plus profonde de la structure sous-jacente des données.
L'un des principaux avantages de l'apprentissage non supervisé est sa capacité à découvrir des motifs et des relations auparavant inconnus. Sans les contraintes des données étiquetées, les algorithmes non supervisés peuvent révéler des insights précieux qui pourraient ne pas être apparents via d'autres méthodes analytiques. Cela rend l'apprentissage non supervisé particulièrement utile dans l'analyse exploratoire des données, la détection d'anomalies et le clustering.
Dans l'apprentissage supervisé, la variable cible sert de guide pour le processus d'apprentissage, permettant au modèle de faire des prédictions ou des classifications précises. Mais cette dépendance aux données étiquetées peut également limiter les capacités du modèle, car il peut éprouver des difficultés avec des motifs non représentés ou nouveaux qui n'étaient pas présents dans les données d'entraînement.
En revanche, l'apprentissage non supervisé permet une approche plus flexible et adaptable. Il peut capturer la structure et les relations sous-jacentes au sein des données, même lorsque des étiquettes explicites ne sont pas disponibles. En tirant parti des algorithmes de clustering et des techniques de réduction de dimensionnalité, l'apprentissage non supervisé offre des outils puissants pour démêler des jeux de données complexes.
En résumé, l'apprentissage supervisé est bien adapté aux tâches où des données étiquetées sont disponibles et où l'objectif est d'effectuer des prédictions ou des classifications précises. L'apprentissage non supervisé, quant à lui, est précieux lors de l'exploration de données pour des motifs et des relations cachés, en particulier dans les cas où les données étiquetées sont rares ou inexistantes.
En comprenant les différences entre ces deux approches, vous pouvez choisir efficacement la bonne technique pour libérer tout le potentiel de vos efforts d'analyse de données.
Terminologie importante
Pour bien comprendre l'apprentissage non supervisé et le clustering, il est crucial de se familiariser avec les termes clés associés à ces concepts. Voici quelques terminologies importantes que vous devriez connaître :
1. Point de données (Data Point)
Un point de données fait référence à une observation individuelle ou à une instance au sein d'un jeu de données. Chaque point de données contient diverses caractéristiques ou attributs qui décrivent un objet ou un événement spécifique.
2. Nombre de clusters
Le nombre de clusters représente le nombre souhaité ou estimé de groupes distincts dans lesquels les données seront partitionnées pendant le processus de clustering. C'est un paramètre essentiel qui détermine la structure des clusters résultants.
3. Algorithme non supervisé
Un algorithme non supervisé est une procédure mathématique utilisée pour identifier des motifs ou des relations dans les données sans avoir besoin d'exemples étiquetés ou pré-catégorisés. Ces algorithmes explorent la structure et la complexité inhérentes aux jeux de données pour découvrir des insights cachés.
Comprendre et utiliser ces terminologies posera une base solide pour votre parcours dans l'apprentissage non supervisé et le clustering. Dans les sections suivantes, nous approfondirons les aspects pratiques et l'implémentation des techniques de clustering en Python.
Comment préparer les données pour l'apprentissage non supervisé
Avant d'implémenter des algorithmes d'apprentissage non supervisé, il est crucial de s'assurer que les données sont correctement préparées. Cela implique de prendre certaines mesures pour optimiser les données d'entrée, les rendant adaptées à l'analyse par des techniques de clustering. Voici des considérations importantes lors de la préparation des données pour l'apprentissage non supervisé :
Normalisation des données
Un aspect clé de la préparation des données est la normalisation, où toutes les caractéristiques sont mises à l'échelle sur une plage cohérente. Cela est nécessaire car les variables du jeu de données peuvent avoir des unités ou des échelles différentes.
La normalisation aide à éviter les biais envers une caractéristique particulière pendant le processus de clustering. Les méthodes courantes de normalisation incluent la mise à l'échelle min-max et la standardisation.
Gestion des valeurs manquantes
Le traitement des valeurs manquantes est une autre étape critique. Il est important d'identifier et de traiter toutes les valeurs manquantes dans le jeu de données avant d'appliquer des algorithmes de clustering.
Il existe diverses techniques pour gérer les valeurs manquantes, telles que l'imputation, où les valeurs manquantes sont remplacées par des valeurs estimées basées sur des méthodes statistiques ou des algorithmes.
Détection et traitement des valeurs aberrantes (Outliers)
Les valeurs aberrantes peuvent impacter significativement les résultats du clustering, car elles peuvent influencer la détermination des limites des clusters. Il est donc essentiel de détecter et de traiter les valeurs aberrantes de manière appropriée. Cela peut impliquer des techniques comme l'analyse du Z-score ou de l'écart interquartile (IQR) pour identifier et traiter ces points.
Réduction de dimensionnalité
Dans certains cas, le jeu de données peut avoir une dimensionnalité élevée, ce qui signifie qu'il contient un grand nombre de caractéristiques. Les données de haute dimension peuvent être difficiles à visualiser et à analyser efficacement. Des techniques de réduction de dimensionnalité, telles que l'Analyse en Composantes Principales (PCA), peuvent être employées pour réduire le nombre de caractéristiques tout en conservant les aspects les plus informatifs des données.
En préparant soigneusement les données, en normalisant les variables, en gérant les valeurs manquantes, en traitant les valeurs aberrantes et en réduisant la dimensionnalité si nécessaire, vous pouvez optimiser la qualité des données d'entrée pour les algorithmes d'apprentissage non supervisé. Cela garantit des résultats de clustering précis et significatifs, menant à des insights et des motifs précieux au sein des données.
N'oubliez pas que la préparation des données est une étape cruciale du processus d'apprentissage non supervisé, posant les bases d'une analyse de clustering réussie.

Le clustering expliqué
Le clustering est une technique fondamentale de l'apprentissage non supervisé qui joue un rôle crucial dans la découverte de motifs cachés au sein des données. Il consiste à regrouper des points de données en fonction de leur similarité, nous permettant d'identifier des sous-ensembles ou des clusters distincts au sein d'un jeu de données. En analysant la structure de ces clusters, nous pouvons obtenir des insights précieux et prendre des décisions basées sur les données.
Concept du clustering
À la base, le clustering vise à trouver des similitudes ou des relations entre les points de données sans aucune étiquette prédéfinie ni variable cible. L'objectif est de maximiser la similarité au sein de chaque cluster tout en maximisant la dissimilarité entre les différents clusters. Ce processus nous permet d'identifier des motifs et des structures inhérentes aux données.
Les clusters peuvent être définis par divers facteurs tels que la distance, la connectivité ou la densité. Chaque point de données au sein d'un cluster partage plus de similitudes avec les autres points du même cluster qu'avec les points des autres clusters. Ce regroupement nous permet de segmenter les données, ce qui peut être extrêmement utile dans divers domaines tels que la segmentation client, la détection d'anomalies et la reconnaissance d'images.
Types d'algorithmes de clustering
Il existe plusieurs algorithmes de clustering, chacun ayant sa propre approche pour partitionner les données en clusters. Parmi les plus populaires, on trouve le clustering K-Means, le clustering hiérarchique et DBSCAN (Density-Based Spatial Clustering of Applications with Noise).
1. Clustering K-Means
Le clustering K-Means est un algorithme largement utilisé qui vise à partitionner les données en K clusters distincts. Il assigne de manière itérative chaque point de données au centroïde de cluster le plus proche, puis recalcule les centroïdes. Ce processus se poursuit jusqu'à la convergence, aboutissant à des clusters bien définis.
2. Clustering hiérarchique
Le clustering hiérarchique crée une hiérarchie de clusters en les divisant ou en les fusionnant de manière récursive en fonction de certains critères. Cette approche peut être représentée sous forme de dendrogramme, qui fournit des informations précieuses sur la hiérarchie et les relations entre les clusters.
3. Clustering DBSCAN
DBSCAN est un algorithme basé sur la densité qui regroupe les points de données en fonction de leur densité et de leur connectivité. Il est particulièrement efficace pour identifier des clusters de formes arbitraires et gérer les données bruitées.
Ce ne sont là que quelques exemples d'algorithmes de clustering, chacun ayant ses propres forces et sa pertinence pour des scénarios spécifiques. Il est important de sélectionner l'algorithme le plus approprié en fonction des caractéristiques des données et du domaine du problème.
Dans les sections suivantes, nous approfondirons les théories, l'implémentation et la visualisation de ces algorithmes de clustering pour vous fournir une compréhension complète de leur fonctionnement et de leur utilisation.
Rappelez-vous, le clustering est une technique puissante qui nous permet de débloquer les structures cachées au sein de nos données, menant à des insights précieux et à une prise de décision éclairée. Plongeons dans le monde du clustering et découvrons le potentiel qu'il recèle.

Clustering K-Means
Le clustering K-Means est un algorithme d'apprentissage non supervisé populaire utilisé pour partitionner des points de données en groupes distincts basés sur la similarité. Dans cette section, nous allons explorer la théorie derrière le clustering K-Means et son implémentation en Python à l'aide de la bibliothèque scikit-learn.
En Data Science et Data Analytics, nous voulons souvent catégoriser des observations en un ensemble de segments ou clusters à des fins différentes. Par exemple, une entreprise peut vouloir regrouper ses clients en 3 à 5 groupes en fonction de leur historique de transactions ou de la fréquence de leurs achats. Il s'agit généralement d'une approche d'apprentissage non supervisé où les étiquettes (groupes/segments/clusters) sont inconnues.
L'une des approches de clustering les plus populaires pour regrouper des observations est l'algorithme non supervisé K-Means. Voici les conditions pour le clustering K-Means :
le nombre de clusters doit être spécifié à l'avance : K
chaque observation doit appartenir à au moins une classe
chaque observation doit appartenir à une seule classe (les classes ne doivent pas se chevaucher)
aucune observation ne doit appartenir à plus d'une classe
L'idée derrière K-Means est de minimiser la variation intra-cluster et de maximiser la variation inter-cluster. Ainsi, K-means partitionne les observations en K clusters de telle sorte que la variation intra-cluster totale, sommée sur les K clusters, soit aussi petite que possible.
La motivation est de regrouper les observations de sorte que celles d'un même groupe soient aussi similaires que possible, tandis que les observations de groupes différents soient aussi différentes que possible.
Mathématiquement, la variation intra-cluster est définie en fonction du choix de la mesure de distance que vous pouvez choisir vous-même. Par exemple, vous pouvez utiliser la distance euclidienne, la distance de Manhattan, etc.
Le clustering K-means est optimal lorsque la variation intra-cluster est la plus faible. La variation intra-cluster d'un cluster C_k est une mesure W(C_k) de la quantité par laquelle les observations d'un cluster diffèrent les unes des autres. Le problème d'optimisation suivant doit donc être résolu :
$$\min_{C_1, \dots, C_K} \sum_{k=1}^{K} W(C_k)$$
Où la variation intra-cluster utilisant la distance euclidienne peut être exprimée comme suit :
$$W(C_k) = \frac{1}{|C_k|} \sum_{i,i' \in C_k} \sum_{j=1}^{p} (x_{ij} - x_{i'j})^2$$
Le nombre d'observations dans le k-ième cluster est noté |C_k |. Ainsi, le problème d'optimisation pour K-means peut être décrit comme suit :
$$\min_{C_1, \dots, C_K} \left\{ \sum_{k=1}^{K} \frac{1}{|C_k|} \sum_{i,i' \in C_k} \sum_{j=1}^{p} (x_{ij} - x_{i'j})^2 \right\}$$
Algorithme K-Means
Le pseudocode de l'algorithme K-means peut être décrit comme suit :

K-Means est une approche non déterministe et son caractère aléatoire intervient à l'étape 1, où toutes les observations sont assignées aléatoirement à l'une des K classes.
Dans la deuxième étape, pour chaque cluster, les centroïdes de cluster sont calculés en calculant les valeurs moyennes de tous les points de données du cluster. Le centroïde d'un k-ième cluster est un vecteur de longueur p contenant les moyennes de toutes les variables pour les observations du k-ième cluster, où p est le nombre de variables.
Ensuite, à l'étape suivante, les clusters d'observations sont mis à jour, de sorte que chaque observation est assignée au cluster dont le centroïde est le plus proche, en minimisant itérativement la somme totale des carrés intra-cluster (within sum of squares). C'est-à-dire que nous itérons les étapes 2 et 3 jusqu'à ce que les centroïdes de cluster ne changent plus ou que le nombre maximum d'itérations soit atteint.
