

Lorsque j'ai changé de carrière, passant de juriste à ingénieur logiciel en 2018, je n'aurais jamais imaginé que je prendrais autant de plaisir à être développeur. Je n'aurais également jamais pensé que je finirais par travailler pour des organisations incroyables comme Google et Chainlink Labs.
Après 15 ans dans le droit et d'autres rôles, j'avais expérimenté un certain nombre d'emplois, de pays, d'entreprises et de parcours professionnels. Aucun d'entre eux ne pouvait rivaliser avec la joie et l'excitation que je ressens en codant.
L'inconvénient ? L'acquisition de nouvelles compétences en codage peut être confuse, frustrante et chronophage. Et il est facile d'oublier certains détails mineurs mais importants.
J'ai donc écrit ce guide. Il est conçu pour vous faire démarrer le codage en Solidity dès que possible. Il suit le principe de Pareto (aka la règle 80/20) en se concentrant sur les 20 % d'informations qui couvriront 80 % de vos besoins.
J'ai commencé à rassembler ces concepts lorsque j'apprenais Solidity, dans le cadre de mon rôle chez Chainlink Labs. J'ai appliqué de nombreuses techniques d'auto-apprentissage que j'ai apprises lors de ma transition vers le codage à l'âge de 38 ans.
C'est la ressource que j'aurais aimé avoir. Elle est conçue pour donner aux développeurs débutants et intermédiaires des modèles mentaux solides à accumuler à mesure que vous approfondissez le langage (les modèles mentaux accélèrent massivement l'apprentissage efficace).
Je vais garder ce guide à jour, mais j'aurais vraiment besoin de votre aide ! Il suffit de me tweeter @ZubinPratap pour me faire savoir si je dois mettre à jour ce guide.
Je tiens à remercier mes incroyables collègues Kevin Ryu, Andrej Rakic, Patrick Collins et Richard Gottleber pour leurs précieux conseils et contributions à ce guide.
Table des matières
Comment déclarer des variables et des fonctions en Solidity ?
Comment travailler avec les nombres à virgule flottante en Solidity
Comment appeler des contrats et utiliser la fonction de repli
À qui s'adresse ce guide ?
Ce guide s'adresse aux personnes intéressées par l'exploration de la vision derrière le "Web3", et qui souhaitent acquérir des compétences recherchées essentielles à la réalisation de cette vision.
Ne le mémorisez pas ! Lisez-le et utilisez-le ensuite comme un "guide de référence" de bureau. À mesure que vous apprenez un nouveau langage, vous constaterez que les concepts, les idiomes et l'utilisation peuvent devenir un peu confus ou que votre mémoire s'estompe avec le temps. Ce n'est pas grave ! C'est ce pour quoi ce guide est conçu pour vous aider.
Avec le temps, je pourrais ajouter des sujets plus avancés à ce guide, ou créer un tutoriel séparé. Mais pour l'instant, ce guide vous apportera la plupart des résultats dont vous avez besoin pour construire vos premières applications décentralisées Solidity.
Ce guide suppose que vous avez au moins quelques mois d'expérience en programmation. Par programmation, j'entends au minimum que vous avez écrit en JavaScript ou Python ou dans un langage compilé (puisque HTML et CSS ne sont pas vraiment des langages de "programmation", il ne suffira pas de les connaître uniquement).
Les seules autres exigences sont que vous soyez curieux, engagé et que vous ne vous fixiez pas de délais arbitraires.
Tant que vous avez un ordinateur portable et un navigateur avec une connexion internet, vous pourrez exécuter le code Solidity. Vous pouvez utiliser Remix dans votre navigateur pour écrire le code de ce guide. Aucun autre IDE requis !
Connaissances préalables essentielles
J'ai également supposé que vous connaissez les bases de la technologie blockchain, et en particulier que vous comprenez les bases d'Ethereum et ce que sont les contrats intelligents (indice : ce sont des programmes qui s'exécutent sur les blockchains et offrent donc des avantages spéciaux de minimisation de la confiance !).
Il est peu probable que vous en ayez besoin pour comprendre ce guide. Mais en pratique, avoir un portefeuille de navigateur comme Metamask et comprendre la différence entre les comptes de contrat Ethereum et les comptes détenus en externe vous aidera à tirer le meilleur parti de ce guide.
Qu'est-ce que Solidity ?
Maintenant, commençons par comprendre ce qu'est Solidity. Solidity est un langage de programmation orienté objet influencé par C++, JavaScript et Python.
Solidity est conçu pour être compilé (converti du code lisible par l'homme en code lisible par la machine) en bytecode qui s'exécute sur la machine virtuelle Ethereum (EVM). C'est l'environnement d'exécution pour le code Solidity, tout comme votre navigateur est un environnement d'exécution pour le code JavaScript.
Ainsi, vous écrivez le code du contrat intelligent en Solidity, et le compilateur le convertit en bytecode. Ensuite, ce bytecode est déployé et stocké sur Ethereum (et d'autres blockchains compatibles EVM).
Vous pouvez obtenir une introduction de base à l'EVM et au bytecode dans cette vidéo que j'ai réalisée.
Qu'est-ce qu'un contrat intelligent ?
Voici un contrat intelligent simple qui fonctionne dès sa sortie de la boîte. Il peut ne pas sembler utile, mais vous allez comprendre beaucoup de choses sur Solidity rien qu'avec cela !
Lisez-le avec chaque commentaire pour avoir une idée de ce qui se passe, puis passez à quelques apprentissages clés.
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.8.0;
contract HotFudgeSauce {
uint public qtyCups;
// Obtenir la quantité actuelle de sauce au chocolat chaud
function get() public view returns (uint) {
return qtyCups;
}
// Incrémenter la quantité de sauce au chocolat chaud de 1
function increment() public {
qtyCups += 1; // même que qtyCups = qtyCups + 1;
}
// Fonction pour décrémenter le compte de 1
function decrement() public {
qtyCups -= 1; // même que qtyCups = qtyCups - 1;
// Que se passe-t-il si qtyCups = 0 lorsque cette fonction est appelée ?
}
}
Nous aborderons certains détails comme ce que signifient public et view sous peu.
Pour l'instant, tirez sept enseignements clés de l'exemple ci-dessus :
- Le premier commentaire est une ligne lisible par machine (
// SPDX-License-Identifier: MIT) qui spécifie la licence couvrant le code.
Les identifiants de licence SPDX sont fortement recommandés, bien que votre code se compilera sans eux. Lisez plus ici. Vous pouvez également ajouter un commentaire ou "commenter" (supprimer) toute ligne en la préfixant avec deux barres obliques "//".
- La directive
pragmadoit être la première ligne de code dans tout fichier Solidity. Pragma est une directive qui indique au compilateur quelle version du compilateur il doit utiliser pour convertir le code Solidity lisible par l'homme en bytecode lisible par la machine.
Solidity est un nouveau langage et est fréquemment mis à jour, donc différentes versions du compilateur produisent différents résultats lors de la compilation du code. Certains fichiers Solidity plus anciens généreront des erreurs ou des avertissements lorsqu'ils sont compilés avec une version plus récente du compilateur.
Dans les grands projets, lorsque vous utilisez des outils comme Hardhat, vous devrez peut-être spécifier plusieurs versions de compilateur car les fichiers Solidity importés ou les bibliothèques dont vous dépendez ont été écrits pour des versions plus anciennes de Solidity. Lisez plus sur la directive pragma de Solidity ici.
La directive
pragmasuit la version sémantique (SemVer) - un système où chacun des nombres signifie le type et l'étendue des changements contenus dans cette version. Si vous voulez une explication pratique de SemVer, consultez ce tutoriel - il est très utile à comprendre et il est largement utilisé dans le développement (surtout le développement web) de nos jours.Les points-virgules sont essentiels en Solidity. Le compilateur échouera si même un seul est manquant. Remix vous alertera !
Le mot-clé
contractindique au compilateur que vous déclarez un contrat intelligent. Si vous êtes familier avec la programmation orientée objet, vous pouvez penser aux contrats comme étant similaires aux classes.
Si vous n'êtes pas familier avec la POO, pensez aux contrats comme étant des objets qui contiennent des données - à la fois des variables et des fonctions. Vous pouvez combiner des contrats intelligents pour donner à votre application blockchain la fonctionnalité dont elle a besoin.
- Les fonctions sont des unités exécutables de code qui encapsulent des idées uniques, des fonctionnalités spécifiques, des tâches, etc. En général, nous voulons que les fonctions fassent une chose à la fois.
Les fonctions sont le plus souvent vues à l'intérieur des contrats intelligents, bien qu'elles puissent être déclarées dans le fichier en dehors du bloc de code du contrat intelligent. Les fonctions peuvent prendre 0 ou plusieurs arguments et peuvent retourner 0 ou plusieurs valeurs. Les entrées et les sorties sont typées statiquement, un concept que vous apprendrez plus tard dans ce guide.
- Dans l'exemple ci-dessus, la variable
qtyCupsest appelée une "variable d'état". Elle contient l'état du contrat - qui est le terme technique pour les données que le programme doit suivre pour fonctionner.
Contrairement à d'autres programmes, les applications de contrats intelligents conservent leur état même lorsque le programme ne s'exécute pas. Les données sont stockées dans la blockchain, avec l'application, ce qui signifie que chaque nœud du réseau blockchain maintient et synchronise une copie locale des données et des contrats intelligents sur la blockchain.
Les variables d'état sont comme le "stockage" de la base de données dans une application traditionnelle, mais comme les blockchains doivent synchroniser l'état sur tous les nœuds du réseau, l'utilisation du stockage peut être assez coûteuse ! Plus sur cela plus tard.
