

Article original : Learn these quick tricks in PostgreSQL
Par Peter Gleeson
PostgreSQL est l'un des dialectes SQL open source les plus populaires. L'un de ses principaux avantages est la possibilité d'étendre ses fonctionnalités avec certains outils intégrés.
Ici, examinons quelques astuces PostgreSQL que vous pouvez commencer à utiliser pour faire passer vos compétences SQL au niveau supérieur.
Vous découvrirez comment :
- Copier rapidement des fichiers dans une base de données
- Résumer les données au format crosstab
- Tirer parti des tableaux et des données JSON en SQL
- Travailler avec des données géométriques
- Exécuter des analyses statistiques directement sur votre base de données
- Utiliser la récursivité pour résoudre des problèmes
Copier des données à partir d'un fichier
Un moyen simple d'importer rapidement des données à partir d'un fichier externe est d'utiliser la fonction COPY. Créez simplement la table que vous souhaitez utiliser, puis passez le chemin du fichier de votre jeu de données à la commande COPY.
L'exemple ci-dessous crée une table appelée revenue et la remplit à partir d'un fichier CSV généré aléatoirement.
Vous pouvez inclure des paramètres supplémentaires, pour indiquer le type de fichier (ici, le fichier est un CSV) et si vous souhaitez lire la première ligne comme en-têtes de colonne.
Vous pouvez en apprendre plus ici.
CREATE TABLE revenue (
store VARCHAR,
year INT,
revenue INT,
PRIMARY KEY (product, year)
);
COPY revenue FROM '~/Projects/datasets/revenue.csv' WITH HEADER CSV;
Résumer les données en utilisant la fonction crosstab
Si vous vous considérez comme un pro des feuilles de calcul, vous êtes probablement familier avec la création de tableaux croisés dynamiques à partir de données brutes. Vous pouvez faire de même dans PostgreSQL avec la fonction crosstab.
La fonction crosstab peut prendre des données sous la forme de gauche, et les résumer sous la forme de droite (qui est beaucoup plus facile à lire). L'exemple ici suivra avec les données de revenus d'avant.

Tout d'abord, activez l'extension tablefunc avec la commande suivante :
CREATE EXTENSION tablefunc;
Ensuite, écrivez une requête utilisant la fonction crosstab :
SELECT * FROM CROSSTAB(
'SELECT
*
FROM revenue
ORDER BY 1,2'
)
AS summary(
store VARCHAR,
"2016" INT,
"2017" INT,
"2018" INT
);
Il y a deux choses à considérer lors de l'utilisation de cette fonction.
- Tout d'abord, passez une requête sélectionnant des données à partir de votre table sous-jacente. Vous pouvez simplement sélectionner la table telle quelle (comme montré ici). Cependant, vous pourriez vouloir filtrer, joindre ou agréger si nécessaire. Assurez-vous de trier les données correctement.
- Ensuite, définissez la sortie (dans l'exemple, la sortie est appelée 'summary', mais vous pouvez l'appeler n'importe quel nom). Listez les en-têtes de colonne que vous souhaitez utiliser et le type de données qu'ils contiendront.
La sortie sera comme montré ci-dessous :
store | 2016 | 2017 | 2018
---------+---------+---------+---------
Alpha | 1637000 | 2190000 | 3287000
Bravo | 2205000 | 982000 | 3399000
Charlie | 1549000 | 1117000 | 1399000
Delta | 664000 | 2065000 | 2931000
Echo | 1795000 | 2706000 | 1047000
(5 rows)
Travailler avec des tableaux et JSON
PostgreSQL supporte les types de données de tableaux multidimensionnels. Ceux-ci sont comparables à des types de données similaires dans de nombreux autres langages, y compris Python et JavaScript.

Vous pourriez vouloir les utiliser dans des situations où il est utile de travailler avec des données plus dynamiques et moins structurées.
Par exemple, imaginez une table décrivant des articles publiés et des tags de sujet. Un article pourrait n'avoir aucun tag, ou il pourrait en avoir beaucoup. Essayer de stocker ces données dans un format de table structuré serait inutilement compliqué.
Vous pouvez définir des tableaux en utilisant un type de données, suivi de crochets. Vous pouvez optionnellement spécifier leurs dimensions (cependant, cela n'est pas imposé).
Par exemple, pour créer un tableau 1-D de n'importe quel nombre d'éléments de texte, vous utiliseriez text[]. Pour créer un tableau à deux dimensions de trois par trois éléments entiers, vous utiliseriez int[3][3].