Clustering K-Means : Implémentation en Python
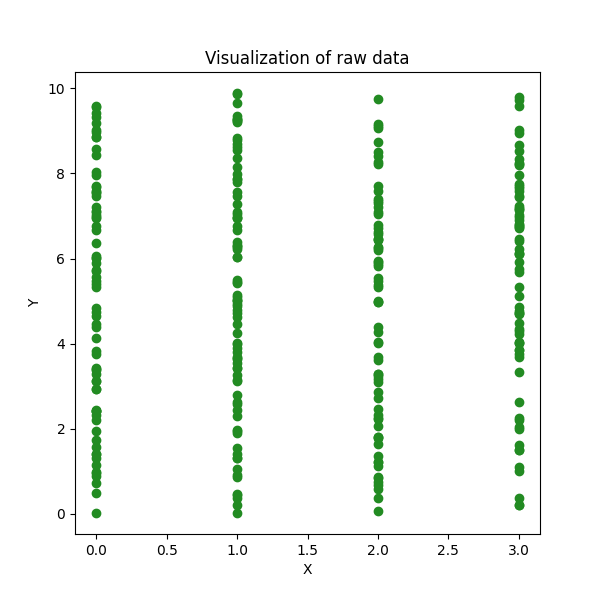
Regardons un exemple où nous visons à classer des observations en 4 classes. Les données brutes ressemblent à ceci :
# Import des bibliothèques nécessaires
# KMeans est l'algorithme de clustering de scikit-learn
from sklearn.cluster import KMeans
# Le module metrics est utilisé pour évaluer la performance du clustering
from sklearn import metrics
# NumPy est utilisé pour les calculs numériques et les opérations sur tableaux
import numpy as np
# Pandas est utilisé pour manipuler les données dans un format DataFrame structuré
import pandas as pd
# Génération de données synthétiques pour le clustering K-Means
# Création d'un tableau 100x2 avec des entiers aléatoires de 0 à 9
df = np.random.randint(0, 10, size=[100, 2])
# Génération d'un tableau 300x1 avec des entiers aléatoires de 0 à 3
X1 = np.random.randint(0, 4, size=[300, 1])
# Génération d'un tableau 300x1 avec des nombres flottants aléatoires de 0 à 10
X2 = np.random.uniform(0, 10, size=[300, 1])
# Combinaison de X1 et X2 le long du deuxième axe pour former un dataset avec deux caractéristiques
df = np.append(X1, X2, axis=1)
# Application de l'algorithme K-Means sur le dataset généré
# Appel de la fonction KMeans_Algorithm avec K=4 clusters
Clustered_df = KMeans_Algorithm(df=df, K=4)
# Conversion des données clusterisées en un DataFrame Pandas
df = pd.DataFrame(Clustered_df)
# Fonction pour effectuer le clustering K-Means
def KMeans_Algorithm(df, K):
"""
Effectue le clustering K-Means sur le jeu de données fourni.
Paramètres:
df (array-like): Dataset d'entrée à clusteriser.
K (int): Nombre de clusters.
Retourne:
df (DataFrame): Le dataset original avec une colonne supplémentaire pour les étiquettes de cluster.
"""
# Initialisation du modèle K-Means avec les paramètres spécifiés
# Définition du nombre de clusters à K
# Utilisation de l'initialisation k-means++ pour améliorer la convergence
# Définition du nombre maximum d'itérations à 300
# Définition d'une graine aléatoire fixe pour la reproductibilité
KMeans_model = KMeans(
n_clusters=K,
init='k-means++',
max_iter=300,
random_state=2021
)
# Entraînement du modèle K-Means sur le jeu de données
KMeans_model.fit(df)
# Extraction des centroïdes de cluster (points centraux de chaque cluster)
centroids = KMeans_model.cluster_centers_
# Conversion des centroïdes en un DataFrame avec les noms de colonnes "X" et "Y"
centroids_df = pd.DataFrame(centroids, columns=["X", "Y"])
# Obtention des étiquettes de cluster assignées à chaque point de données
labels = KMeans_model.labels_
# Conversion des données d'entrée en DataFrame Pandas (si ce n'est pas déjà fait)
df = pd.DataFrame(df)
# Ajout d'une nouvelle colonne pour stocker les étiquettes de cluster assignées
df["labels"] = labels
# Retourne le DataFrame mis à jour avec les étiquettes de cluster
return df

Ce script est conçu pour générer des données synthétiques, appliquer le clustering K-Means et assigner des étiquettes de cluster à chaque point de données. L'algorithme de clustering K-Means est une méthode d'apprentissage automatique non supervisée qui regroupe des points de données similaires en clusters en fonction de leur proximité dans l'espace des caractéristiques. Voici une décomposition étape par étape du fonctionnement du script.
La première étape consiste à importer les bibliothèques nécessaires. Le script utilise KMeans de sklearn.cluster pour implémenter l'algorithme. Le module metrics de sklearn est inclus, bien qu'il ne soit pas utilisé dans ce script, il peut être utile pour évaluer la qualité du clustering. NumPy est utilisé pour les calculs numériques et les opérations sur tableaux, tandis que Pandas est utilisé pour structurer les données dans un DataFrame pour une manipulation plus facile.
Ensuite, le script génère des données numériques synthétiques. Un tableau NumPy df est créé avec des dimensions 100x2 contenant des entiers aléatoires entre 0 et 9. Deux tableaux supplémentaires, X1 et X2, sont générés séparément. X1 contient 300x1 entiers aléatoires allant de 0 à 3, et X2 contient 300x1 nombres flottants aléatoires entre 0 et 10. Ces tableaux sont ensuite combinés pour former un jeu de données avec deux caractéristiques, prêt pour le clustering.
Une fois les données synthétiques préparées, le script applique l'algorithme K-Means. La fonction KMeans_Algorithm est appelée avec K=4, ce qui signifie que l'algorithme tentera de regrouper les données en quatre clusters. La fonction renvoie le jeu de données clusterisé, qui est ensuite converti en un DataFrame Pandas.
La fonction KMeans_Algorithm prend deux paramètres : le jeu de données df et le nombre de clusters K. À l'intérieur de cette fonction, le modèle K-Means est initialisé à l'aide de KMeans(). Le nombre de clusters est fixé à K, et le paramètre init='k-means++' assure une meilleure initialisation pour une convergence plus rapide. L'argument max_iter=300 fixe une limite au nombre d'itérations, évitant un temps de calcul excessif. Le random_state=2021 garantit que les résultats sont reproductibles.
Après l'initialisation, le modèle K-Means est ajusté au jeu de données à l'aide de KMeans_model.fit(df). Cette étape traite le jeu de données, identifie les centres de clusters et regroupe les points de données en conséquence. Une fois l'entraînement terminé, les centroïdes des clusters sont extraits à l'aide de KMeans_model.cluster_centers_, et ceux-ci sont stockés dans un DataFrame Pandas avec les noms de colonnes "X" et "Y" pour une interprétation plus facile.
Chaque point de données se voit attribuer une étiquette de cluster, qui peut être récupérée via KMeans_model.labels_. Le script s'assure ensuite que le jeu de données est stocké sous forme de DataFrame Pandas, et une nouvelle colonne "labels" est ajoutée pour stocker les étiquettes de cluster assignées. Enfin, le jeu de données mis à jour, contenant maintenant les caractéristiques originales ainsi que les assignations de clusters, est renvoyé.
La sortie de ce script est un DataFrame Pandas contenant trois colonnes : deux colonnes de caractéristiques numériques représentant les points de données générés et une colonne "labels" qui indique l'assignation de cluster pour chaque point. Par exemple, une vue simplifiée de la sortie pourrait montrer une ligne où un point avec les valeurs [2.0, 7.4] est assigné au cluster 0, tandis qu'un autre avec [1.0, 3.2] appartient au cluster 1.
Ce script réussit à créer un jeu de données structuré, à clusteriser les données en quatre groupes distincts et à assigner des étiquettes de cluster significatives à chaque point. Les résultats peuvent être analysés plus en détail par des techniques de visualisation telles que des graphiques de dispersion pour comprendre la distribution du clustering. Des améliorations futures pourraient inclure l'utilisation de métriques comme le score de Silhouette pour évaluer la qualité du clustering ou l'expérimentation de différents nombres de clusters pour trouver le regroupement le plus optimal.
Clustering K-Means : Visualisation
L'un des principaux avantages de K-Means est sa simplicité et son efficacité dans la gestion de grands jeux de données. C'est un algorithme de clustering largement utilisé dans divers domaines, notamment la segmentation client, la compression d'images, la détection d'anomalies et la reconnaissance de motifs.
Malgré sa simplicité, K-Means est très efficace pour découvrir les structures de groupe inhérentes aux données, ce qui en fait un outil essentiel de l'apprentissage non supervisé. Mais comme tout algorithme, il a ses limites, telles que la sensibilité au choix initial des centroïdes et la difficulté à détecter des clusters non sphériques. Comprendre ces forces et faiblesses aidera à prendre des décisions éclairées lors de l'application de K-Means à des jeux de données réels.
Dans cette section, nous explorerons comment implémenter le clustering K-Means en Python et visualiser les résultats. Grâce à une implémentation de code étape par étape, vous verrez comment les points de données sont regroupés en clusters et comment l'algorithme affine itérativement ses assignations de clusters. Nous discuterons également des meilleures pratiques pour sélectionner le nombre optimal de clusters et comment évaluer la qualité du clustering.
Comprendre l'algorithme K-Means
Avant de passer à l'implémentation, comprenons brièvement le fonctionnement de l'algorithme K-Means. L'algorithme suit ces étapes :
Étape 1 : Initialisation – Sélectionner aléatoirement K centroïdes, où K représente le nombre souhaité de clusters.
Étape 2 : Assignation – Assigner chaque point de données au centroïde le plus proche en fonction de la distance euclidienne.
Étape 3 : Mise à jour – Recalculer les centroïdes en prenant la moyenne de tous les points de données assignés à chaque cluster.
Étape 4 : Répétition – Répéter les étapes 2 et 3 jusqu'à ce que les critères de convergence soient remplis (par exemple, mouvement minimal des centroïdes).
fig, ax = plt.subplots(figsize=(6, 6))
# pour les observations avec chaque type d'étiquettes des colonnes 1 et 2
plt.scatter(df[df["labels"] == 0][0], df[df["labels"] == 0][1],
c='black', label='cluster 1')
plt.scatter(df[df["labels"] == 1][0], df[df["labels"] == 1][1],
c='green', label='cluster 2')
plt.scatter(df[df["labels"] == 2][0], df[df["labels"] == 2][1],
c='red', label='cluster 3')
plt.scatter(df[df["labels"] == 3][0], df[df["labels"] == 3][1],
c='y', label='cluster 4')
plt.scatter(centroids[:, 0], centroids[:, 1], marker='*', s=300, c='black', label='centroid')
plt.legend()
plt.xlim([-2, 6])
plt.ylim([0, 10])
plt.xlabel('X')
plt.ylabel('Y')
plt.title('Visualisation des données clusterisées')
ax.set_aspect('equal')
plt.show()

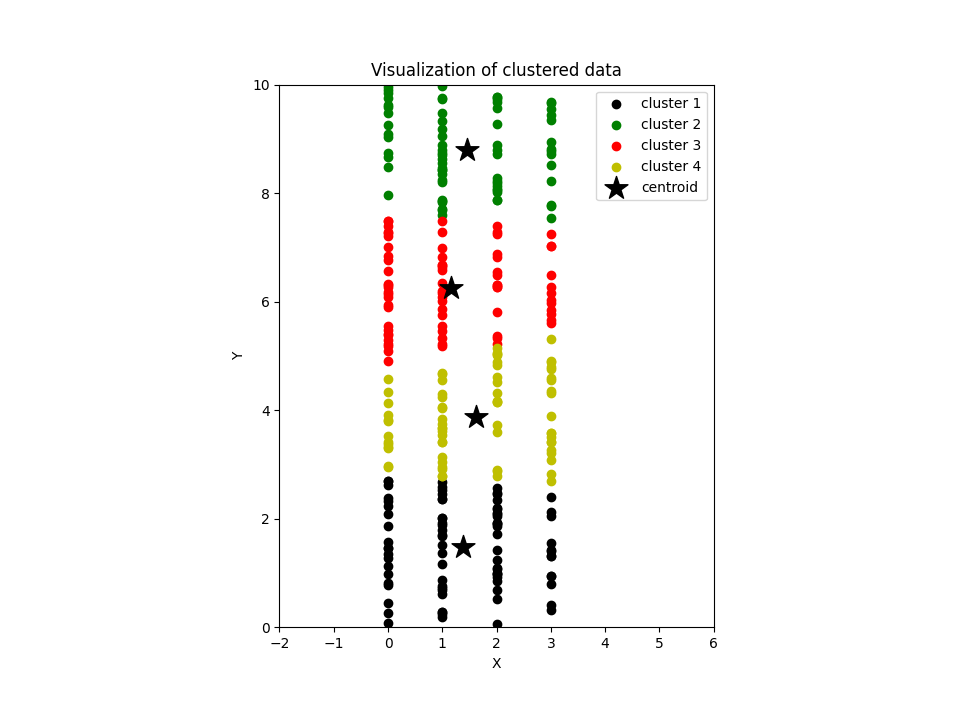
Dans la figure ci-dessus, K-means a regroupé ces observations en 4 groupes. Et comme vous pouvez le voir sur la visualisation, la manière dont les observations ont été clusterisées semble naturelle et logique, même graphiquement.