Comment déclarer des variables et des fonctions en Solidity
Décomposons ce contrat intelligent HotFudgeSauce pour comprendre chaque petit élément.
La structure/syntaxe de base pour définir des éléments en Solidity est similaire à celle des autres langages typés statiquement. Nous donnons un nom aux fonctions et aux variables.
Mais dans les langages typés, nous devons également spécifier le type des données créées, passées en entrée ou retournées en sortie. Vous pouvez sauter à la section Typage des données dans ce guide si vous devez comprendre ce qu'est le typage des données.
Ci-dessous, nous voyons à quoi ressemble la déclaration d'une "variable d'état". Nous voyons également à quoi ressemble la déclaration d'une fonction.
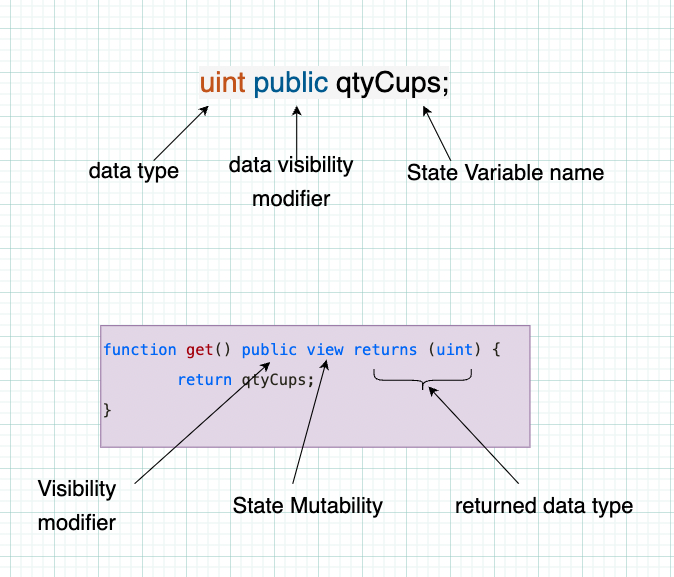
Le premier extrait déclare une variable d'état (je vais expliquer ce que c'est bientôt, je promets) appelée qtyCups. Cela ne peut stocker que des valeurs de type uint, ce qui signifie des entiers non signés. "Integer" fait référence à tous les nombres entiers en dessous de zéro (négatifs) et au-dessus de zéro (positifs).
Puisque ces nombres ont un signe + ou - attaché, ils sont appelés entiers signés. Un entier non signé est donc toujours un entier positif (y compris zéro).
Dans le deuxième extrait, nous voyons une structure familière lorsque nous déclarons également des fonctions. Plus important encore, nous voyons que les fonctions doivent spécifier un type de données pour la valeur que la fonction retourne.
Dans cet exemple, puisque get() retourne la valeur de la variable de stockage que nous venons de créer, nous pouvons voir que la valeur retournée doit être un uint.
public est un spécificateur de visibilité. Plus sur cela plus tard. view est un modificateur de mutabilité d'état. Plus sur cela aussi !
Il est intéressant de noter ici que les variables d'état peuvent également être d'autres types - constant et immutable. Elles ressemblent à ceci :
string constant TEXT = "abc";
address immutable owner = 0xD4a33860578De61DBAbDc8BFdb98FD742fA7028e;
Les constantes et les variables immuables ont leurs valeurs assignées une fois, et une seule fois. Elles ne peuvent pas recevoir une autre valeur après que leur première valeur a été assignée.
Ainsi, si nous avions rendu la variable d'état qtyCups soit constante soit immuable, nous ne pourrions plus appeler les fonctions increment() ou decrement() sur elle (en fait, le code ne se compilerait pas !).
Les constantes doivent avoir leurs valeurs codées en dur dans le code lui-même, tandis que les variables immuables peuvent avoir leurs valeurs définies une fois, généralement par assignation dans la fonction constructeur (nous parlerons des fonctions constructeur très bientôt, je promets). Vous pouvez lire plus dans la documentation ici.
Portée des variables dans les contrats intelligents
Il existe trois portées de variables auxquelles les contrats intelligents ont accès :
Variables d'état : stockent des données permanentes dans le contrat intelligent (appelées état persistant) en enregistrant les valeurs sur la blockchain.
Variables locales : ce sont des morceaux de données "transitoires" qui conservent des informations pendant de courtes périodes lors de l'exécution de calculs. Ces valeurs ne sont pas stockées de manière permanente sur la blockchain.
Variables globales : ces variables et fonctions sont "injectées" dans votre code par Solidity, et mises à disposition sans avoir besoin de les créer ou de les importer spécifiquement. Elles fournissent des informations sur l'environnement de la blockchain dans lequel le code s'exécute et incluent également des fonctions utilitaires pour une utilisation générale dans le programme.
Vous pouvez distinguer les portées comme suit :
Les variables d'état sont généralement trouvées à l'intérieur du contrat intelligent mais à l'extérieur d'une fonction.
Les variables locales sont trouvées à l'intérieur des fonctions et ne peuvent pas être accessibles depuis l'extérieur de la portée de cette fonction.
Les variables globales ne sont pas déclarées par vous - elles sont "magiquement" disponibles pour que vous les utilisiez.
Voici notre exemple HotFudgeSauce, légèrement modifié pour montrer les différents types de variables. Nous donnons à qtyCups une valeur de départ et nous distribuons des tasses de sauce au chocolat à tout le monde sauf à moi (parce que je suis au régime).

Comment fonctionnent les spécificateurs de visibilité
L'utilisation du mot "visibilité" est un peu trompeuse car sur une blockchain publique, presque tout est "visible" car la transparence est une caractéristique clé. Mais la visibilité, dans ce contexte, signifie la capacité d'un morceau de code à être vu et accessible par un autre morceau de code.
La visibilité spécifie dans quelle mesure une variable, une fonction ou un contrat peut être accessible depuis l'extérieur de la région de code où elle a été définie. La portée de la visibilité peut être ajustée en fonction des parties du système logiciel qui doivent y accéder.
Si vous êtes un développeur JavaScript ou NodeJS, vous êtes déjà familier avec la visibilité - chaque fois que vous exportez un objet, vous le rendez visible en dehors du fichier où il est déclaré.
Types de visibilité
En Solidity, il existe 4 types différents de visibilité : public, external, internal et private.
Les fonctions et variables publiques peuvent être accessibles à l'intérieur du contrat, à l'extérieur, depuis d'autres contrats intelligents, et depuis des comptes externes (ceux qui se trouvent dans votre portefeuille Metamask) - pratiquement depuis n'importe où. C'est le niveau de visibilité le plus large et le plus permissif.
Lorsque qu'une variable de stockage est donnée une visibilité public, Solidity crée automatiquement une fonction getter implicite pour la valeur de cette variable.
Ainsi, dans notre contrat intelligent HotFudgeSauce, nous n'avons pas vraiment besoin d'avoir la méthode get(), car Solidity nous fournira implicitement une fonctionnalité identique, simplement en donnant à qtyCups un modificateur de visibilité public.
Les fonctions et variables privées ne sont accessibles qu'à l'intérieur du contrat intelligent qui les déclare. Mais elles ne peuvent pas être accessibles en dehors du contrat intelligent qui les englobe. private est le plus restrictif des quatre spécificateurs de visibilité.
La visibilité interne est similaire à la visibilité private, dans le sens où les fonctions et variables internes ne peuvent être accessibles qu'à partir du contrat qui les déclare. Mais les fonctions et variables marquées internes peuvent également être accessibles à partir des contrats dérivés (c'est-à-dire les contrats enfants qui héritent du contrat déclarant) mais pas depuis l'extérieur du contrat. Nous parlerons de l'héritage (et des contrats dérivés/enfants) plus tard.
internal est la visibilité par défaut pour les variables de stockage.
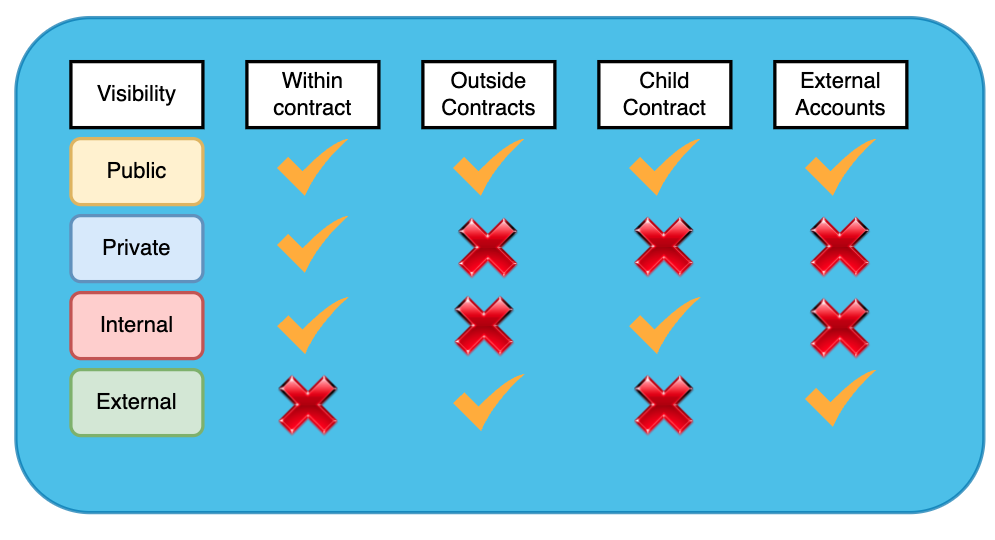
Les 4 spécificateurs de visibilité Solidity et d'où ils peuvent être accessibles
Le spécificateur de visibilité externe ne s'applique pas aux variables - seules les fonctions peuvent être spécifiées comme externes.