Jetez un coup d'œil à l'exemple ci-dessous :
CREATE TABLE articles (
title VARCHAR PRIMARY KEY,
tags TEXT[]
);
Pour insérer des tableaux comme enregistrements, utilisez la syntaxe '{"first","second","third"}'.
INSERT INTO articles (title, tags)
VALUES
('Lorem ipsum', '{"random"}'),
('Placeholder here', '{"motivation","random"}'),
('Postgresql tricks', '{"data","self-reference"}');
Il y a beaucoup de choses que vous pouvez faire avec des tableaux dans PostgreSQL.
Pour commencer, vous pouvez vérifier si un tableau contient un élément donné. Cela est utile pour le filtrage. Vous pouvez utiliser l'opérateur "contient" @> pour faire cela. La requête ci-dessous trouve tous les articles qui ont le tag "random".
SELECT
*
FROM articles
WHERE tags @> '{"random"}';
Vous pouvez également concaténer (joindre ensemble) des tableaux en utilisant l'opérateur ||, ou vérifier les éléments chevauchants avec l'opérateur &&.
Vous pouvez rechercher des tableaux par index (contrairement à de nombreux langages, les tableaux PostgreSQL commencent à compter à partir de un, au lieu de zéro).
SELECT
tags[1]
FROM articles;
En plus des tableaux, PostgreSQL vous permet également d'utiliser JSON comme type de données. Encore une fois, cela offre les avantages de travailler avec des données non structurées. Vous pouvez également accéder aux éléments par leur nom de clé.
CREATE TABLE sessions (
session_id SERIAL PRIMARY KEY,
session_info JSON
);
INSERT INTO sessions (session_info)
VALUES
('{"app_version": 1.0, "device_type": "Android"}'),
('{"app_version": 1.2, "device_type": "iOS"}'),
('{"app_version": 1.4, "device_type": "iOS", "mode":"default"}');
Encore une fois, il y a beaucoup de choses que vous pouvez faire avec les données JSON dans PostgreSQL. Vous pouvez utiliser les opérateurs -> et ->> pour "déballer" les objets JSON à utiliser dans les requêtes.
Par exemple, cette requête trouve les valeurs de la clé device_type :
SELECT
session_info -> 'device_type' AS devices
FROM sessions;
Et cette requête compte combien de sessions étaient sur la version 1.0 ou antérieure de l'application :
SELECT
COUNT(*)
FROM sessions
WHERE CAST(session_info ->> 'app_version' AS decimal) <= 1.0;
Exécuter des analyses statistiques
Souvent, les gens voient SQL comme bon pour stocker des données et exécuter des requêtes simples, mais pas pour exécuter des analyses plus approfondies. Pour cela, vous devriez utiliser un autre outil tel que Python ou R ou votre logiciel de feuille de calcul préféré.
Cependant, PostgreSQL apporte avec lui suffisamment de capacités statistiques pour vous permettre de commencer.
Par exemple, il peut calculer des statistiques récapitulatives, des corrélations, des régressions et des échantillonnages aléatoires. Le tableau ci-dessous contient quelques données simples pour jouer avec.
CREATE TABLE stats (
sample_id SERIAL PRIMARY KEY,
x INT,
y INT
);
INSERT INTO stats (x,y)
VALUES
(1,2), (3,4), (6,5), (7,8), (9,10);
Vous pouvez trouver la moyenne, la variance et l'écart type en utilisant les fonctions ci-dessous :
SELECT
AVG(x),
VARIANCE(x),
STDDEV(x)
FROM stats;
Vous pouvez également trouver la médiane (ou toute autre valeur de percentile) en utilisant la fonction percentile_cont :
-- median
SELECT
PERCENTILE_CONT(0.5)
WITHIN GROUP (ORDER BY x)
FROM stats;
-- 90th percentile
SELECT
PERCENTILE_CONT(0.9)
WITHIN GROUP (ORDER BY x)
FROM stats;
Une autre astuce vous permet de calculer les coefficients de corrélation entre différentes colonnes. Utilisez simplement la fonction corr.
SELECT
CORR(x,y)
FROM stats;
PostgreSQL vous permet d'exécuter une régression linéaire (parfois appelée la forme la plus basique de l'apprentissage automatique) via un ensemble de fonctions intégrées.
SELECT
REGR_INTERCEPT(x,y),
REGR_SLOP(x,y),
REGR_R2(x,y)
FROM stats;
Vous pouvez même exécuter des simulations de Monte Carlo avec des requêtes simples. La requête ci-dessous utilise les fonctions generate_series et random number pour estimer la valeur de π en échantillonnant aléatoirement un million de points à l'intérieur d'un cercle unité.