Méthode du coude pour le nombre optimal de clusters (K)
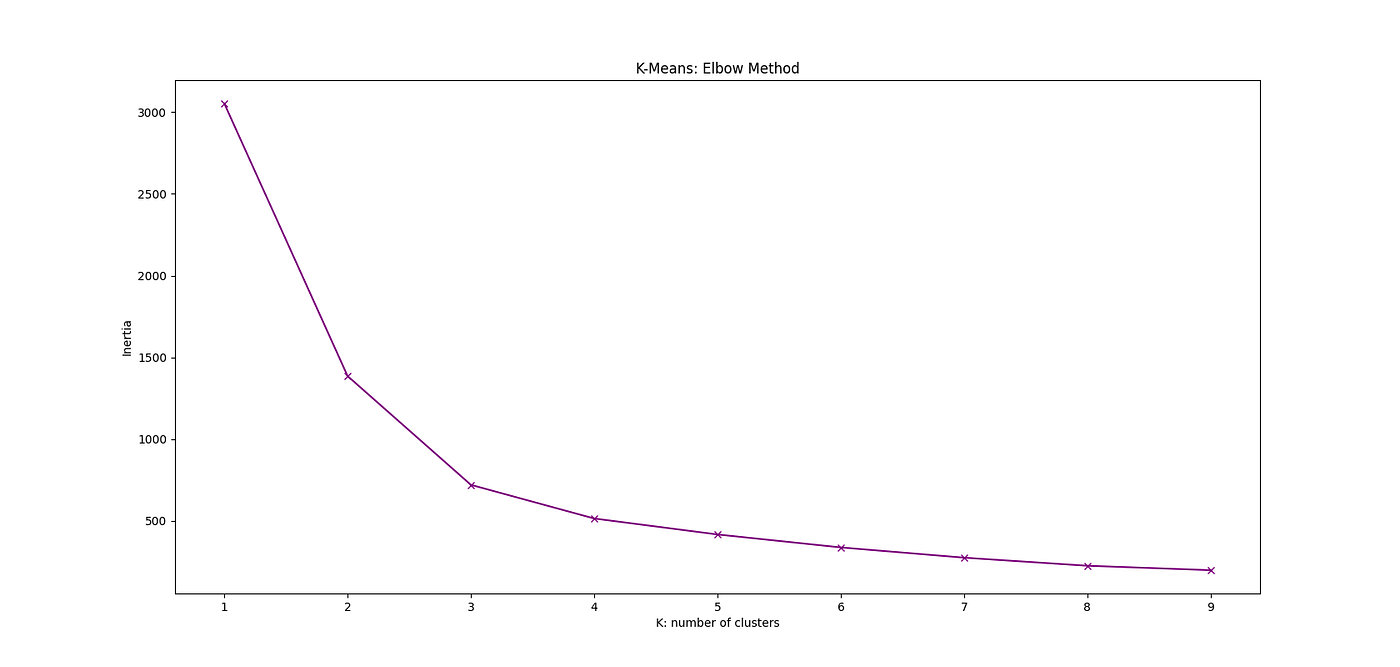
L'un des plus grands défis de l'utilisation de K-means est le choix du nombre de clusters. Parfois, il s'agit d'une décision métier, mais la plupart du temps, nous voulons choisir un K qui est optimal et qui a du sens. L'une des méthodes les plus populaires pour déterminer cette valeur optimale de K, ou nombre de clusters, est la méthode du coude (Elbow Method).
Pour utiliser cette approche, vous devez savoir ce qu'est l'Inertie. L'inertie est la somme des carrés des distances des échantillons à leur centre de cluster le plus proche. Ainsi, la valeur de l'inertie ou de la somme des carrés intra-cluster donne une indication de la cohérence ou de la pureté des différents clusters. L'inertie peut être décrite comme suit :
$$\sum_{i=1}^{N} (x_i - C_k)^2$$
où N est le nombre d'échantillons dans le jeu de données, C est le centre d'un cluster et k est l'indice du cluster. Ainsi, l'inertie calcule simplement la distance au carré de chaque échantillon d'un cluster par rapport à son centre de cluster et les additionne.
Ensuite, nous pouvons calculer l'inertie pour différents nombres de clusters K. Nous pouvons tracer cela comme dans la figure suivante où nous considérons K = 1, 2, ..., 10. Ensuite, à partir du graphique, nous pouvons sélectionner le K correspondant à l'inertie où le "coude" se produit. Dans ce cas, le coude se produit à K = 3.
def Elbow_Method(df):
inertia = []
# considération de K = 1,2,...,10 comme K
K = range(1, 10)
for k in K:
KMeans_Model = KMeans(n_clusters=k, random_state = 2022)
KMeans_Model.fit(df)
inertia.append(KMeans_Model.inertia_)
return(inertia)
K = range(1, 10)
inertia = Elbow_Method(df)
plt.figure(figsize = (17,8))
plt.plot(K, inertia, 'bx-')
plt.xlabel("K: nombre de clusters")
plt.ylabel("Inertie")
plt.title("K-Means: Méthode du coude")
plt.show()

K-Means est une approche non déterministe et son caractère aléatoire intervient à l'étape 1, où toutes les observations sont assignées aléatoirement à l'une des K classes.
Comme vous pouvez le voir, le clustering K-Means offre une approche efficace pour regrouper des points de données basés sur la similarité. En implémentant l'algorithme K-Means en Python, vous pouvez facilement appliquer cette technique à vos propres jeux de données et obtenir des informations précieuses.
Python fournit des outils puissants pour implémenter et visualiser le clustering K-Means. Avec la bibliothèque scikit-learn et matplotlib, vous pouvez facilement appliquer K-Means à vos jeux de données et apprendre beaucoup des clusters résultants.

Théorie du clustering hiérarchique
Une autre technique de clustering populaire est le clustering hiérarchique. Il s'agit d'une autre technique d'apprentissage non supervisé qui nous aide à regrouper des observations en segments. Mais contrairement à K-means, le clustering hiérarchique commence par traiter chaque observation comme un cluster séparé.
Clustering agglomératif vs divisif
Il existe deux types principaux de clustering hiérarchique : agglomératif et divisif.
Le clustering agglomératif commence par assigner chaque point de données à son propre cluster. Ensuite, il fusionne itérativement les clusters les plus similaires sur la base d'une métrique de distance choisie jusqu'à ce qu'un seul cluster contenant tous les points de données soit formé.
Cette approche ascendante (bottom-up) crée une structure arborescente binaire, également connue sous le nom de dendrogramme, où la hauteur de chaque nœud représente la dissimilarité entre les clusters fusionnés.
D'un autre côté, le clustering divisif commence par un seul cluster contenant tous les points de données. Il divise ensuite récursivement le cluster en sous-clusters plus petits jusqu'à ce que chaque point de données soit dans son propre cluster. Cette approche descendante (top-down) génère un dendrogramme qui donne des informations sur la hiérarchie des clusters.
Métriques de distance pour le clustering hiérarchique
Pour déterminer la similarité entre les clusters ou les points de données, il existe diverses métriques de distance que vous pouvez utiliser. Les mesures de distance couramment employées incluent la distance euclidienne, la distance de Manhattan et la similarité cosinus. Ces métriques quantifient la dissimilarité ou la similarité entre des paires de points de données et guident le processus de clustering.
Dans cette technique, initialement chaque point de données est considéré comme un cluster individuel. À chaque itération, les clusters les plus similaires ou les moins disséminés fusionnent en un seul cluster et ce processus se poursuit jusqu'à ce qu'il n'y ait plus qu'un seul cluster. Ainsi, l'algorithme effectue de manière répétée les étapes suivantes :
1 : identifier les deux clusters les plus proches
2 : fusionner les deux clusters les plus similaires.
Ensuite, il continue ce processus itératif jusqu'à ce que tous les clusters soient fusionnés.
Le calcul de la dissimilarité ou de la similarité de deux clusters dépend du type de lien (Linkage) que nous supposons. Il existe 5 options de lien populaires :
Lien complet (Complete Linkage) : dissimilarité inter-cluster maximale pour laquelle vous devez calculer toutes les dissimilarités par paires entre les observations du cluster K1 et les observations du cluster K2. Choisissez ensuite la plus grande de ces similarités.
Lien simple (Single Linkage) : dissimilarité inter-cluster minimale pour laquelle vous devez calculer toutes les dissimilarités par paires entre les observations du cluster K1 et les observations du cluster K2. Choisissez ensuite la plus petite de ces similarités.
Lien moyen (Average Linkage) : dissimilarité inter-cluster moyenne pour laquelle vous devez calculer toutes les dissimilarités par paires entre les observations du cluster K1 et les observations du cluster K2. Calculez ensuite la moyenne de ces similarités.
Lien de centroïde (Centroid Linkage) : dissimilarité entre le centroïde du cluster K1 et le centroïde du cluster K2 (c'est généralement le choix de lien le moins souhaité car il peut entraîner beaucoup de chevauchements).
Méthode de Ward : détermine quelles observations regrouper en se basant sur la réduction de la somme des carrés des distances de chaque observation par rapport à l'observation moyenne d'un cluster.
Implémentation du clustering hiérarchique en Python
Le clustering hiérarchique est une technique puissante d'apprentissage non supervisé qui vous permet de regrouper des points de données en clusters en fonction de leur similarité. Dans cette section, nous explorerons l'implémentation du clustering hiérarchique en utilisant Python.
Voici un exemple de la façon d'implémenter le clustering hiérarchique en utilisant Python :
import scipy.cluster.hierarchy as HieraarchicalClustering
from sklearn.cluster import AgglomerativeClustering
import numpy as np
import pandas as pd
# création de données pour le clustering hiérarchique
df = np.random.randint(0,10,size = [100,2])
X1 = np.random.randint(0,4,size = [300,1])
X2 = np.random.uniform(0,10,size = [300,1])
df = np.append(X1,X2,axis = 1)
hierCl = HieraarchicalClustering.linkage(df, method='ward')
Hcl= AgglomerativeClustering(n_clusters = 7, affinity = 'euclidean', linkage ='ward')
Hcl_fitted = Hcl.fit_predict(df)
df = pd.DataFrame(df)
df["labels"] = Hcl_fitted

Ce code implémente le clustering hiérarchique en utilisant à la fois le module de clustering hiérarchique de Scipy et l'algorithme de clustering agglomératif de Scikit-learn. Le but du script est de générer un jeu de données synthétique, d'appliquer le clustering hiérarchique et d'assigner des étiquettes de cluster aux points de données.
La première partie du script importe les bibliothèques nécessaires. Le module de clustering hiérarchique de Scipy (scipy.cluster.hierarchy) est importé sous le nom HieraarchicalClustering, qui est utilisé pour effectuer le clustering basé sur les liens. La classe AgglomerativeClustering de Scikit-learn est également importée pour implémenter un type spécifique de clustering hiérarchique. De plus, NumPy est utilisé pour les opérations numériques et la génération de données aléatoires, tandis que Pandas est utilisé pour structurer les données dans un DataFrame.
Ensuite, le script génère des données numériques synthétiques. Une matrice 100×2 (df) est créée avec des entiers aléatoires entre 0 et 9. Ensuite, deux jeux de données supplémentaires, X1 et X2, sont créés séparément. X1 contient 300 entiers aléatoires entre 0 et 3, tandis X2 contient 300 valeurs flottantes aléatoires entre 0 et 10. Ces deux jeux de données sont ensuite combinés à l'aide de np.append(), formant un jeu de données avec deux caractéristiques qui sera utilisé pour le clustering.