Les fonctions externes ne peuvent pas être appelées depuis l'intérieur du contrat déclarant ou des contrats qui héritent du contrat déclarant. Ainsi, elles ne peuvent être appelées que depuis l'extérieur du contrat englobant.
Et c'est ainsi qu'elles diffèrent des fonctions publiques - les fonctions publiques peuvent également être appelées depuis l'intérieur du contrat qui les déclare, alors qu'une fonction externe ne le peut pas.
Qu'est-ce que les constructeurs ?
Un constructeur est un type spécial de fonction. En Solidity, il est facultatif et n'est exécuté qu'une seule fois lors de la création du contrat.
Dans l'exemple suivant, nous avons un constructeur explicite et il accepte certaines données en tant que paramètre. Ce paramètre de constructeur doit être injecté par vous dans votre contrat intelligent au moment où vous le créez.
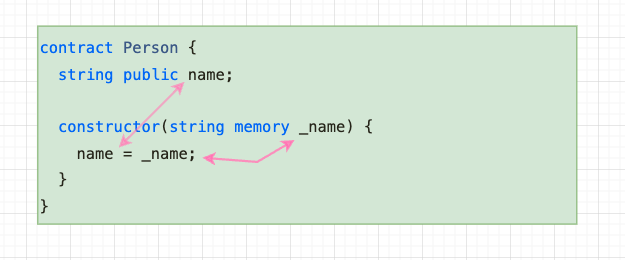
Fonction constructeur Solidity avec paramètre d'entrée
Pour comprendre quand la fonction constructeur est appelée, il est utile de se rappeler qu'un contrat intelligent est créé en plusieurs phases :
il est compilé en bytecode (vous pouvez en savoir plus sur le bytecode ici). Cette phase est appelée "temps de compilation".
il est créé (construit) - c'est à ce moment que le constructeur entre en action. Cela peut être appelé "temps de construction".
Le bytecode est ensuite déployé sur la blockchain. C'est le "déploiement".
Le bytecode du contrat intelligent déployé est exécuté (exécuté) sur la blockchain. Cela peut être considéré comme "l'exécution".
En Solidity, contrairement à d'autres langages, le programme (contrat intelligent) n'est déployé qu'après que le constructeur ait fait son travail de création du contrat intelligent.
Intéressamment, en Solidity, le bytecode finalement déployé n'inclut pas le code du constructeur. Cela est dû au fait qu'en Solidity, le code du constructeur fait partie du code de création (temps de construction) et non du code d'exécution. Il est utilisé lors de la création du contrat intelligent, et comme il n'est appelé qu'une seule fois, il n'est pas nécessaire au-delà de cette phase, et est exclu du bytecode finalement déployé.
Ainsi, dans notre exemple, le constructeur crée (construit) une instance du contrat intelligent Person. Notre constructeur attend que nous lui passions une valeur de chaîne appelée _name.
Lorsque le contrat intelligent est en cours de construction, cette valeur de _name sera stockée dans la variable d'état appelée name (c'est souvent ainsi que nous passons la configuration et d'autres données dans le contrat intelligent). Ensuite, lorsque le contrat est effectivement déployé, la variable d'état name contiendra la valeur de chaîne que nous avons passée dans notre constructeur.
Comprendre le pourquoi
Vous pourriez vous demander pourquoi nous nous donnons la peine d'injecter des valeurs dans le constructeur. Pourquoi ne pas simplement les écrire dans le contrat ?
C'est parce que nous voulons que les contrats soient configurables ou "paramétrés". Plutôt que de coder en dur les valeurs, nous voulons la flexibilité et la réutilisabilité qui viennent avec l'injection de données au fur et à mesure de nos besoins.
Dans notre exemple, supposons que _name fait référence au nom d'un réseau Ethereum donné sur lequel le contrat va être déployé (comme Rinkeby, Goerli, Kovan, Mainnet, etc.).
Comment pourrions-nous donner cette information à notre contrat intelligent ? Mettre toutes ces valeurs dedans serait du gaspillage. Cela signifierait également que nous devons ajouter du code supplémentaire pour déterminer sur quelle blockchain le contrat s'exécute. Ensuite, nous devrions choisir le bon nom de réseau à partir d'une liste codée en dur que nous stockons dans le contrat, ce qui prend du gaz lors du déploiement.
Au lieu de cela, nous pouvons simplement l'injecter dans le constructeur, au moment où nous déployons le contrat intelligent sur le réseau de blockchain pertinent. C'est ainsi que nous écrivons un contrat qui peut fonctionner avec n'importe quel nombre de valeurs de paramètres.
Un autre cas d'utilisation courant est lorsque votre contrat intelligent hérite d'un autre contrat intelligent et que vous devez passer des valeurs au contrat intelligent parent lorsque votre contrat est en cours de création. Mais l'héritage est quelque chose que nous discuterons plus tard.
J'ai mentionné que les constructeurs sont facultatifs. Dans HotFudgeSauce, nous n'avons pas écrit de fonction constructeur explicite. Mais Solidity supporte les fonctions constructeur implicites. Donc si nous n'incluons pas de fonction constructeur dans notre contrat intelligent, Solidity supposera un constructeur par défaut qui ressemble à constructor() {}.
Si vous évaluez cela dans votre tête, vous verrez qu'il ne fait rien et c'est pourquoi il peut être exclu (rendu implicite) et le compilateur utilisera le constructeur par défaut.
Interfaces et contrats abstraits
Une interface en Solidity est un concept essentiel à comprendre. Les contrats intelligents sur Ethereum sont publiquement visibles et vous pouvez donc interagir avec eux via leurs fonctions (dans la mesure où les spécificateurs de visibilité vous permettent de le faire !).
C'est ce qui rend les contrats intelligents "composables" et pourquoi tant de protocoles Defi sont appelés "money Legos" - vous pouvez écrire des contrats intelligents qui interagissent avec d'autres contrats intelligents qui interagissent avec d'autres contrats intelligents et ainsi de suite... vous voyez l'idée.
Ainsi, lorsque vous voulez que votre contrat intelligent A interagisse avec un autre contrat intelligent B, vous avez besoin de l'interface de B. Une interface vous donne un index ou un menu des différentes fonctions disponibles pour que vous puissiez les appeler sur un contrat intelligent donné.
Une caractéristique importante des interfaces est qu'elles ne doivent pas avoir d'implémentation (logique de code) pour aucune des fonctions définies. Les interfaces sont simplement une collection de noms de fonctions et de leurs arguments et types de retour attendus. Elles ne sont pas uniques à Solidity.
Ainsi, une interface pour notre contrat intelligent HotFudgeSauce ressemblerait à ceci (notez que par convention, les interfaces Solidity sont nommées en préfixant le nom du contrat intelligent avec un "I" :
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.7;
interface IHotFudgeSauce {
function get() public view returns (uint);
function increment() public;
function decrement() public;
}
C'est tout ! Puisque HotFudgeSauce n'avait que trois fonctions, l'interface ne montre que celles-ci.
Mais il y a un point important et subtil ici : une interface n'a pas besoin d'inclure toutes les fonctions disponibles à appeler dans un contrat intelligent. Une interface peut être raccourcie pour inclure les définitions de fonctions pour les fonctions que vous avez l'intention d'appeler !
Ainsi, si vous ne vouliez utiliser que la méthode decrement() sur HotFudgeSauce, vous pourriez absolument supprimer get() et increment() de votre interface - mais vous ne pourriez pas appeler ces deux fonctions depuis votre contrat.
Alors, que se passe-t-il réellement ? Eh bien, les interfaces donnent simplement à votre contrat intelligent un moyen de savoir quelles fonctions peuvent être appelées dans votre contrat intelligent cible, quels paramètres ces fonctions acceptent (et leur type de données), et quel type de données de retour vous pouvez attendre. En Solidity, c'est tout ce dont vous avez besoin pour interagir avec un autre contrat intelligent.
Dans certaines situations, vous pouvez avoir un contrat abstrait qui est similaire mais différent d'une interface.
Un contrat abstrait est déclaré en utilisant le mot-clé abstract et est un contrat où une ou plusieurs de ses fonctions sont déclarées mais non implémentées. C'est une autre façon de dire qu'au moins une fonction est déclarée mais non implémentée.
En inversant cela, un contrat abstrait peut avoir des implémentations de ses fonctions (contrairement aux interfaces qui peuvent avoir zéro fonction implémentée), mais tant qu'au moins une fonction n'est pas implémentée, le contrat doit être marqué comme abstrait :
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.7;
abstract contract Feline {
Vous pouvez (légitimement) vous demander quel est l'intérêt de cela. Eh bien, les contrats abstraits ne peuvent pas être instanciés (créés) directement. Ils ne peuvent être utilisés que par d'autres contrats qui en héritent.
Ainsi, les contrats abstraits sont souvent utilisés comme un modèle ou un "contrat de base" à partir duquel d'autres contrats intelligents peuvent "hériter" afin que les contrats intelligents héritiers soient forcés d'implémenter certaines fonctions déclarées par le contrat abstrait (parent). Cela impose une structure définie à travers les contrats apparentés, ce qui est souvent un modèle de conception utile.
Cette histoire d'héritage deviendra un peu plus claire lorsque nous discuterons de l'héritage plus tard. Pour l'instant, retenez simplement que vous pouvez déclarer un contrat intelligent abstrait qui n'implémente pas toutes ses fonctions - mais si vous le faites, vous ne pouvez pas l'instancier, et les futurs contrats intelligents qui en héritent doivent faire le travail d'implémenter ces fonctions non implémentées.