SELECT
CAST(
COUNT(*) * 4 AS FLOAT
) / 1000000 AS pi
FROM GENERATE_SERIES(1,1000000)
WHERE CIRCLE(POINT(0.5,0.5),0.5) @> POINT(RANDOM(), RANDOM());
Travailler avec des données de forme
Un autre type de données inhabituel disponible dans PostgreSQL est les données géométriques.
Oui, vous pouvez travailler avec des points, des lignes, des polygones et des cercles dans SQL.
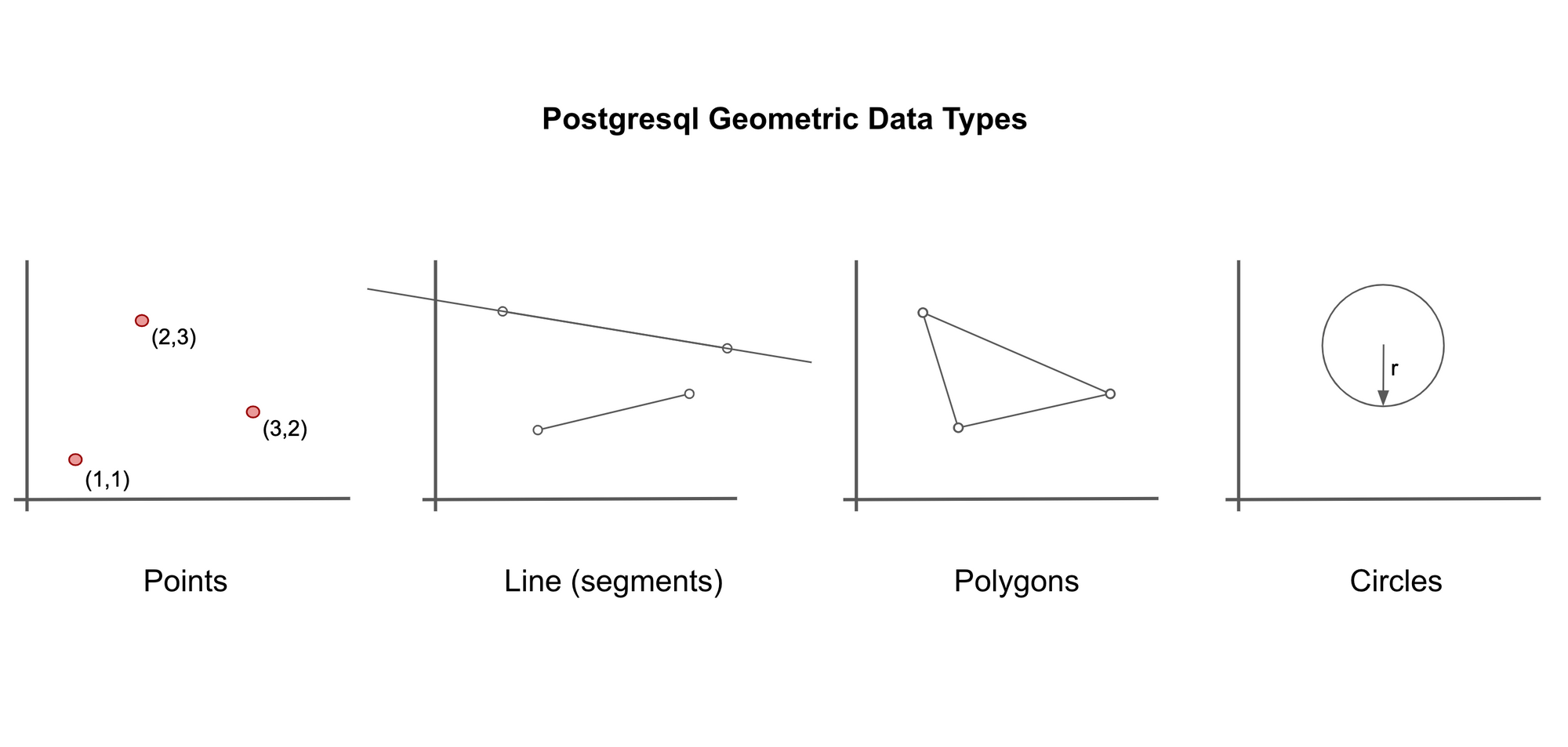
Les points sont le bloc de construction de base pour tous les types de données géométriques dans PostgreSQL. Ils sont représentés comme des coordonnées (x, y).