Une fois le jeu de données préparé, le clustering hiérarchique est appliqué en utilisant la méthode de lien de Ward, qui minimise la variance entre les clusters fusionnés. La matrice de lien hierCl est créée à l'aide de HieraarchicalClustering.linkage(df, method='ward'), qui calcule la solution de clustering hiérarchique.
Après avoir généré la matrice de lien du clustering hiérarchique, le clustering agglomératif est appliqué pour regrouper les données en sept clusters (n_clusters=7). Le paramètre affinity='euclidean' spécifie que la distance euclidienne sera utilisée comme métrique de distance pour mesurer la similarité entre les points. Le paramètre linkage='ward' garantit que la méthode de Ward est utilisée pour fusionner les clusters en minimisant la variance. Le modèle est ensuite ajusté au jeu de données à l'aide de Hcl.fit_predict(df), qui assigne une étiquette de cluster à chaque point de données.
Enfin, le jeu de données est converti en un DataFrame Pandas, et une nouvelle colonne "labels" est ajoutée pour stocker les étiquettes de cluster assignées. Le DataFrame résultant contient maintenant à la fois les points de données originaux et leurs assignations de clusters correspondantes, permettant une analyse ou une visualisation ultérieure.
En résumé, ce script génère des données aléatoires, applique le clustering hiérarchique en utilisant à la fois la méthode de lien de Scipy et le clustering agglomératif de Scikit-learn, et assigne des étiquettes de cluster à chaque point de données. Le jeu de données final peut être utilisé pour analyser les structures de clusters, visualiser les résultats ou valider l'efficacité du clustering.
Clustering hiérarchique : Visualisation
L'un des principaux avantages du clustering hiérarchique est sa capacité à créer une structure hiérarchique de clusters, ce qui peut fournir des informations précieuses sur les relations entre les points de données.
Pour visualiser le clustering hiérarchique en Python, nous pouvons utiliser diverses bibliothèques telles que Scikit-learn, SciPy et Matplotlib. Ces bibliothèques offrent des fonctions et des outils faciles à utiliser qui facilitent le processus de visualisation.
Ainsi, après avoir effectué le clustering hiérarchique, il est souvent utile de visualiser les clusters. Nous pouvons utiliser diverses techniques de visualisation, telles que les dendrogrammes ou les cartes de chaleur (heatmaps).
Comme nous l'avons vu plus haut, un dendrogramme est un diagramme arborescent qui montre les relations hiérarchiques entre les clusters. Il peut être généré à l'aide de la bibliothèque Scipy en Python.
Voici un exemple de la façon de visualiser un dendrogramme et des points clusterisés en Python :
# Générer un dendrogramme pour aider à déterminer le nombre optimal de clusters
# Le dendrogramme visualise comment le clustering hiérarchique fusionne les points étape par étape
dendrogram = HieraarchicalClustering.dendrogram(hierCl)
# Définir le titre du graphique du dendrogramme
plt.title('Dendrogramme')
# Étiqueter l'axe x pour indiquer les observations (points de données)
plt.xlabel("Observations")
# Étiqueter l'axe y pour montrer les distances euclidiennes entre les clusters
plt.ylabel('Distances euclidiennes')
# Afficher le graphique du dendrogramme
plt.show()
# Visualisation des données clusterisées à l'aide d'un graphique de dispersion
# Chaque couleur représente un cluster différent
# Tracer tous les points appartenant au cluster 1 en noir
plt.scatter(df[df["labels"] == 0][0], df[df["labels"] == 0][1],
c='black', label='cluster 1')
# Tracer tous les points appartenant au cluster 2 en vert
plt.scatter(df[df["labels"] == 1][0], df[df["labels"] == 1][1],
c='green', label='cluster 2')
# Tracer tous les points appartenant au cluster 3 en rouge
plt.scatter(df[df["labels"] == 2][0], df[df["labels"] == 2][1],
c='red', label='cluster 3')
# Tracer tous les points appartenant au cluster 4 en magenta
plt.scatter(df[df["labels"] == 3][0], df[df["labels"] == 3][1],
c='magenta', label='cluster 4')
# Tracer tous les points appartenant au cluster 5 en violet
plt.scatter(df[df["labels"] == 4][0], df[df["labels"] == 4][1],
c='purple', label='cluster 5')
# Tracer tous les points appartenant au cluster 6 en jaune
plt.scatter(df[df["labels"] == 5][0], df[df["labels"] == 5][1],
c='y', label='cluster 6')
# Tracer tous les points appartenant au cluster 7 en noir
plt.scatter(df[df["labels"] == 6][0], df[df["labels"] == 6][1],
c='black', label='cluster 7')
# Afficher la légende pour étiqueter chaque cluster dans le graphique
plt.legend()
# Étiqueter l'axe x représentant la caractéristique 1 (première dimension)
plt.xlabel('X')
# Étiqueter l'axe y représentant la caractéristique 2 (deuxième dimension)
plt.ylabel('Y')
# Définir le titre du graphique de dispersion
plt.title('Clustering hiérarchique')
# Afficher le graphique de dispersion clusterisé
plt.show()

Voici un guide étape par étape pour visualiser le clustering hiérarchique en Python :
Étape 1 : Prétraiter les données
Avant de visualiser le clustering hiérarchique, il est important de prétraiter les données en les mettant à l'échelle ou en les normalisant. Cela garantit que toutes les caractéristiques ont une plage similaire et évite tout biais envers des caractéristiques spécifiques.
Étape 2 : Effectuer le clustering hiérarchique
Ensuite, nous effectuons le clustering hiérarchique en utilisant l'algorithme choisi, tel que AgglomerativeClustering de Scikit-learn. Cet algorithme calcule la similarité entre les points de données et les fusionne en clusters en fonction d'un critère de lien spécifique.
Étape 3 : Créer un dendrogramme
Nous pouvons utiliser la fonction dendrogram de la bibliothèque SciPy pour créer cette visualisation. Le dendrogramme nous permet de visualiser les distances et les relations entre les clusters.
Étape 4 : Tracer les clusters
Enfin, nous pouvons tracer les clusters en utilisant un graphique de dispersion ou une autre technique de visualisation appropriée. Cela nous aide à visualiser les points de données au sein de chaque cluster et à obtenir des informations sur les caractéristiques de chaque cluster.
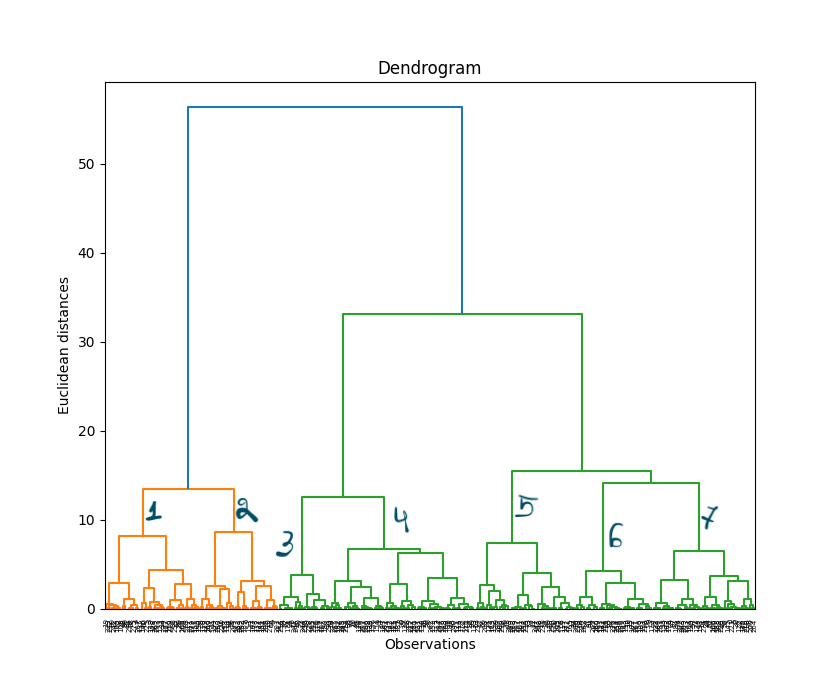
Ce dendrogramme peut ensuite nous aider à décider du nombre de clusters que nous pouvons utiliser au mieux. Comme vous pouvez le voir, il semble que, dans ce cas, nous devrions utiliser 7 clusters.
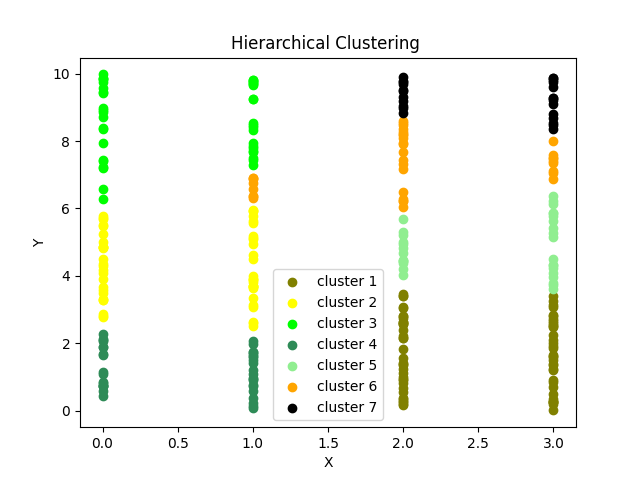
En visualisant le clustering hiérarchique en Python, nous pouvons acquérir une meilleure compréhension de la structure et des relations au sein de nos données. Cette technique de visualisation est particulièrement utile lorsqu'on traite des jeux de données complexes et peut aider dans les processus de prise de décision et la découverte de motifs.
N'oubliez pas d'ajuster les paramètres et réglages spécifiques en fonction de votre jeu de données et de votre objectif. L'expérimentation avec différentes visualisations et techniques peut mener à des insights encore plus profonds sur vos données.
Théorie du clustering DBSCAN
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) est un algorithme d'apprentissage non supervisé utilisé pour l'analyse de clustering. Il est particulièrement efficace pour identifier des clusters de forme arbitraire et gérer les données bruitées.
Contrairement à K-Means ou au clustering hiérarchique, DBSCAN ne nécessite pas de spécifier le nombre de clusters à l'avance. Au lieu de cela, il définit les clusters en fonction de la densité et de la connectivité au sein des données.
Comment fonctionne DBSCAN :
Clustering basé sur la densité : DBSCAN regroupe les points de données qui sont à proximité les uns des autres et qui ont un nombre suffisant de voisins proches. Il identifie les régions denses de points de données comme des clusters et sépare les régions éparses comme du bruit.
Points cœurs (Core Points), points frontières (Border Points) et points de bruit (Noise Points) : DBSCAN catégorise les points de données en trois types :
Points cœurs : Points de données ayant un nombre minimum de points voisins (défini par le paramètre
min_samples) dans une distance spécifiée (définie par le paramètreeps).Points frontières : Points de données qui se trouvent à la distance
epsd'un point cœur mais n'ont pas assez de points voisins pour être considérés comme des points cœurs.Points de bruit : Points de données qui ne sont ni des points cœurs ni des points frontières.
Accessibilité et connectivité : DBSCAN utilise les notions d'accessibilité et de connectivité pour définir les clusters. Un point de données est considéré comme accessible depuis un autre point de données s'il existe un chemin de points cœurs qui les relie. Si deux points de données sont accessibles, ils appartiennent au même cluster.
Croissance du cluster : DBSCAN commence par un point de données arbitraire et étend le cluster en examinant ses voisins et leurs voisins, formant un groupe connecté de points de données.
Avantages du clustering DBSCAN :
Capacité à détecter des structures complexes : DBSCAN peut découvrir des clusters de formes et de tailles variées, ce qui le rend bien adapté aux jeux de données avec des relations non linéaires ou des motifs irréguliers.
Robuste au bruit : DBSCAN gère efficacement les données bruitées en catégorisant les points de bruit séparément des clusters.
Détermination automatique du nombre de clusters : DBSCAN ne nécessite pas de spécifier le nombre de clusters à l'avance, ce qui le rend plus pratique et adaptable à différents jeux de données.
Passage à l'échelle sur de grands jeux de données : La complexité temporelle de DBSCAN est relativement faible par rapport à certains autres algorithmes de clustering, ce qui lui permet de bien s'adapter aux grands jeux de données.
Dans la section suivante, nous aborderons l'implémentation de l'algorithme DBSCAN en Python, en fournissant des conseils et des exemples étape par étape.
Clustering DBSCAN : Implémentation en Python
Dans cette section, je vais vous guider sur la façon d'implémenter DBSCAN en utilisant Python.