Certaines des différences importantes entre les interfaces et les contrats abstraits sont que :
Les interfaces peuvent avoir zéro implémentation, alors que les contrats abstraits peuvent avoir n'importe quel nombre d'implémentations tant qu'au moins une fonction est "abstraite" (c'est-à-dire non implémentée).
Toutes les fonctions dans une interface doivent être marquées comme "externes" car elles ne peuvent être appelées que par d'autres contrats qui implémentent cette interface.
Les interfaces ne peuvent pas avoir de constructeurs, alors que les contrats abstraits peuvent en avoir.
Les interfaces ne peuvent pas avoir de variables d'état où les contrats abstraits peuvent en avoir.
Exemple de contrat intelligent #2
Pour les quelques concepts Solidity suivants, nous utiliserons le contrat intelligent ci-dessous. Cela est en partie parce que cet exemple contient un contrat intelligent qui est réellement utilisé dans le monde réel. Je l'ai également choisi parce que j'ai un biais clair pour Chainlink Labs puisque j'y travaille (😆) et c'est génial. Mais c'est aussi là que j'ai appris beaucoup de Solidity, et c'est toujours mieux d'apprendre avec des exemples du monde réel.
Alors commencez par lire le code et les commentaires ci-dessous. Vous avez déjà appris 99 % de ce dont vous avez besoin pour comprendre le contrat ci-dessous, à condition de le lire attentivement. Ensuite, passez aux apprentissages clés de ce contrat.
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.7;
import "@chainlink/contracts/src/v0.8/interfaces/AggregatorV3Interface.sol";
contract PriceConsumerV3 {
AggregatorV3Interface internal priceFeed;
/**
* Network: Goerli
* Aggregator: ETH/USD
* Address: 0xD4a33860578De61DBAbDc8BFdb98FD742fA7028e
*/
constructor() {
priceFeed = AggregatorV3Interface(0xD4a33860578De61DBAbDc8BFdb98FD742fA7028e);
}
Ce contrat intelligent obtient le dernier prix USD de 1 Eth, à partir d'un oracle de flux de prix Chainlink en direct (voir l'oracle sur etherscan). L'exemple utilise le réseau Goerli afin que vous ne finissiez pas par dépenser de l'argent réel sur le mainnet Ethereum.
Maintenant, voici les 6 concepts essentiels de Solidity que vous devez assimiler :
- Juste après l'instruction
pragma, nous avons une instruction d'importation. Cela importe du code existant dans notre contrat intelligent.
C'est super cool car c'est ainsi que nous réutilisons et bénéficions du code que d'autres ont écrit. Vous pouvez consulter le code qui est importé sur ce lien GitHub.
En effet, lorsque nous compilons notre contrat intelligent, ce code importé est intégré et compilé en bytecode avec lui. Nous verrons pourquoi nous en avons besoin dans un instant...
Auparavant, vous avez vu que les commentaires sur une seule ligne étaient marqués avec
//. Maintenant, vous apprenez les commentaires multilignes. Ils peuvent s'étendre sur une ou plusieurs lignes et utilisent/*et*/pour commencer et terminer les commentaires.Nous déclarons une variable appelée
priceFeedet elle a un typeAggregatorV3Interface. Mais d'où vient ce type étrange ? De notre code importé dans l'instruction d'importation - nous pouvons utiliser le typeAggregatorV3Interfaceparce que Chainlink l'a défini.
Si vous avez regardé ce lien GitHub, vous verriez que le type définit une interface (nous venons de parler des interfaces). Ainsi, priceFeed est une référence à un objet qui est de type AggregatorV3Interface.
- Jetez un coup d'œil à la fonction constructeur. Celle-ci n'accepte pas de paramètres, mais nous aurions tout aussi bien pu passer l'adresse du contrat d'oracle du flux de prix ETH/USD
0xD4a33860578De61DBAbDc8BFdb98FD742fA7028een tant que paramètre de typeaddress. Au lieu de cela, nous codons en dur l'adresse à l'intérieur du constructeur.
Mais nous créons également une référence au contrat intelligent de l'agrégateur de flux de prix (en utilisant l'interface appelée AggregatorV3Interface).
Maintenant, nous pouvons appeler toutes les méthodes disponibles sur AggregatorV3Interface car la variable priceFeed fait référence à ce contrat intelligent. En fait, nous faisons cela ensuite...
- Passons à la fonction
getLatestPrice(). Vous reconnaîtrez sa structure à partir de notre discussion dansHotFudgeSauce, mais elle fait des choses intéressantes.
À l'intérieur de cette fonction getLatestPrice(), nous appelons la fonction latestRoundData() qui existe sur le type AggregatorV3Interface. Si vous regardez le code source de cette méthode, vous remarquerez que cette fonction latestRoundData() retourne 5 types différents d'entiers !
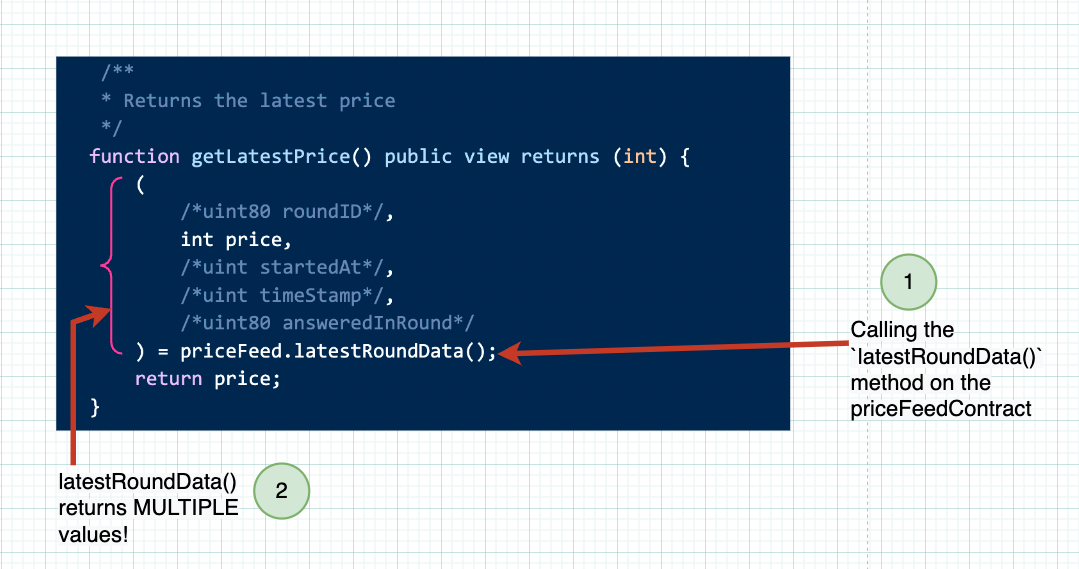
Appel de méthodes sur un autre contrat intelligent depuis notre contrat intelligent
Dans notre contrat intelligent, nous commentons les 4 valeurs dont nous n'avons pas besoin. Cela signifie que les fonctions Solidity peuvent retourner plusieurs valeurs (dans cet exemple, nous recevons 5 valeurs), et nous pouvons choisir celles que nous voulons.
Une autre façon de consommer les résultats de l'appel de latestRoundData() serait : ( ,int price, , ,) = priceFeed.latestRoundData() où nous ignorons 4 des 5 valeurs retournées en ne leur donnant pas de nom de variable.
Lorsque nous attribuons des noms de variables à une ou plusieurs valeurs retournées par une fonction, nous l'appelons "affectation par déstructuration" car nous déstructurons les valeurs retournées (séparons chacune) et les attribuons au moment de la déstructuration, comme nous le faisons avec price ci-dessus.
Puisque vous avez appris les interfaces, je vous recommande de jeter un coup d'œil au dépôt GitHub de Chainlink Labs pour examiner la fonction latestRoundData() implémentée dans le contrat Aggregator et comment l'AggregatorV3Interface fournit l'interface pour interagir avec le contrat Aggregator.
Qu'est-ce que l'état du contrat ?
Avant d'aller plus loin, il est important de s'assurer que la terminologie que nous allons voir souvent est compréhensible pour vous.
Le terme "état" en informatique a une signification bien définie. Bien que cela puisse devenir très confus, l'essentiel de l'état est qu'il fait référence à toutes les informations qui sont "mémorisées" par un programme lors de son exécution. Ces informations peuvent changer, être mises à jour, supprimées, créées, etc. Et si vous deviez en prendre un instantané à divers moments, les informations seront dans différents "états".
Ainsi, l'état est simplement l'instantané actuel du programme, à un moment donné lors de son exécution - quelles valeurs ses variables contiennent, ce qu'elles font, quels objets ont été créés ou supprimés, etc.
Nous avons précédemment examiné les trois types de variables - Variables d'État, Variables Locales et Variables Globales. Les variables d'état, ainsi que les variables globales, nous donnent l'état du contrat intelligent à tout moment donné. Ainsi, l'état d'un contrat intelligent est une description de :
quelles valeurs ses variables d'état contiennent,
quelles valeurs les variables globales liées à la blockchain ont à ce moment-là, et
le solde (le cas échéant) se trouvant dans le compte du contrat intelligent.
Mots-clés de mutabilité d'état (modificateurs)
Maintenant que nous avons discuté de l'état, des variables d'état et des fonctions, comprenons les mots-clés Solidity qui spécifient ce que nous sommes autorisés à faire avec l'état.
Ces mots-clés sont appelés modificateurs. Mais tous ne vous permettent pas de modifier l'état. En fait, beaucoup d'entre eux interdisent expressément les modifications.