SELECT
POINT(0,0) AS "origin",
POINT(1,1) AS "point";
Vous pouvez également définir des lignes. Celles-ci peuvent être des lignes infinies (spécifiées en donnant deux points quelconques sur la ligne). Ou, elles peuvent être des segments de ligne (spécifiés en donnant les points de 'début' et de 'fin' de la ligne).
SELECT
LINE '((0,0),(1,1))' AS "line",
LSEG '((2,2),(3,3))' AS "line_segment";
Les polygones sont définis par une série plus longue de points.
SELECT
POLYGON '((0,0),(1,1),(0,2))' AS "triangle",
POLYGON '((0,0),(0,1),(1,1),(1,0))' AS "square",
POLYGON '((0,0),(0,1),(2,1),(2,0))' AS "rectangle";
Les cercles sont définis par un point central et un rayon.
SELECT
CIRCLE '((0,0),1)' as "small_circle",
CIRCLE '(0,0),5)' as "big_circle";
Il existe de nombreuses fonctions et opérateurs qui peuvent être appliqués aux données géométriques dans PostgreSQL.
Vous pouvez :
- Vérifier si deux lignes sont parallèles avec l'opérateur
?||:
SELECT
LINE '((0,0),(1,1))' ?|| LINE '((2,3),(3,4))';
- Trouver la distance entre deux objets avec l'opérateur
<->:
SELECT
POINT(0,0) <-> POINT(1,1);
- Vérifier si deux formes se chevauchent à un point quelconque avec l'opérateur
&&:
SELECT
CIRCLE '((0,0),1)' && CIRCLE '((1,1),1)';
- Translater (déplacer la position) une forme en utilisant l'opérateur
+:
SELECT
POLYGON '((0,0),(1,2),(1,1))' + POINT(0,3);
Et bien plus encore - consultez la documentation pour plus de détails !
Utiliser des requêtes récursives
La récursivité est une technique de programmation qui peut être utilisée pour résoudre des problèmes en utilisant une fonction qui s'appelle elle-même. Saviez-vous que vous pouvez écrire des requêtes récursives dans PostgreSQL ?
Il y a trois parties nécessaires pour faire cela :
- Tout d'abord, vous définissez une expression de départ.
- Ensuite, définissez une expression récursive qui sera évaluée de manière répétée.
- Enfin, définissez un "critère de terminaison" - une condition qui indique à la fonction de cesser de s'appeler elle-même et de retourner une sortie.
La requête ci-dessous retourne les cent premiers nombres de la suite de Fibonacci :
WITH RECURSIVE fibonacci(n,x,y) AS (
SELECT
1 AS n ,
0 :: NUMERIC AS x,
1 :: NUMERIC AS y
UNION ALL
SELECT
n + 1 AS n,
y AS x,
x + y AS y
FROM fibonacci
WHERE n < 100
)
SELECT
x
FROM fibonacci;
Décomposons cela.
Tout d'abord, il utilise la clause WITH pour définir une Expression de Table Commune récursive appelée fibonacci. Ensuite, il définit une expression initiale :
WITH RECURSIVE fibonacci(n,x,y) AS (
SELECT
1 AS n ,
0 :: NUMERIC AS x,
1 :: NUMERIC AS y...
Ensuite, il définit l'expression récursive qui interroge fibonacci :
...UNION ALL
SELECT
n + 1 AS n,
y AS x,
x + y AS y
FROM fibonacci...
Enfin, il utilise une clause WHERE pour définir le critère de terminaison, puis sélectionne la colonne x pour donner la séquence de sortie :
...WHERE n < 100
)
SELECT
x
FROM fibonacci;
Peut-être pouvez-vous penser à un autre exemple de récursivité qui pourrait être implémenté dans PostgreSQL ?
Remarques finales
Donc, voilà - un rapide aperçu de certaines grandes fonctionnalités que vous connaissiez peut-être ou non que PostgreSQL pouvait offrir. Il y a sans doute plus de fonctionnalités qui méritent d'être couvertes et qui n'ont pas fait partie de cette liste.
PostgreSQL est un langage de programmation riche et puissant à part entière. Donc, la prochaine fois que vous êtes bloqué en essayant de résoudre un problème lié aux données, jetez un coup d'œil et voyez si PostgreSQL vous couvre. Vous pourriez être surpris de la fréquence à laquelle il le fait !
Merci d'avoir lu !