Étapes clés pour le clustering DBSCAN
Préparer les données : Avant d'appliquer DBSCAN, il est important de prétraiter vos données. Cela inclut la gestion des valeurs manquantes, la normalisation des caractéristiques et la sélection de la métrique de distance appropriée.
Définir les paramètres : DBSCAN nécessite deux paramètres principaux : epsilon (ε) et le nombre minimum de points (MinPts). Epsilon détermine la distance maximale entre deux points pour les considérer comme voisins, et MinPts spécifie le nombre minimum de points requis pour former une région dense.
Effectuer le clustering basé sur la densité : DBSCAN commence par sélectionner aléatoirement un point de données et identifier ses voisins dans la distance epsilon spécifiée. Si le nombre de voisins dépasse le seuil MinPts, un nouveau cluster est formé. L'algorithme étend ce cluster en ajoutant itérativement de nouveaux points jusqu'à ce qu'aucun autre point ne puisse être atteint.
Effectuer la détection de bruit : Les points qui n'appartiennent à aucun cluster sont considérés comme du bruit ou des valeurs aberrantes. Ces points ne sont assignés à aucun cluster et peuvent être critiques pour identifier des anomalies au sein des données.
Pour effectuer le clustering DBSCAN en Python, nous pouvons utiliser la bibliothèque scikit-learn. La première étape consiste à importer les bibliothèques nécessaires et à charger le jeu de données que nous voulons clusteriser. Ensuite, nous pouvons créer une instance de la classe DBSCAN et définir les paramètres epsilon (eps) et le nombre minimum d'échantillons (min_samples).
Voici un exemple de code pour vous aider à démarrer :
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.cluster import DBSCAN
# Génération de quelques données d'exemple
X, _ = make_moons(n_samples=500, noise=0.05, random_state=0)
# Application de DBSCAN
db = DBSCAN(eps=0.3, min_samples=5, metric='euclidean')
y_db = db.fit_predict(X)

N'oubliez pas de remplacer X par votre jeu de données réel. Vous pouvez ajuster les paramètres eps et min_samples pour obtenir différents résultats de clustering. Le paramètre eps est la distance maximale entre deux échantillons pour que l'un soit considéré comme étant dans le voisinage de l'autre. Le min_samples est le nombre d'échantillons (ou le poids total) dans un voisinage pour qu'un point soit considéré comme un point cœur.
DBSCAN offre divers avantages par rapport aux autres algorithmes de clustering, comme le fait de ne pas exiger que le nombre de clusters soit prédéfini. Cela le rend adapté aux jeux de données dont le nombre de clusters est inconnu. DBSCAN est également capable d'identifier des clusters de formes et de tailles variées, ce qui le rend plus flexible pour capturer des structures complexes.
Cependant, DBSCAN peut éprouver des difficultés avec des densités variables dans les jeux de données et peut être sensible au choix des paramètres epsilon et du nombre minimum de points. Il est crucial de peaufiner ces paramètres pour obtenir des résultats de clustering optimaux.
En implémentant DBSCAN en Python, vous pouvez exploiter ce puissant algorithme de clustering pour découvrir des motifs et des structures significatifs dans vos données.
Avant d'explorer les différences entre DBSCAN et d'autres techniques de clustering, examinons de plus près les paramètres clés qui influencent la performance et les résultats de DBSCAN.
Comprendre les paramètres clés de DBSCAN
Le paramètre eps (epsilon) définit la distance maximale entre deux points pour que l'un soit considéré comme un voisin de l'autre. Cela signifie que les points situés dans ce rayon d'un point cœur appartiennent au même cluster. Le choix d'une valeur eps appropriée est crucial, car un eps très petit peut conduire à un trop grand nombre de petits clusters, tandis qu'un eps très grand pourrait fusionner des clusters distincts en un seul.
Le paramètre min_samples détermine le nombre minimum de points de données requis pour former une région dense. Si un point a au moins min_samples voisins dans le rayon eps, il est classé comme point cœur (core point). Si un point tombe dans le rayon eps d'un point cœur mais ne remplit pas lui-même le seuil min_samples, il est classé comme point frontière (border point). Tout point qui n'est ni un point cœur ni un point frontière est étiqueté comme bruit ou valeur aberrante.
Comment DBSCAN regroupe les points de données
DBSCAN fonctionne en identifiant les points cœurs et en étendant les clusters autour d'eux. Il regroupe les points étroitement emballés (ou clusters) en fonction de la densité et marque les points de faible densité comme des valeurs aberrantes (ou bruit). Le processus suit ces étapes :
Sélectionner un point non visité et vérifier s'il a au moins
min_samplesvoisins dans le rayoneps.Si c'est le cas, ce point devient un point cœur, et un nouveau cluster est formé autour de lui.
Étendre le cluster en ajoutant tous les points directement accessibles dans le rayon
eps. Si l'un de ces points est également un point cœur, ses voisins sont également ajoutés.Continuer l'extension jusqu'à ce qu'aucun autre point ne réponde aux critères de densité.
Passer au point non visité suivant et répéter le processus.
Classer les points restants comme points frontières (faisant partie d'un cluster mais n'étant pas des points cœurs) ou comme bruit (valeurs aberrantes qui n'appartiennent à aucun cluster).
Exemple d'implémentation de DBSCAN
Dans cette implémentation :
eps=0.3: Définit la proximité nécessaire pour que des points soient considérés comme voisins.min_samples=5: Fixe le nombre minimum de points requis pour former une région dense.fit_predict(X): Assigne une étiquette de cluster à chaque point de données.
Après avoir appliqué DBSCAN, les points de données reçoivent des étiquettes. Si deux points appartiennent au même cluster, ils auront la même étiquette dans y_db. Les points identifiés comme valeurs aberrantes seront étiquetés -1 et resteront non clusterisés.
Le graphique de dispersion résultant représente visuellement comment DBSCAN a identifié deux clusters en forme de lune. Contrairement à K-Means, qui suppose des clusters sphériques, DBSCAN est capable de détecter efficacement des clusters de formes arbitraires.
plt.scatter(X[y_db == 0, 0], X[y_db == 0, 1],
c='lightblue', marker='o', s=40,
edgecolor='black',
label='cluster 1')
plt.scatter(X[y_db == 1, 0], X[y_db == 1, 1],
c='red', marker='s', s=40,
edgecolor='black',
label='cluster 2')
plt.legend()
plt.show()

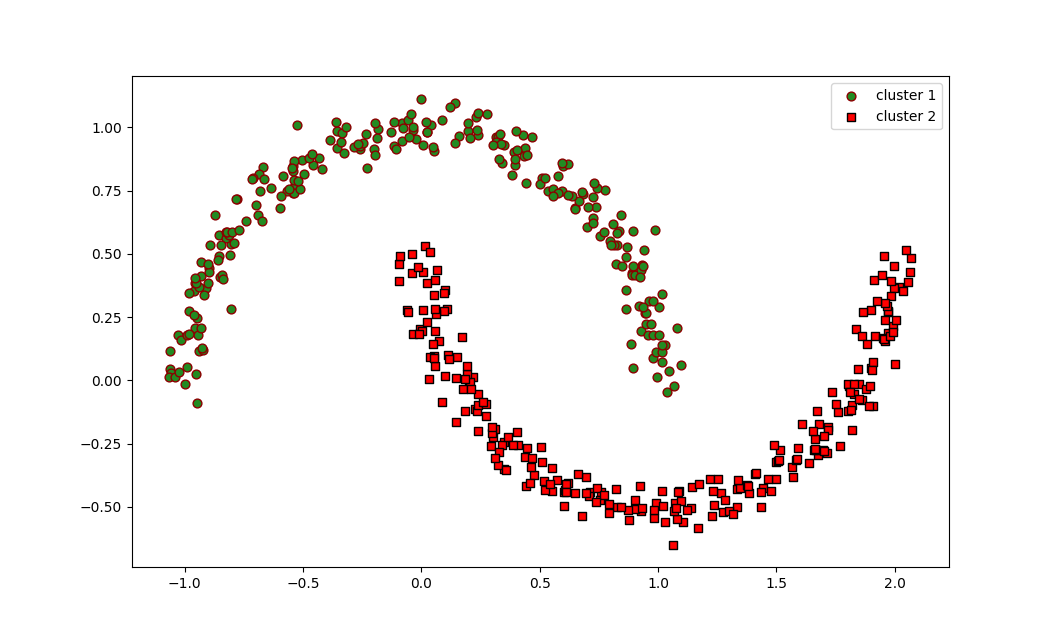
Le graphique résultant montrera deux clusters en forme de lune de couleurs verte et rouge, démontrant que DBSCAN a réussi à identifier et à séparer les deux demi-cercles entrelacés.
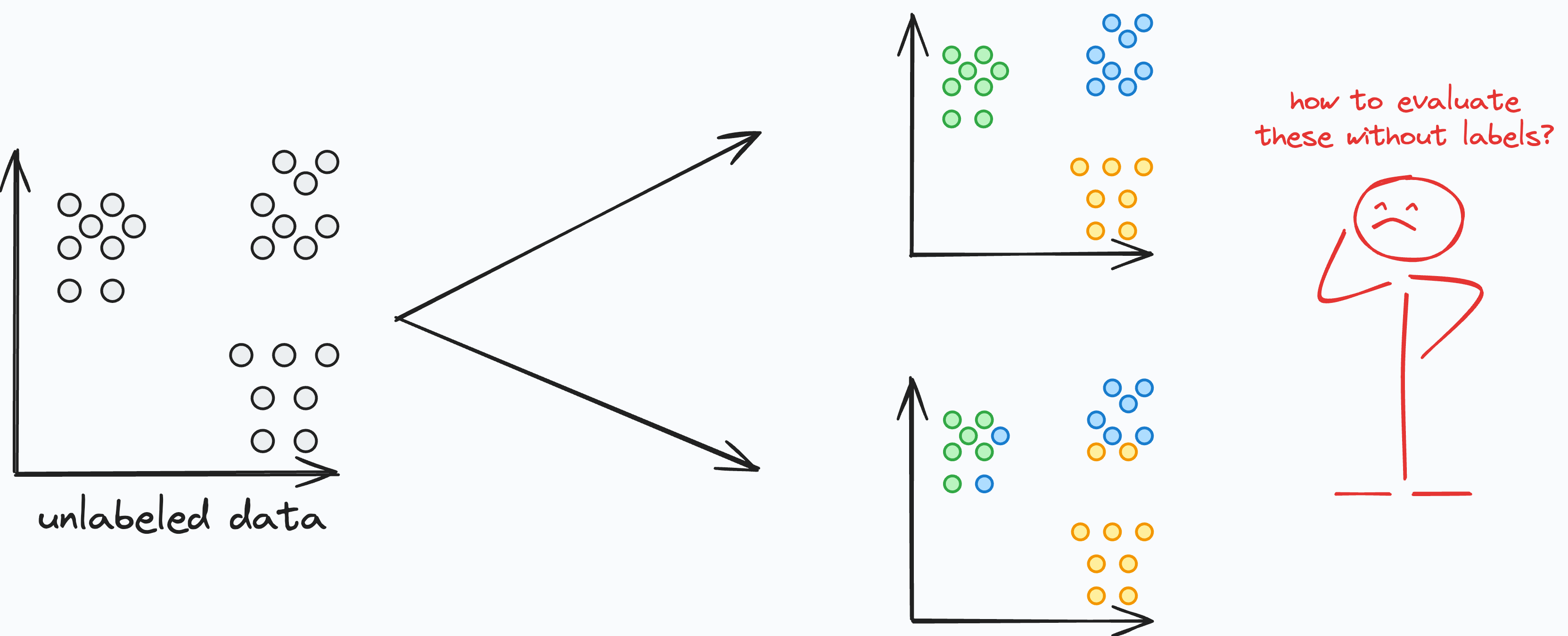
Comment évaluer la performance d'un algorithme de clustering
Évaluer la performance d'un modèle de clustering peut être difficile, car il n'y a pas d'étiquettes de vérité terrain (ground truth) disponibles dans l'apprentissage non supervisé. Cependant, il existe plusieurs métriques d'évaluation qui peuvent donner des indications sur la qualité des résultats du clustering.
Coefficient de Silhouette : Mesure à quel point chaque point de données s'insère bien dans son cluster assigné par rapport aux autres clusters. Un coefficient de silhouette plus élevé indique un meilleur clustering.
Indice de Davies-Bouldin : Mesure la similarité moyenne entre chaque cluster et son cluster le plus similaire, tout en tenant compte de la séparation entre les clusters. Des valeurs plus faibles indiquent un meilleur clustering.