Voici les modificateurs Solidity que vous verrez dans tout contrat intelligent réel :
| Mot-clé du modificateur | S'applique à... | But |
| constant | Variables d'état | Déclarées et recevant une valeur une fois, en même temps. Codées en dur dans le code. Leur valeur donnée ne peut jamais être changée. |
| immutable | Variables d'état | Elles sont déclarées en haut des contrats intelligents, mais reçoivent leur valeur (une seule fois !) au moment de la construction - c'est-à-dire via la fonction constructeur. Une fois qu'elles reçoivent leur valeur, elles sont (efficacement) des constantes. Et leurs valeurs sont en fait stockées dans le code lui-même plutôt que dans un emplacement de stockage (le stockage sera expliqué plus tard). |
| view | fonctions | Vous verrez généralement cela juste après le spécificateur de visibilité. Un modificateur view signifie que la fonction ne peut que "voir" (lire depuis) l'état du contrat, mais ne peut pas le changer (ne peut pas "écrire" dans l'état du contrat). C'est effectivement un modificateur en lecture seule. Si la fonction doit utiliser une valeur qui se trouve dans l'état du contrat, mais ne pas modifier cette valeur, ce sera une fonction view. |
| pure | fonctions | Les fonctions qui sont pures ne sont pas autorisées à écrire (modifier) l'état du contrat, ni à lire depuis celui-ci ! Elles font des choses qui n'interagissent en aucune manière avec l'état de la blockchain. Souvent, celles-ci peuvent être des fonctions d'assistance qui effectuent un calcul ou convertissent une entrée d'un type de données en un autre type de données, etc. |
| payable | fonctions | Ce mot-clé permet à une fonction de recevoir de l'Eth. Sans ce mot-clé, vous ne pouvez pas envoyer de l'Eth lors de l'appel d'une fonction. Notez que dans la version 0.8.17 de Solidity, il y a eu des changements majeurs qui ont permis l'utilisation de payable comme type de données. Plus précisément, nous pouvons maintenant convertir le type de données address en un type de données address payable en effectuant une conversion de type qui ressemble à payable(0xdCad3a6d3569DF655070DEd06cb7A1b2Ccd1D3AF). Ce que cela fait, c'est rendre une adresse Ethereum donnée payable, après quoi nous pouvons envoyer de l'Eth à cette adresse. Notez que cette utilisation de payable est une conversion de type, et non la même chose que le modificateur de fonction, bien que le même mot-clé soit utilisé. Nous aborderons le type address plus tard, mais vous pouvez en lire plus ici. |
| virtual | fonctions | Il s'agit d'un sujet légèrement plus avancé et il est traité en détail dans la section sur l'héritage. Ce modificateur permet à la fonction d'être "remplacée" dans un contrat enfant qui en hérite. En d'autres termes, une fonction avec le mot-clé virtual peut être "réécrite" avec une logique interne différente dans un autre contrat qui en hérite. |
| override | fonctions | Il s'agit de l'inverse du modificateur virtual. Lorsqu'un contrat enfant "réécrit" une fonction qui a été déclarée dans un contrat de base (contrat parent) dont il hérite, il marque cette fonction réécrite avec override pour signaler que son implémentation remplace celle donnée dans le contrat parent. Si une fonction virtual du parent n'est pas remplacée par l'enfant, l'implémentation du parent s'appliquera à l'enfant. |
| indexed | événements | Nous aborderons les événements plus tard dans ce guide. Ils sont de petits ensembles de données "émis" par un contrat intelligent, généralement en réponse à des événements notables. Le mot-clé indexed indique qu'une des pièces de données contenues dans un événement doit être stockée dans la blockchain pour une récupération et un filtrage ultérieurs. Cela aura plus de sens une fois que nous aurons couvert les Événements et la Journalisation plus tard dans ce guide. |
| anonymous | événements | Les docs disent "Ne stocke pas la signature de l'événement comme sujet" ce qui ne signifie probablement pas grand-chose pour vous pour l'instant. Mais le mot-clé indique qu'il rend une partie de l'événement "anonyme". Donc cela aura du sens une fois que nous comprendrons les événements et les sujets plus tard dans ce guide. |
Notez que les variables qui ne sont pas des variables de stockage (c'est-à-dire les variables locales déclarées et utilisées dans la portée d'une fonction donnée) n'ont pas besoin de modificateurs d'état. Cela est dû au fait qu'elles ne font pas réellement partie de l'état du contrat intelligent. Elles font simplement partie de l'état local à l'intérieur de cette fonction. Par définition, elles sont modifiables et n'ont pas besoin de contrôles sur leur modifiabilité.
Emplacements de données – Stockage, Mémoire et Pile
Sur Ethereum et les chaînes basées sur l'EVM, les données à l'intérieur du système peuvent être placées et accessibles dans plus d'un "emplacement de données".
Les emplacements de données font partie de la conception et de l'architecture fondamentales de l'EVM. Lorsque vous voyez les mots "mémoire", "stockage" et "pile", vous devriez commencer à penser "emplacements de données" - c'est-à-dire, où les données peuvent être stockées (écrites) et récupérées (lues).
L'emplacement des données a un impact sur la manière dont le code s'exécute au moment de l'exécution. Mais il a également des impacts très importants sur la quantité de gaz utilisée lors du déploiement et de l'exécution du contrat intelligent.
L'utilisation du gaz nécessite une compréhension plus approfondie de l'EVM et de quelque chose appelé opcodes - nous pouvons laisser cette discussion de côté pour l'instant. Bien que cela soit utile, ce n'est pas strictement nécessaire pour que vous compreniez les emplacements de données.
Bien que j'aie mentionné 3 emplacements de données jusqu'à présent, il existe 2 autres façons dont les données peuvent être stockées et accessibles dans les contrats intelligents : "calldata" et "code". Mais ceux-ci ne sont pas des emplacements de données dans la conception de l'EVM. Ils sont simplement des sous-ensembles des 3 emplacements de données.
Commençons par le stockage. Dans la conception de l'EVM, les données qui doivent être stockées de manière permanente sur la blockchain sont placées dans la zone de "stockage" du contrat intelligent pertinent. Cela inclut toutes les variables d'état du contrat.
Une fois qu'un contrat est déployé et a son adresse spécifique, il obtient également sa propre zone de stockage, que vous pouvez considérer comme un magasin clé-valeur (comme une table de hachage) où les deux clés et les valeurs sont des mots de données de 256 bits (32 octets). Et "mots" a une signification spécifique en architecture informatique.
Parce que le stockage persiste les données sur la blockchain de manière permanente, toutes les données doivent être synchronisées sur tous les nœuds du réseau, ce qui explique pourquoi les nœuds doivent atteindre un consensus sur l'état des données. Ce consensus rend l'utilisation du stockage coûteuse.
Vous avez déjà vu des exemples de variables de stockage (alias variables d'état du contrat) mais voici un exemple tiré du contrat intelligent Chainlink Verifiable Random Number Consumer

Emplacement de données de stockage. Mise des données dans la disposition de stockage du contrat.
Lorsque le contrat ci-dessus est créé et déployé, toute adresse passée dans le constructeur du contrat devient stockée de manière permanente dans le stockage du contrat intelligent, et est accessible en utilisant la variable vrfCoodinator. Puisque cette variable d'état est marquée comme immutable, elle ne peut pas être changée après cela.
Pour rafraîchir votre mémoire de la section précédente sur les mots-clés, où nous avons discuté des variables immutable et constant, ces valeurs ne sont pas mises en stockage. Elles deviennent partie intégrante du code lui-même lorsque le contrat est construit, donc ces valeurs ne consomment pas autant de gaz que les variables de stockage.
Passons maintenant à memory. Il s'agit d'un stockage temporaire où vous pouvez lire et écrire des données nécessaires pendant l'exécution du contrat intelligent. Ces données sont effacées une fois que les fonctions qui utilisent les données ont terminé leur exécution.
L'espace de localisation memory est comme un bloc-notes temporaire, et un nouveau bloc-notes est mis à disposition dans le contrat intelligent chaque fois qu'une fonction est déclenchée. Ce bloc-notes est jeté après la fin de l'exécution.
Lorsque vous comprenez la différence entre le stockage et la mémoire, vous pouvez penser au stockage comme à un type de disque dur dans le monde informatique traditionnel, dans le sens où il a un stockage "persistant" des données. Mais la mémoire est plus proche de la RAM dans l'informatique traditionnelle.
La stack est la zone de données où la plupart des calculs de l'EVM sont effectués. L'EVM suit un modèle de calcul basé sur la pile et non un modèle de calcul basé sur les registres, ce qui signifie que chaque opération à effectuer doit être stockée et accessible à l'aide d'une structure de données de pile.
La profondeur de la pile - c'est-à-dire le nombre total d'éléments qu'elle peut contenir - est de 1024, et chaque élément de la pile peut être long de 256 bits (32 octets). Cela est identique à la taille de chaque clé et valeur dans l'emplacement de données de stockage.
Vous pouvez en savoir plus sur la manière dont l'EVM contrôle l'accès à la zone de stockage de données de la pile ici.
Ensuite, parlons de calldata. J'ai supposé que vous avez une compréhension de base des messages et des transactions des contrats intelligents Ethereum. Si ce n'est pas le cas, vous devriez d'abord lire ces liens.
Les messages et les transactions sont la manière dont les fonctions des contrats intelligents sont invoquées, et ils contiennent une variété de données nécessaires à l'exécution de ces fonctions. Ces données de message sont stockées dans une section en lecture seule de la mémoire appelée calldata, qui contient des éléments comme le nom de la fonction et les paramètres.
Cela est pertinent pour les fonctions appelables externement, car les fonctions internes et privées n'utilisent pas calldata. Seules les données d'exécution de fonction "entrantes" et les paramètres de fonction sont stockés à cet emplacement.
Rappelez-vous, calldata est de la mémoire sauf que calldata est en lecture seule. Vous ne pouvez pas écrire de données dedans.
Et enfin, code n'est pas un emplacement de données mais fait plutôt référence au bytecode compilé du contrat intelligent qui est déployé et stocké de manière permanente sur la blockchain. Ce bytecode est stocké dans une ROM immuable (Read Only Memory), qui est chargée avec le bytecode du contrat intelligent à exécuter.
Rappelez-vous comment nous avons discuté de la différence entre les variables immuables et constantes en Solidity ? Les valeurs immuables reçoivent leur valeur une fois (généralement dans le constructeur) et les variables constantes ont leurs valeurs codées en dur dans le code du contrat intelligent. Parce qu'elles sont codées en dur, les valeurs constantes sont compilées littéralement et intégrées directement dans le bytecode du contrat intelligent, et stockées dans cet emplacement de données de code/ROM.
Comme calldata, code est également en lecture seule - si vous avez compris le paragraphe précédent, vous comprendrez pourquoi !
Comment fonctionne le typage
Le typage est un concept très important en programmation car c'est ainsi que nous donnons une structure aux données. À partir de cette structure, nous pouvons exécuter des opérations sur les données de manière sûre, cohérente et prévisible.
Lorsque qu'un langage a un typage strict, cela signifie que le langage définit strictement le type de chaque morceau de données, et qu'une variable ayant un type ne peut pas recevoir un autre type.
En d'autres termes, dans les langages strictement typés :
int a =1 // 1 ici est de type entier
string b= "1" // 1 ici est de type chaîne de caractères
Mais en JavaScript, qui n'est pas typé, b=a fonctionnerait totalement - cela rend JavaScript "dynamiquement typé".
De même, dans les langages statiquement typés, vous ne pouvez pas passer un entier dans une fonction qui attend une chaîne de caractères. Mais en JavaScript, nous pouvons passer n'importe quoi à une fonction et le programme se compilera mais il peut générer une erreur lors de l'exécution du programme.
Par exemple, prenons cette fonction :
function add(a,b){
return a + b
}
add(1, 2) // sortie est 3, de type entier
add(1, "2") // "2" est une chaîne de caractères, pas un entier, donc la sortie devient la chaîne de caractères "12" (!?)
Comme vous pouvez l'imaginer, cela peut produire des bugs assez difficiles à trouver. Le code se compile et peut même s'exécuter sans échouer, bien qu'il produise des résultats inattendus.
Mais un langage fortement typé ne vous permettrait jamais de passer la chaîne de caractères "2" car la fonction insisterait sur les types qu'elle accepte.
Prenons un exemple de la manière dont cette fonction serait écrite dans un langage fortement typé comme Go.

Comment fonctionne le typage dans la syntaxe, en utilisant Golang à des fins d'illustration
Essayer de passer une string (même si elle représente un nombre) empêchera le programme de se compiler (construire). Vous verrez une erreur comme celle-ci :
./prog.go:13:19: cannot use "2" (untyped string constant) as int value in argument to add
Go build failed.
Ainsi, les types sont importants car des données qui semblent identiques pour un humain peuvent être perçues très différemment par un ordinateur. Cela peut causer des bugs assez étranges, des erreurs, des plantages de programme et même de grandes vulnérabilités de sécurité.
Les types donnent également aux développeurs la capacité de créer leurs propres types personnalisés, qui peuvent ensuite être programmés avec des propriétés personnalisées (attributs) et des opérations (comportements).
Les systèmes de types existent afin que les humains puissent raisonner sur les données en posant la question "quel est le type de ces données, et que devrait-il être capable de faire ?" et que les machines puissent faire exactement ce qui est prévu.
Voici un autre exemple de la manière dont des données qui semblent identiques pour vous et moi peuvent être interprétées de manière très différente par un processeur. Prenez la séquence de chiffres binaires (c'est-à-dire que les chiffres ne peuvent avoir qu'une valeur de 0 ou 1, qui est le système binaire avec lequel les processeurs travaillent) 1100001010100011.
Pour un humain, en utilisant le système décimal, cela ressemble à un très grand nombre - peut-être 11 milliards ou quelque chose.
Mais pour un ordinateur qui est binaire, ce n'est donc pas 11 quoi que ce soit. L'ordinateur voit cela comme une séquence de 16 bits (abréviation de chiffres binaires) et en binaire, cela pourrait signifier le nombre positif (entier non signé) 49,827 ou l'entier signé -15,709 ou la représentation UTF-8 du symbole de la livre britannique £ ou quelque chose de différent !
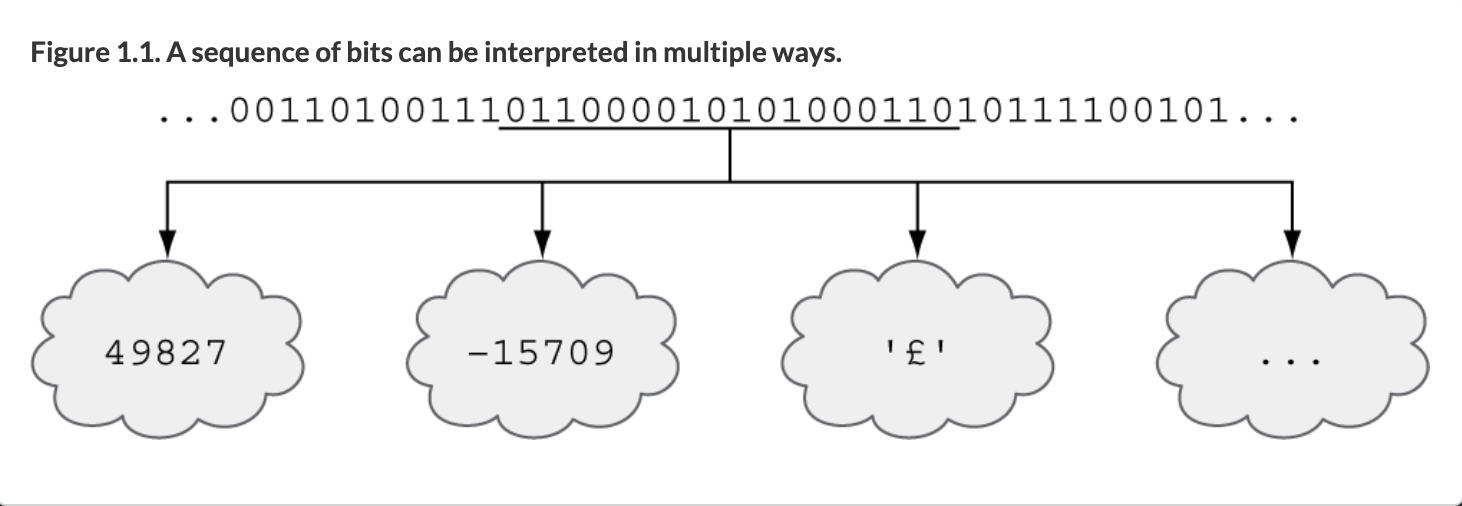
Une séquence de bits peut être interprétée par un ordinateur pour avoir des significations très différentes (source)
Ainsi, toute cette explication est pour dire que les types sont importants, et que les types peuvent être "intégrés" dans un langage même si le langage n'impose pas strictement les types, comme JavaScript.
JavaScript a déjà des types intégrés comme les nombres, les chaînes de caractères, les booléens, les objets et les tableaux. Mais comme nous l'avons vu, JavaScript n'insiste pas sur le respect des types comme le fait un langage statiquement typé comme Go.
Revenons maintenant à Solidity. Solidity est très certainement un langage statiquement typé. Lorsque vous déclarez une variable, vous devez également déclarer son type. Allant plus loin, Solidity refusera simplement de compiler si vous essayez de passer une chaîne de caractères dans une fonction qui attend un entier.
En fait, Solidity est très strict avec les types. Par exemple, différents types d'entiers peuvent également échouer à la compilation comme dans l'exemple suivant où la fonction add() attend un entier non signé (positif) et ne l'ajoutera qu'à ce nombre, retournant ainsi toujours un entier positif. Mais le type de retour est spécifié comme un int, ce qui signifie qu'il pourrait être positif ou négatif !
function add(uint256 a) public pure returns (int256){
return a + 10;
}
Ainsi, même si l'entrée et la sortie sont des entiers de 256 bits, le fait que la fonction ne reçoive que des entiers non signés fait que le compilateur se plaint que le type d'entier non signé n'est pas implicitement convertible en type d'entier signé.
C'est assez strict ! Le développeur peut forcer la conversion (appelée transtypage) en réécrivant l'instruction return comme return int256(a + 10). Mais il y a des problèmes à considérer avec ce type d'action, et cela dépasse le cadre de ce dont nous parlons ici.
Pour l'instant, retenez simplement que Solidity est statiquement typé, ce qui signifie que le type de chaque variable doit être expressément spécifié lors de leur déclaration dans le code. Vous pouvez combiner des types pour former des types plus complexes et composites. Ensuite, nous pouvons discuter de certains de ces types intégrés.
Types de données Solidity
Les types qui sont intégrés au langage et qui viennent avec lui "sortis de la boîte" sont souvent appelés "primitifs". Ils sont intrinsèques au langage. Vous pouvez combiner des types primitifs pour former des structures de données plus complexes qui deviennent des types de données "personnalisés".
En JavaScript, par exemple, les primitifs sont des données qui ne sont pas un objet JS et n'ont pas de méthodes ou de propriétés. Il existe 7 types de données primitifs en JavaScript : string, number, bigint, boolean, undefined, symbol, et null.