Indice de Calinski-Harabasz : Évalue le rapport entre la dispersion inter-cluster et la dispersion intra-cluster. Des valeurs plus élevées indiquent des clusters mieux définis.
Évaluation visuelle : L'inspection des représentations visuelles des résultats du clustering, telles que les graphiques de dispersion ou les dendrogrammes, peut également fournir des informations précieuses sur la qualité et la pertinence des clusters.
Je vous recommande d'utiliser une combinaison de métriques d'évaluation et d'évaluations visuelles pour évaluer de manière exhaustive la performance d'un modèle de clustering.
Différence entre K-Means, le clustering hiérarchique et DBSCAN
K-Means, le clustering hiérarchique et DBSCAN sont trois algorithmes de clustering largement utilisés, chacun ayant sa propre approche pour regrouper les points de données. Comprendre leurs différences est crucial pour sélectionner la méthode la plus appropriée en fonction des caractéristiques des données et des objectifs analytiques.
Clustering K-Means
Le clustering K-Means est un algorithme basé sur les centroïdes qui partitionne les données en K clusters en fonction de la similarité. L'algorithme commence par initialiser aléatoirement K centroïdes, puis assigne itérativement chaque point de données au centroïde le plus proche. Une fois que tous les points de données sont assignés, les centroïdes sont recalculés sur la base de la moyenne des points au sein de chaque cluster. Ce processus se poursuit jusqu'à ce que la convergence soit atteinte.
Points forts du clustering K-Means :
Efficace et scalable pour les grands jeux de données.
Fonctionne bien lorsque les clusters sont sphériques et uniformément répartis.
Plus rapide sur le plan computationnel par rapport au clustering hiérarchique.
Facile à implémenter et à interpréter.
Points faibles du clustering K-Means :
Nécessite de spécifier le nombre de clusters (K) à l'avance.
Sensible aux positions initiales des centroïdes, ce qui conduit à des résultats variables.
Suppose que les clusters sont de taille égale et sphériques, ce qui n'est pas toujours le cas.
Éprouve des difficultés avec les valeurs aberrantes et les clusters de formes non linéaires.
Clustering hiérarchique
Le clustering hiérarchique crée une hiérarchie imbriquée de clusters sans nécessiter un nombre prédéfini de clusters. Il commence par traiter chaque point de données comme un cluster individuel et fusionne ou divise progressivement les clusters en fonction de la similarité. Les résultats sont souvent visualisés à l'aide d'un dendrogramme, qui aide à déterminer le nombre optimal de clusters.
Points forts du clustering hiérarchique :
Ne nécessite pas de spécifier le nombre de clusters à l'avance.
Capture les relations hiérarchiques entre les clusters.
Peut gérer différents types de données, y compris numériques et catégorielles.
Utile pour l'analyse exploratoire avec un dendrogramme pour une meilleure interprétabilité.
Points faibles du clustering hiérarchique :
Coûteux en termes de calcul pour les grands jeux de données (complexité O(n²)).
Difficile à mettre à l'échelle en raison des contraintes de mémoire lors du traitement d'un grand nombre de points de données.
Le choix du bon point de coupure pour le dendrogramme peut être difficile.
Sensible au bruit et aux valeurs aberrantes, qui peuvent fausser la hiérarchie.
DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
DBSCAN est un algorithme de clustering basé sur la densité qui regroupe les points de données en fonction de leur proximité et de leur densité plutôt que de clusters prédéfinis. Contrairement à K-Means et au clustering hiérarchique, DBSCAN ne nécessite pas de spécifier le nombre de clusters. Au lieu de cela, il utilise deux paramètres clés : eps (la distance maximale entre deux points pour être considérés comme voisins) et min_samples (le nombre minimum de points requis pour former un cluster dense). Les points qui ne répondent pas à ces critères sont classés comme du bruit.
Points forts de DBSCAN :
Ne nécessite pas de spécifier le nombre de clusters à l'avance.
Peut détecter des clusters de formes arbitraires, contrairement à K-Means qui suppose des clusters sphériques.
Gère efficacement les valeurs aberrantes, qui sont étiquetées comme du bruit au lieu d'être forcées dans un cluster.
Adapté aux jeux de données avec des densités variables et des structures non linéaires.
Points faibles de DBSCAN :
Éprouve des difficultés avec des densités de clusters variables, car une seule valeur eps peut ne pas convenir à tous les clusters.
Peut être sensible au réglage des paramètres (eps et min_samples) qui peuvent impacter la performance du clustering.
Pas idéal pour les données de haute dimension, car la distance euclidienne perd son sens dans les espaces de haute dimension.
Peut éprouver des difficultés avec de très grands jeux de données, bien qu'il passe mieux à l'échelle que le clustering hiérarchique.
Choisir le bon algorithme de clustering
| Caractéristique | K-Means | Clustering hiérarchique | DBSCAN |
| Forme du cluster | Suppose des clusters sphériques | Fonctionne bien avec les structures hiérarchiques | Gère les clusters de formes arbitraires |
| Scalabilité | Très scalable (rapide pour les grands datasets) | Non scalable (complexité O(n²)) | Modérément scalable (peut peiner avec de très grands datasets) |
| Nombre de clusters | Doit être prédéfini | Pas besoin de spécifier | Pas besoin de spécifier |
| Gestion des outliers | Faible | Sensible au bruit | Bonne, détecte les outliers comme du bruit |
| Complexité de calcul | O(n) à O(n log n) | O(n²) | O(n log n) |
| Interprétabilité | Facile à interpréter | Le dendrogramme donne un bon aperçu | Moins intuitif, nécessite un réglage de paramètres |
Chaque algorithme de clustering a ses forces et ses faiblesses. K-Means est idéal pour traiter de grands jeux de données lorsque les clusters sont sphériques et bien séparés. Le clustering hiérarchique est utile lorsque des relations hiérarchiques existent ou lorsque le nombre de clusters est inconnu. DBSCAN excelle dans la détection de clusters de formes arbitraires et la gestion du bruit, mais nécessite un réglage minutieux des paramètres.
En comprenant les caractéristiques de chaque algorithme, vous pouvez prendre une décision éclairée sur la méthode de clustering qui convient le mieux à vos besoins d'analyse de données.
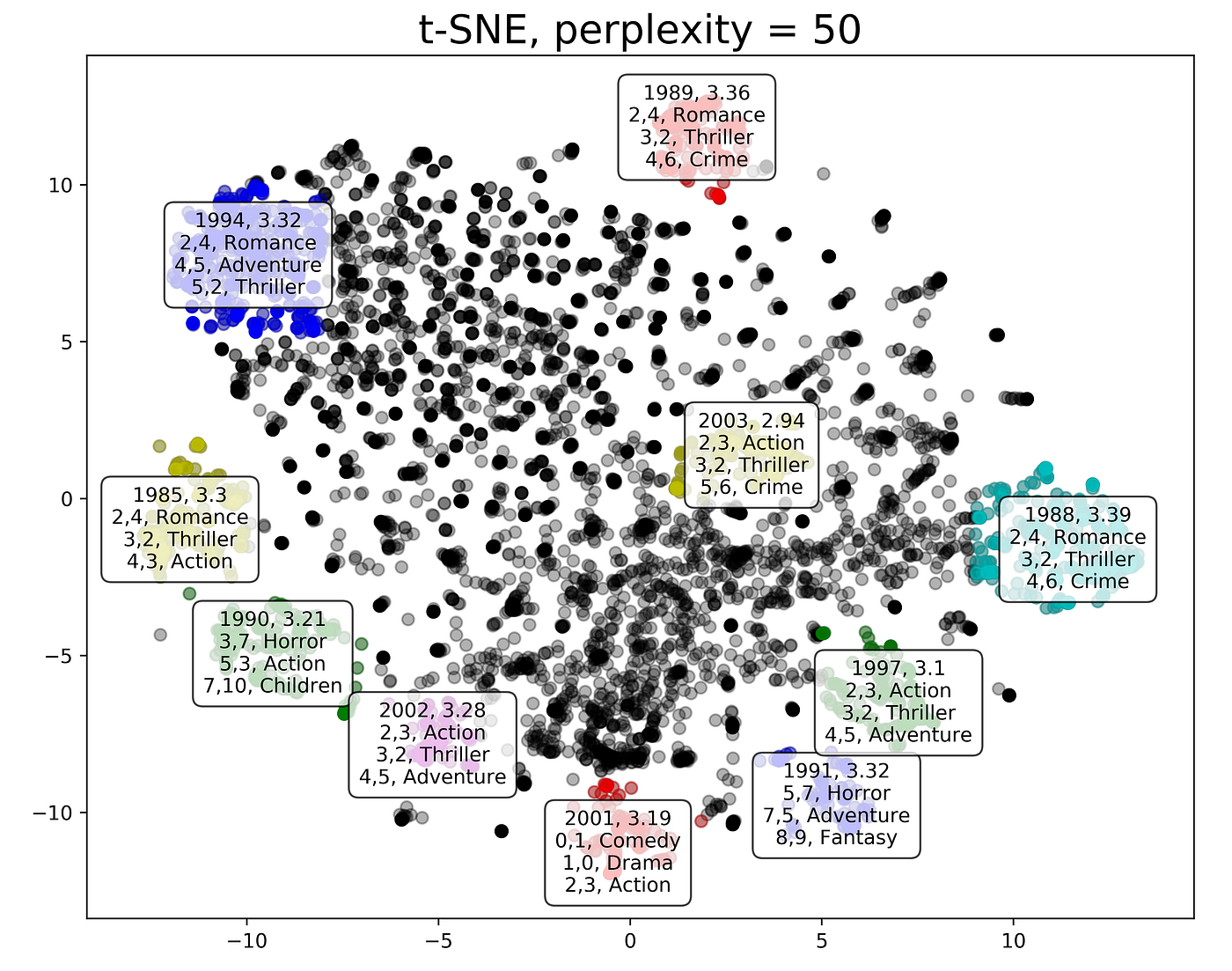
Comment utiliser t-SNE pour visualiser les clusters avec Python
Après avoir appliqué des algorithmes de clustering comme K-Means, le clustering hiérarchique et DBSCAN, vous voudrez souvent visualiser les clusters résultants pour mieux comprendre la structure sous-jacente des données.
Alors que les graphiques de dispersion fonctionnent bien pour les jeux de données à deux ou trois dimensions, les jeux de données du monde réel contiennent souvent des caractéristiques de haute dimension qui sont difficiles à interpréter visuellement.
Pour relever ce défi, vous pouvez utiliser des techniques de réduction de dimensionnalité comme t-SNE (t-Distributed Stochastic Neighbor Embedding) pour projeter des données de haute dimension dans un espace de dimension inférieure tout en préservant leur structure. Cela vous permet de visualiser les clusters plus efficacement et d'identifier des motifs cachés qui pourraient ne pas être immédiatement apparents dans les données brutes.
Dans cette section, nous explorerons la théorie derrière t-SNE et son implémentation en Python.
Comprendre t-SNE
t-SNE a été introduit par Laurens van der Maaten et Geoffrey Hinton en 2008 comme une méthode pour visualiser des structures de données complexes. Il vise à représenter des points de données de haute dimension dans un espace de dimension inférieure tout en préservant la structure locale et les similarités par paires entre les points de données.
t-SNE y parvient en modélisant la similarité entre les points de données dans l'espace de haute dimension et l'espace de dimension inférieure.
L'algorithme t-SNE
L'algorithme t-SNE procède selon les étapes suivantes :
Calculer les similarités par paires entre les points de données dans l'espace de haute dimension. Cela se fait généralement à l'aide d'un noyau gaussien pour mesurer la similarité basée sur les distances euclidiennes entre les points de données.
Initialiser aléatoirement le plongement (embedding) en basse dimension.
Définir une fonction de coût qui représente la similarité entre les points de données dans l'espace de haute dimension et l'espace de dimension inférieure.
Optimiser la fonction de coût en utilisant la descente de gradient pour minimiser la divergence entre les similarités de haute dimension et de basse dimension.
Itérer les étapes 3 et 4 jusqu'à ce que la fonction de coût converge.
L'implémentation de t-SNE en Python est relativement simple grâce à des bibliothèques telles que scikit-learn. La bibliothèque scikit-learn fournit une API conviviale pour appliquer t-SNE à vos données. En suivant la documentation et les exemples de scikit-learn, vous pouvez facilement incorporer t-SNE dans votre pipeline de machine learning.