Solidity a également ses propres types de données primitifs. Intéressamment, Solidity n'a pas "undefined" ou "null". Au lieu de cela, lorsque vous déclarez une variable et son type, mais que vous ne lui attribuez pas de valeur, Solidity attribuera une valeur par défaut à ce type. Ce que cette valeur par défaut est exactement dépend du type de données.
De nombreux types de données primitifs de Solidity sont des variations du même type "de base". Par exemple, le type int lui-même a des sous-types basés sur le nombre de chiffres binaires que le type integer peut contenir.
Si cela vous confond un peu, ne vous inquiétez pas - ce n'est pas facile si vous n'êtes pas familier avec les bits et les octets, et je couvrirai les entiers un peu plus tard.
Avant d'explorer les types Solidity, il y a un autre concept très important que vous devez comprendre - c'est la source de nombreux bugs et "pièges inattendus" dans les langages de programmation.
Il s'agit de la différence entre un type de valeur et un type de référence, et la distinction résultante entre les données dans les programmes étant "passées par valeur" vs "passées par référence". Je vais faire un bref résumé ci-dessous, mais vous pouvez également trouver utile de regarder cette courte vidéo pour renforcer votre modèle mental avant de continuer.
Passage par référence vs passage par valeur
Au niveau du système d'exploitation, lorsqu'un programme est en cours d'exécution, toutes les données utilisées par le programme pendant son exécution sont stockées dans des emplacements de la RAM (mémoire) de l'ordinateur. Lorsque vous déclarez une variable, un espace mémoire est alloué pour contenir des données sur cette variable et la valeur qui est, ou sera éventuellement, assignée à cette variable.
Il y a également une pièce de données souvent appelée un "pointeur". Ce pointeur pointe vers l'emplacement mémoire (une "adresse" dans la RAM de l'ordinateur) où cette variable et sa valeur peuvent être trouvées. Ainsi, le pointeur contient effectivement une référence à l'endroit où les données peuvent être trouvées dans la mémoire de l'ordinateur.
Ainsi, lorsque vous passez des données dans un programme (par exemple, lorsque vous attribuez une valeur à un nouveau nom de variable, ou lorsque vous passez des entrées (paramètres) dans une fonction ou une méthode, le compilateur du langage peut réaliser cela de deux manières. Il peut passer un pointeur vers l'emplacement des données dans la mémoire de l'ordinateur, ou il peut faire une copie des données elles-mêmes, et passer la valeur réelle.
La première approche est "passage par référence". La deuxième approche est "passage par valeur".
Les types de données primitifs de Solidity se divisent en deux catégories - ils sont soit des types de valeur, soit des types de référence.
En d'autres termes, en Solidity, lorsque vous passez des données, le type des données décidera si vous passez des copies de la valeur ou une référence à l'emplacement de la valeur dans la mémoire de l'ordinateur.
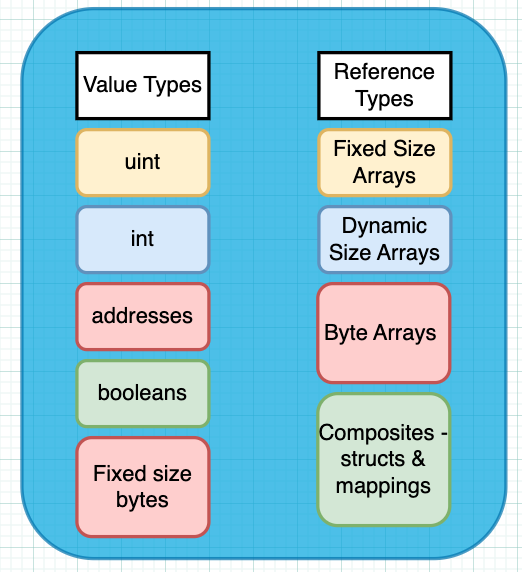
Types de valeur et types de référence en Solidity
Dans les "types de valeur" de Solidity, les entiers sont de deux catégories - uint est non signé (entiers positifs uniquement, donc ils n'ont pas de signes plus ou moins) et int est signé (peut être positif ou négatif, et s'ils étaient écrits, ils auraient un signe plus ou moins).
Les types entiers peuvent également spécifier combien de bits ils sont longs - ou combien de bits sont utilisés pour représenter l'entier.
Un uint8 est un entier représenté par 8 chiffres binaires (bits) et peut stocker jusqu'à 256 valeurs différentes (2^8=256). Puisque uint est pour les entiers non signés (positifs), cela signifie qu'il peut stocker des valeurs de 0 à 255 (non inclus de 1 à 256).
Cependant, lorsque vous avez des entiers signés, comme un int8, alors l'un des bits est utilisé pour représenter s'il s'agit d'un nombre positif ou négatif. Cela signifie que nous n'avons plus que 7 bits, et donc nous ne pouvons représenter que jusqu'à 2^7 (128) valeurs différentes, y compris 0. Ainsi, un int8 peut représenter tout ce qui va de -127 à +127.
Par extension, un int256 est long de 256 bits et peut stocker +/- (2^255) valeurs.
Les longueurs de bits sont des multiples de 8 (car 8 bits font un octet) donc vous pouvez avoir int8, int16, int24 etc. jusqu'à 256 (32 octets).
Les adresses font référence aux types de comptes Ethereum - soit un compte de contrat intelligent, soit un compte détenu en externe (aka "EOA". Votre portefeuille Metamask représente un EOA). Ainsi, une adresse est également un type en Solidity.
La valeur par défaut d'une adresse (c'est-à-dire la valeur qu'elle aura si vous déclarez une variable de type adresse mais que vous ne lui attribuez aucune valeur) est 0x0000000000000000000000000000000000000000 qui est également le résultat de cette expression : address(0).
Les booléens représentent des valeurs vraies ou fausses. Enfin, nous avons des tableaux d'octets de taille fixe comme bytes1, bytes2 ... bytes32. Ce sont des tableaux de longueur fixe qui contiennent des octets. Tous ces types de valeurs sont copiés lorsqu'ils sont passés dans le code.
Pour les "types de référence", nous avons des tableaux, qui peuvent avoir une taille fixe spécifiée lorsqu'ils sont déclarés, ou des tableaux de taille dynamique, qui commencent avec une taille fixe, mais peuvent être "redimensionnés" à mesure que le nombre d'éléments de données dans le tableau augmente.
Les octets sont un type de données de bas niveau qui font référence aux données encodées en format binaire. Toutes les données sont finalement réduites en forme binaire par le compilateur afin que l'EVM (ou, en informatique traditionnelle, le processeur) puisse travailler avec.
Le stockage et le travail avec les octets sont souvent plus rapides et plus efficaces par rapport à d'autres types de données plus lisibles par l'homme.
Vous vous demandez peut-être pourquoi je n'ai pas fait référence aux chaînes de caractères dans l'un ou l'autre type de données dans l'image ci-dessus. C'est parce qu'en Solidity, les chaînes de caractères sont en fait des tableaux de taille dynamique, et les tableaux stockent une séquence d'octets (juste des nombres binaires) qui sont encodés au format UTF-8.
Elles ne sont pas un primitif en Solidity. En JavaScript, elles sont appelées primitives, mais même en JavaScript, les chaînes de caractères sont similaires (mais pas identiques) aux tableaux et sont une séquence de valeurs entières, encodées en UTF-16.
Il est souvent plus efficace de stocker une string en tant que type bytes dans un contrat intelligent, car la conversion entre strings et bytes est assez facile. Il est donc utile de stocker les strings en tant que bytes mais de les retourner dans les fonctions en tant que chaînes de caractères. Vous pouvez voir un exemple ci-dessous :
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.0;
contract StringyBytes {
En dehors des chaînes de caractères Solidity, le type de données bytes est un tableau d'octets de taille dynamique. De plus, contrairement à son cousin tableau d'octets de taille fixe, c'est un type de référence. Le type bytes en Solidity est une abréviation pour "tableau d'octets" et peut être écrit dans le programme comme bytes ou byte[].
Si vous êtes confus par les octets et les tableaux d'octets... Je compatis.
Les détails sanglants sous-jacents des chaînes de caractères et des tableaux d'octets ne sont pas trop pertinents pour ce guide. Le point important pour l'instant est que certains types de données sont passés par référence et d'autres sont passés en copiant leurs valeurs.
Il suffit de dire que les chaînes de caractères Solidity et les octets sans taille spécifiée sont des types de référence car ils sont tous deux des tableaux de taille dynamique.
Enfin, parmi les primitifs de Solidity, nous avons structs et mappings. Parfois, ceux-ci sont appelés types de données "composites" car ils sont composés d'autres primitifs.
Un struct définira une pièce de données comme ayant une ou plusieurs propriétés ou attributs, et spécifiera le type de données et le nom de chaque propriété. Les structs vous donnent la capacité de définir votre propre type personnalisé afin que vous puissiez organiser et collecter des pièces de données en un type de données plus grand.
Par exemple, vous pourriez avoir un struct qui définit une Person comme suit :
struct Person {
string name;
uint age;
Vous pouvez instancier ou initialiser un struct Person de la manière suivante :
// notation par points mise à jour. Le struct Job est non initialisé
// ce qui signifie que ses propriétés auront leurs valeurs par défaut respectives
Person memory p;
P.name = "Zubin"
p.age = 41;
p.isSolidityDev = true;
// Ou dans un appel de style fonction. Notez que j'initialise aussi un struct Job !
Person p = Person("Zubin", "41", "true", Job("Chainlink Labs", "DevRel", true));
// Ou dans un style clé-valeur
Job j = Job({ employer: "Chainlink Labs", "DevRel", true});
p.job = j // cela est fait dans le style notation par points.