Visualisation t-SNE 2D
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.manifold import TSNE
# Charger le dataset
digits = datasets.load_digits()
X, y = digits.data, digits.target
# Appliquer t-SNE
tsne = TSNE(n_components=2, random_state=0)
X_tsne = tsne.fit_transform(X)
# Visualiser les résultats sur un plan 2D
plt.figure(figsize=(10, 6))
scatter = plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=y, edgecolor='none', alpha=0.7, cmap=plt.cm.get_cmap('jet', 10))
plt.colorbar(scatter)
plt.title("t-SNE du dataset Digits")
plt.show()

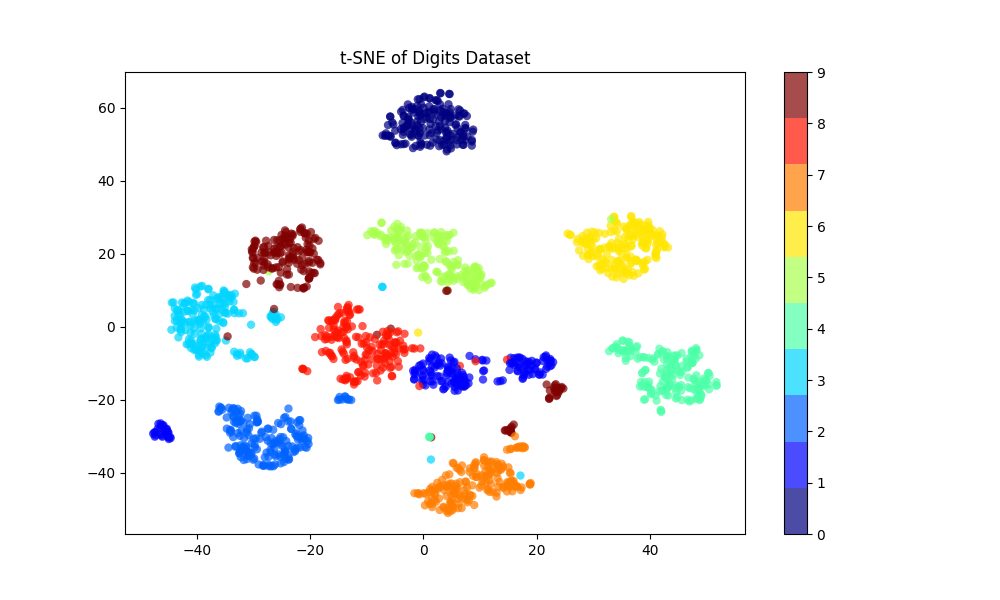
Dans cet exemple :
Nous chargeons le jeu de données
digits.Nous appliquons t-SNE pour réduire les données de 64 dimensions (puisque chaque image fait 8x8) à 2 dimensions.
Nous traçons ensuite les données transformées, en colorant chaque point par son étiquette de chiffre réelle.
La visualisation résultante montrera des clusters, chacun correspondant à l'un des chiffres (de 0 à 9). Cela aide à comprendre à quel point les différents chiffres sont bien séparés dans l'espace original de haute dimension.
Visualisation de données de haute dimension
L'un des principaux avantages de t-SNE est sa capacité à visualiser des données de haute dimension dans un espace de dimension inférieure. En réduisant la dimensionnalité des données, t-SNE nous permet d'identifier des clusters et des motifs qui pourraient ne pas être apparents dans l'espace original de haute dimension. La visualisation résultante peut fournir des informations précieuses sur la structure des données et aider dans les processus de prise de décision.
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.manifold import TSNE
from mpl_toolkits.mplot3d import Axes3D
# Charger le dataset
digits = datasets.load_digits()
X, y = digits.data, digits.target
# Appliquer t-SNE
tsne = TSNE(n_components=3, random_state=0)
X_tsne = tsne.fit_transform(X)
# Visualiser les résultats sur un plan 3D
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, projection='3d')
scatter = ax.scatter(X_tsne[:, 0], X_tsne[:, 1], X_tsne[:, 2], c=y, edgecolor='none', alpha=0.7, cmap=plt.cm.get_cmap('jet', 10))
plt.colorbar(scatter)
plt.title("t-SNE 3D du dataset Digits")
plt.show()

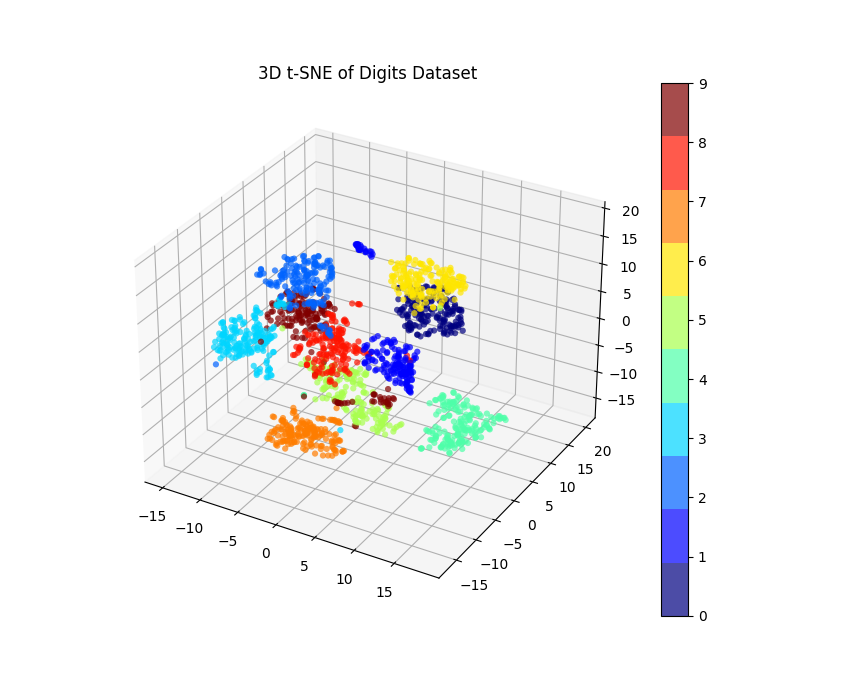
Dans ce code révisé :
Nous définissons
n_components=3pour que t-SNE obtienne une transformation 3D.Nous utilisons
mpl_toolkits.mplot3d.Axes3Dpour créer un graphique de dispersion 3D.
Après l'exécution de ce code, vous verrez un graphique de dispersion 3D où les points sont positionnés en fonction de leurs coordonnées t-SNE, et ils sont colorés en fonction de leur étiquette de chiffre réelle.
Faire pivoter la visualisation 3D peut nous aider à mieux comprendre la distribution spatiale des points de données.
t-SNE est un outil puissant pour la réduction de dimensionnalité et la visualisation de données de haute dimension. En exploitant ses capacités, vous pouvez acquérir une compréhension plus approfondie des jeux de données complexes et découvrir des motifs cachés qui pourraient ne pas être immédiatement évidents. Avec son implémentation en Python et sa facilité d'utilisation, t-SNE est un atout précieux pour tout data scientist ou praticien du machine learning.
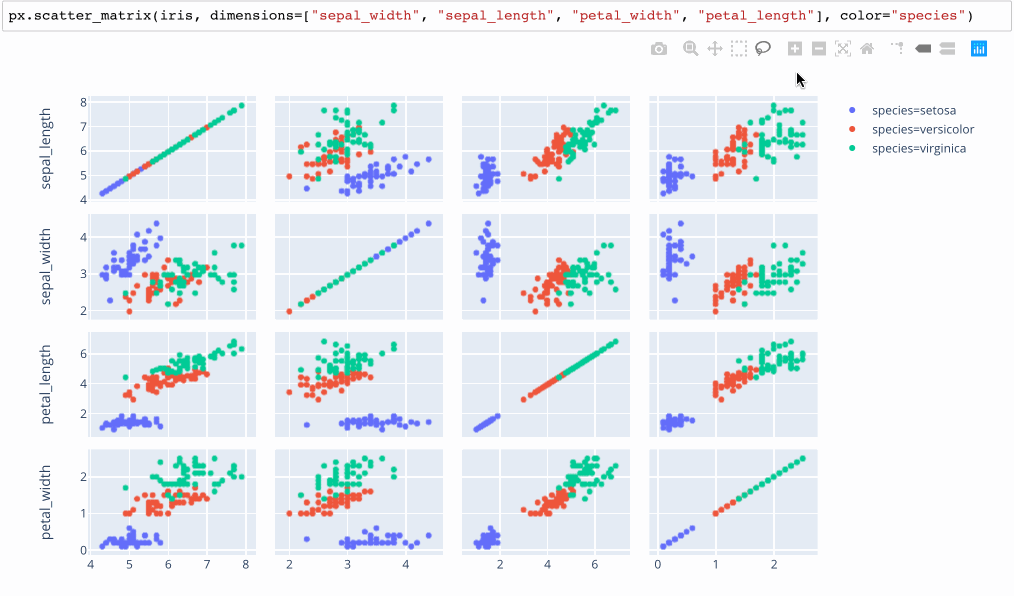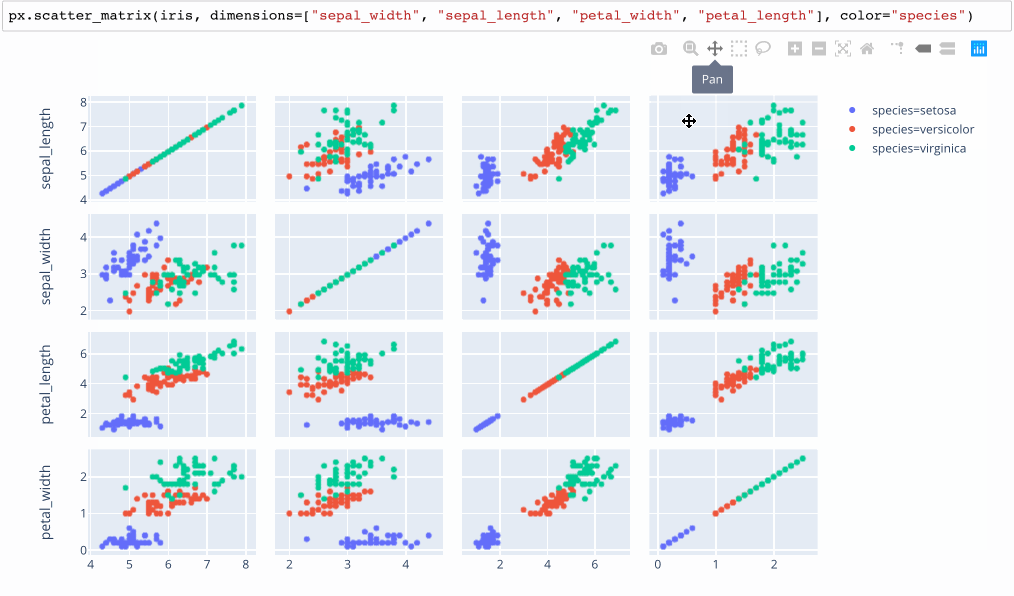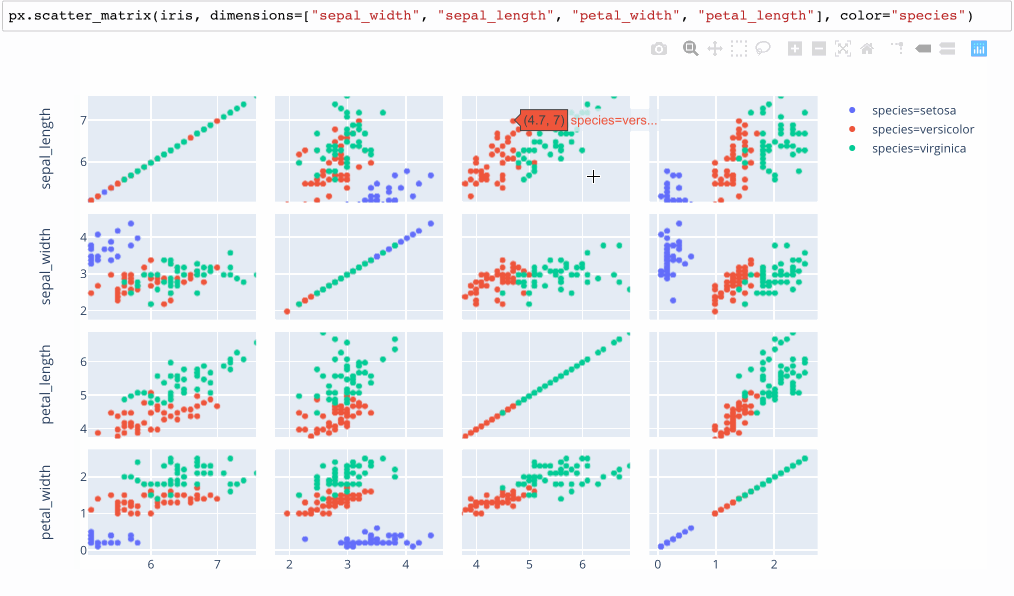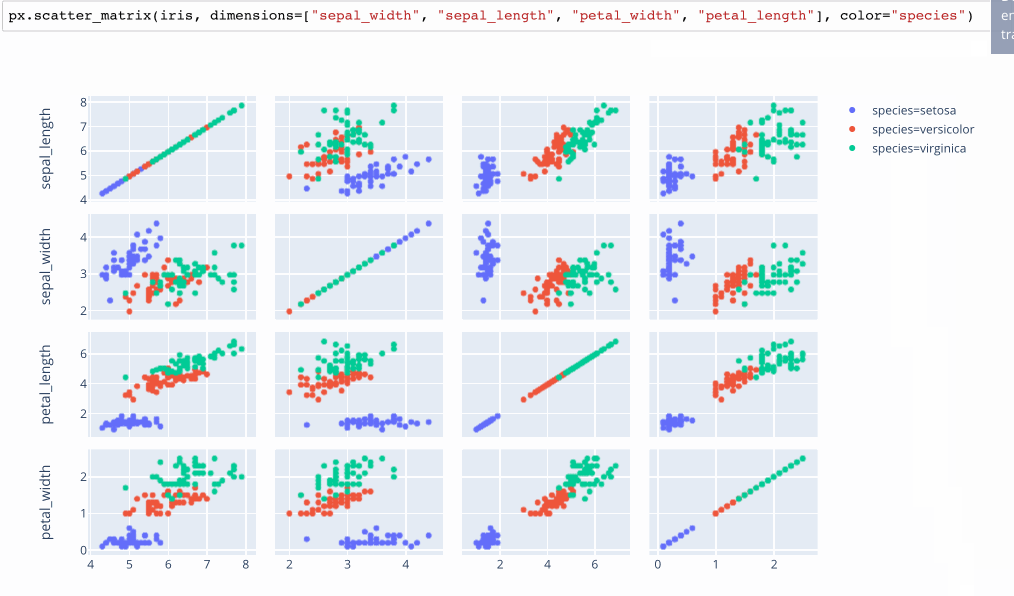
Autres techniques d'apprentissage non supervisé
En plus des techniques de clustering que nous avons abordées ici, il existe d'autres techniques d'apprentissage non supervisé importantes qui valent la peine d'être explorées. Bien que nous ne les approfondissions pas ici, mentionnons brièvement deux de ces techniques : les modèles de mélange et la modélisation thématique.
Modèles de mélange (Mixture Models)
Les modèles de mélange sont des modèles probabilistes utilisés pour modéliser des distributions de données complexes. Ils supposent que le jeu de données global peut être décrit comme une combinaison de plusieurs sous-populations ou composants sous-jacents, chacun décrit par sa propre distribution de probabilité.
Les modèles de mélange peuvent être particulièrement utiles dans les situations où les points de données n'appartiennent pas clairement à des clusters distincts et peuvent présenter des caractéristiques qui se chevauchent.
Modélisation thématique (Topic Modeling)
La modélisation thématique est une technique utilisée pour extraire des thèmes ou des sujets sous-jacents d'une collection de documents. Elle vous permet d'explorer et de découvrir des motifs sémantiques latents dans les données textuelles.
En analysant la cooccurrence des mots dans les documents et en identifiant les thèmes communs, la modélisation thématique permet une catégorisation et un résumé automatiques de grands jeux de données textuelles. Cette technique a des applications dans des domaines tels que le traitement du langage naturel (NLP), la recherche d'information et les systèmes de recommandation de contenu.
Bien que ces techniques méritent une exploration plus approfondie au-delà de la portée de ce manuel, ce sont des outils précieux à considérer pour découvrir des motifs cachés et obtenir des insights de vos données.
N'oubliez pas que la maîtrise de l'apprentissage non supervisé implique un apprentissage et une pratique continus. En vous familiarisant avec différentes techniques comme celles mentionnées ci-dessus, vous serez bien équipé pour aborder un large éventail de problèmes d'analyse de données dans divers domaines.
FAQ
Q : Quelle est la différence entre l'apprentissage supervisé et non supervisé ?
L'apprentissage supervisé consiste à entraîner un modèle sur des données étiquetées, où les entrées sont associées à des sorties correspondantes. L'objectif est de prédire la sortie pour de nouvelles entrées non vues.
En revanche, l'apprentissage non supervisé traite des données non étiquetées, où l'objectif est de découvrir des motifs, des structures ou des clusters au sein des données sans aucune sortie prédéfinie.
Essentiellement, l'apprentissage supervisé vise à apprendre une fonction de correspondance, tandis que l'apprentissage non supervisé se concentre sur la découverte de relations ou de groupements cachés dans les données.
Q : Quel algorithme de clustering est le meilleur pour mes données ?
La pertinence d'un algorithme de clustering dépend de divers facteurs, tels que la nature des données, le nombre de clusters souhaité et le problème spécifique que vous essayez de résoudre.
Dans ce manuel, nous avons discuté de trois algorithmes de clustering couramment utilisés :
K-means est un algorithme populaire qui vise à partitionner les données en K clusters, chaque point de données étant assigné au centroïde le plus proche. Il fonctionne bien pour les clusters sphériques uniformément répartis et nécessite que le nombre de clusters soit spécifié à l'avance.
Le clustering hiérarchique construit une hiérarchie de clusters en les fusionnant ou en les divisant itérativement. Il fournit un dendrogramme pour visualiser le processus de clustering et peut gérer différentes formes et tailles de clusters.
DBSCAN est un algorithme basé sur la densité qui regroupe les points de données proches les uns des autres et sépare les valeurs aberrantes. Il peut découvrir des clusters de forme arbitraire et ne nécessite pas de connaître le nombre de clusters à l'avance.
Pour déterminer le meilleur algorithme pour votre cas d'utilisation, je vous recommande d'expérimenter différentes techniques et d'évaluer leur performance sur la base de métriques telles que la qualité des clusters, l'efficacité computationnelle et l'interprétabilité.
Q : L'apprentissage non supervisé peut-il être utilisé pour l'analyse prédictive ?
Bien que l'apprentissage non supervisé se concentre principalement sur la découverte de motifs et de relations au sein des données sans étiquettes de sortie spécifiques, il peut soutenir indirectement l'analyse prédictive. En découvrant des structures et des clusters cachés au sein des données, l'apprentissage non supervisé peut fournir des informations qui permettent une meilleure ingénierie des caractéristiques (feature engineering), la détection d'anomalies ou la segmentation, ce qui peut par la suite améliorer la performance des modèles prédictifs.
Les techniques d'apprentissage non supervisé comme le clustering peuvent aider à identifier des groupes ou des motifs distincts dans les données, qui peuvent être utilisés comme caractéristiques d'entrée pour les modèles prédictifs ou servir de base pour générer de nouvelles variables prédictives. Ainsi, l'apprentissage non supervisé joue un rôle précieux dans l'analyse prédictive en facilitant une compréhension plus profonde des données et en améliorant la précision et l'efficacité des modèles prédictifs.
Ressources en Data Science et IA
Vous voulez en savoir plus sur une carrière en Data Science, Machine Learning et IA, et apprendre comment décrocher un emploi en Data Science ? Vous pouvez télécharger ce manuel gratuit sur les carrières en Data Science et IA (en anglais).
Vous voulez apprendre le Machine Learning à partir de zéro, ou vous rafraîchir la mémoire ? Téléchargez ce manuel gratuit sur les fondamentaux du Machine Learning (en anglais) pour obtenir tous les fondamentaux du Machine Learning combinés à des exemples en Python en un seul endroit.
À propos de l'auteur
Tatev Aslanyan est ingénieure senior en Machine Learning et IA, PDG et cofondatrice de LunarTech, une startup d'innovation Deep Tech engagée à rendre la Data Science et l'IA accessibles mondialement. Avec plus de 6 ans d'expérience en ingénierie de l'IA et Data Science, Tatev a travaillé aux États-Unis, au Royaume-Uni, au Canada et aux Pays-Bas, appliquant son expertise pour faire progresser les solutions d'IA dans diverses industries.
Tatev détient un MSc et BSc en économétrie et recherche opérationnelle d'universités néerlandaises de premier plan (Universities), et a rédigé plusieurs articles scientifiques en traitement du langage naturel (NLP), machine learning et systèmes de recommandation, publiés dans des revues scientifiques américaines respectées.
En tant que contributrice open-source de premier plan, Tatev a co-écrit des cours et des livres, y compris des ressources sur freeCodeCamp pour 2024, et a joué un rôle pivot dans l'éducation de plus de 30 000 apprenants à travers 144 pays via les programmes de LunarTech.
LunarTech est une entreprise d'innovation Deep Tech qui construit des produits alimentés par l'IA et fournit des outils éducatifs pour aider les entreprises et les personnes à innover, réduisant les coûts opérationnels et augmentant la rentabilité.
Connectez-vous avec nous
Abonnez-vous à la Newsletter LunarTech ou à LENS - Notre chaîne d'actualités
Vous voulez tout découvrir sur une carrière en Data Science, Machine Learning et IA, et apprendre comment décrocher un emploi en Data Science ? Téléchargez ce manuel gratuit sur les carrières en Data Science et IA.
Merci d'avoir choisi ce guide comme compagnon d'apprentissage. Alors que vous continuez à explorer le vaste domaine de l'intelligence artificielle, j'espère que vous le ferez avec confiance, précision et un esprit d'innovation.
Bootcamp d'ingénierie de l'IA par LunarTech
Si vous souhaitez sérieusement devenir ingénieur en IA et que vous voulez un bootcamp tout-en-un qui combine théorie approfondie et pratique concrète, alors consultez le Bootcamp d'ingénierie de l'IA de LunarTech axé sur l'IA générative. Il s'agit d'un programme complet et avancé en ingénierie de l'IA, conçu pour vous équiper de tout ce dont vous avez besoin pour prospérer dans les rôles et industries de l'IA les plus compétitifs.
En seulement 3 à 6 mois (en autonomie ou en cohorte), vous apprendrez l'IA générative et les modèles fondamentaux tels que les VAE, les GAN, les transformers et les LLM. Plongez dans les mathématiques, les statistiques, l'architecture et les nuances techniques de l'entraînement de ces modèles en utilisant des frameworks standards de l'industrie comme PyTorch et TensorFlow.
Le programme comprend le pré-entraînement, le fine-tuning, l'ingénierie de prompt, la quantification et l'optimisation de grands modèles, aux côtés de techniques de pointe telles que la génération augmentée par récupération (RAG).
Ce Bootcamp vous positionne pour combler le fossé entre la recherche et les applications réelles, vous permettant de concevoir des solutions percutantes tout en construisant un portfolio stellaire rempli de projets avancés.
Le programme donne également la priorité à l'éthique de l'IA, vous préparant à créer des modèles durables et éthiques qui s'alignent sur les principes d'une IA responsable. Ce n'est pas juste un cours de plus — c'est un voyage complet conçu pour faire de vous un leader de la révolution de l'IA. Consultez le programme ici
Les places sont limitées et la demande pour des ingénieurs en IA qualifiés est plus élevée que jamais. N'attendez pas — votre avenir en ingénierie de l'IA commence maintenant. Vous pouvez postuler ici.
« Construisons l'avenir ensemble ! » - Tatev Aslanyan, PDG et cofondatrice de LunarTech
La Newsletter Data Science et IA | Tatev Karen | Substack
Vous voulez apprendre le Machine Learning à partir de zéro, ou vous rafraîchir la mémoire ? Téléchargez ce manuel GRATUIT sur les fondamentaux du Machine Learning
Vous voulez tout découvrir sur une carrière en Data Science, Machine Learning et IA, et apprendre comment décrocher un emploi en Data Science ? Téléchargez ce manuel GRATUIT sur les carrières en Data Science et IA.
Merci d'avoir choisi ce guide comme compagnon d'apprentissage. Alors que vous continuez à explorer le vaste domaine du machine learning, j'espère que vous le ferez avec confiance, précision et un esprit d'innovation. Meilleurs vœux dans toutes vos entreprises futures !