Les mappings sont similaires aux tables de hachage, aux dictionnaires ou aux objets et maps JavaScript, mais avec un peu moins de fonctionnalités.
Un mapping est également une paire clé-valeur, et il y a des restrictions sur les types de données que vous pouvez avoir comme clés, que vous pouvez lire ici. Les types de données associés aux clés d'un mapping peuvent être l'un des primitifs, des structs, et même d'autres mappings.
Voici comment les mappings sont déclarés, initialisés, écrits et lus - l'exemple ci-dessous est tiré du code source du contrat intelligent Chainlink Link Token.

Déclaration et utilisation du type Mappings en Solidity
Si vous essayez d'accéder à une valeur en utilisant une clé qui n'existe pas dans le mapping, il retournera la valeur par défaut du type qui est stocké dans le mapping.
Dans l'exemple ci-dessus, le type de toutes les valeurs dans le mapping balances est uint256, qui a une valeur par défaut de 0. Donc si nous appelions balanceOf() et passions une adresse qui n'a aucun jeton LINK émis, nous obtiendrions une valeur de 0.
Cela est raisonnable dans cet exemple, mais cela peut être un peu délicat lorsque nous voulons savoir si une clé existe ou non dans un mapping.
Actuellement, il n'y a aucun moyen d'énumérer les clés qui existent dans un mapping (c'est-à-dire qu'il n'y a rien d'équivalent à la méthode JavaScript Object.keys()). La récupération en utilisant une clé ne retournera que la valeur par défaut associée au type de données, ce qui ne nous indique pas clairement si la clé existe réellement ou non.
Il y a un "piège" intéressant avec les mappings. Contrairement à d'autres langages où vous pouvez passer des structures de données clé-valeur comme argument à une fonction, Solidity ne supporte pas le passage de mappings comme arguments à des fonctions sauf lorsque la visibilité des fonctions est marquée comme internal. Ainsi, vous ne pourriez pas écrire une fonction appelable externement ou publiquement qui accepterait des paires clé-valeur comme argument.
Comment déclarer et initialiser des tableaux en Solidity
Solidity propose deux types de tableaux, il est donc utile de comprendre les différentes manières dont ils peuvent être déclarés et initialisés.
Les deux principaux types de tableaux en Solidity sont le tableau de taille fixe et le tableau de taille dynamique.
Pour rafraîchir votre mémoire, les tableaux de taille fixe sont passés par valeur (copiés lorsqu'ils sont passés dans le code) et les tableaux de taille dynamique sont passés par référence (un pointeur vers l'adresse mémoire est passé dans le code).
Ils diffèrent également par leur syntaxe et leur capacité (taille), ce qui dicte ensuite quand nous utiliserions l'un plutôt que l'autre.
Voici à quoi ressemble un tableau de taille fixe lorsqu'il est déclaré et initialisé. Il a une capacité fixe de 6 éléments, et cela ne peut pas être changé une fois déclaré. L'espace mémoire pour un tableau de 6 éléments est alloué et ne peut pas changer.
string[6] fixedArray; // Capacité maximale est de 6 éléments.
Un tableau de taille fixe peut également être déclaré en déclarant simplement une variable et la taille du tableau et le type de ses éléments avec la syntaxe suivante :
// datatype arrayName[arraySize];
Contrastez cela avec un tableau de taille dynamique qui est déclaré et initialisé comme suit. Sa capacité n'est pas spécifiée et vous pouvez ajouter des éléments en utilisant la méthode push() :
uint[] dynamicArray;
Vous pouvez également déclarer et initialiser la valeur d'un tableau dans la même ligne de code.
string[3] fixedArray = ["a", "b", "c"]; // Tableau de chaînes de caractères de taille fixe
fixedArray.push("abc"); // Ne fonctionnera pas pour les tableaux de taille fixe.
String[] dynamicArray =["chainlink", "oracles"]; /// Tableau de taille dynamique
dynamicArray.push("rocks"); // Fonctionne.
Ces tableaux sont disponibles dans le stockage. Mais que faire si vous aviez besoin uniquement de tableaux temporaires en mémoire à l'intérieur d'une fonction ? Dans ce cas, il y a deux règles : seuls les tableaux de taille fixe sont autorisés, et vous devez utiliser le mot-clé new.
function inMemArray(string memory firstName, string memory lastName)
public
pure
returns (string[] memory)
{
Clairement, il existe plusieurs façons de déclarer et d'initialiser des tableaux. Lorsque vous souhaitez optimiser pour le gaz et les calculs, vous devez soigneusement considérer quel type de tableaux est requis, quelle est leur capacité et s'ils sont susceptibles de croître sans limite supérieure.
Cela influence également et est influencé par la conception de votre code - que vous ayez besoin de tableaux dans le stockage ou que vous en ayez besoin uniquement en mémoire.
Qu'est-ce que les modificateurs de fonction ?
Lorsque nous écrivons des fonctions, nous recevons souvent des entrées qui nécessitent une certaine validation, vérification ou autre logique à exécuter sur ces entrées avant de poursuivre avec le reste de la logique "métier".
Par exemple, si vous écrivez en JavaScript pur, vous pouvez vouloir vérifier que votre fonction reçoit des entiers et non des chaînes de caractères. Si c'est sur le backend, vous pouvez vouloir vérifier que la requête POST contenait les bons en-têtes d'authentification et secrets.
En Solidity, nous pouvons effectuer ces étapes de validation en déclarant un bloc de code similaire à une fonction appelé un modificateur.
Un modificateur est un extrait de code qui peut s'exécuter automatiquement avant ou après l'exécution de la fonction principale (c'est-à-dire la fonction à laquelle le modificateur est appliqué).
Les modificateurs peuvent également être hérités des contrats parents. Il est généralement utilisé comme un moyen d'éviter de répéter votre code, en extrayant les fonctionnalités communes et en les plaçant dans un modificateur qui peut être réutilisé dans toute la base de code.
Un modificateur ressemble beaucoup à une fonction. La chose clé à observer à propos d'un modificateur est l'endroit où le _ (souligné) apparaît. Ce souligné est comme un "espace réservé" pour indiquer quand la fonction principale s'exécutera. Il se lit comme si nous avions inséré la fonction principale là où se trouve actuellement le souligné.
Ainsi, dans l'extrait de modificateur ci-dessous, nous exécutons la vérification conditionnelle pour nous assurer que l'expéditeur du message est le propriétaire du contrat, et ensuite nous exécutons le reste de la fonction qui a appelé ce modificateur. Notez qu'un seul modificateur peut être utilisé par n'importe quel nombre de fonctions.

Comment les modificateurs de fonction sont écrits, et le rôle du symbole de soulignement
Dans cet exemple, l'instruction require() s'exécute avant le souligné (changeOwner()) et c'est la bonne façon de s'assurer que seul le propriétaire actuel peut changer qui possède le contrat.
Si vous inversiez les lignes du modificateur et que l'instruction require() venait en second, alors le code dans changeOwner() s'exécuterait en premier. Ce n'est qu'après cela que l'instruction require() s'exécuterait, et ce serait un bug assez malheureux !
Les modificateurs peuvent également prendre des entrées - vous passeriez simplement le type et le nom de l'entrée dans un modificateur.
modifier validAddress(address addr) {
// l'adresse ne doit pas être une adresse zéro.
require(addr != address(0), "Address invalid");
}
Les modificateurs sont un excellent moyen d'emballer des extraits de logique qui peuvent être réutilisés dans divers contrats intelligents qui alimentent ensemble votre dApp. La réutilisation de la logique rend votre code plus facile à lire, à maintenir et à raisonner - d'où le principe DRY (Ne vous répétez pas).
Gestion des erreurs en Solidity - Require, Assert, Revert
La gestion des erreurs en Solidity peut être réalisée à travers quelques mots-clés et opérations différents.
L'EVM annulera toutes les modifications de l'état de la blockchain lorsqu'il y a une erreur. En d'autres termes, lorsqu'une exception est levée et qu'elle n'est pas attrapée dans un bloc try-catch, l'exception "remontera" la pile des méthodes appelées et sera retournée à l'utilisateur. Toutes les modifications apportées à l'état de la blockchain dans l'appel actuel (et ses sous-appels) sont inversées.
Il existe certaines exceptions, dans les fonctions de bas niveau comme delegatecall, send, call, etc., où une erreur retournera le booléen false à l'appelant, plutôt que de faire remonter une erreur.
En tant que développeur, il existe trois approches que vous pouvez adopter pour gérer et lever des erreurs. Vous pouvez utiliser require(), assert() ou revert().
Une instruction require évalue une condition booléenne que vous spécifiez, et si elle est fausse, elle lèvera une erreur sans données, ou avec une chaîne que vous fournissez :
function requireExample() public pure {
require(msg.value >= 1 ether, "you must pay me at least 1 ether!");
}
Nous utilisons require() pour valider les entrées, valider les valeurs de retour et vérifier d'autres conditions avant de poursuivre avec notre logique de code.
Dans cet exemple, si l'appelant de la fonction n'envoie pas au moins 1 ether, la fonction annulera et lèvera une erreur avec un message de chaîne : "you must pay me at least 1 ether!".
La chaîne d'erreur que vous souhaitez retourner est le deuxième argument de la fonction require(), mais elle est facultative. Sans elle, votre code lèvera une erreur sans données - ce qui n'est pas très utile.
Le bon côté de require() est qu'il retournera le gaz qui n'a pas été utilisé, mais le gaz qui a été utilisé avant l'instruction require() sera perdu. C'est pourquoi nous utilisons require() le plus tôt possible.
Une fonction assert() est assez similaire à require() sauf qu'elle lève une erreur de type Panic(uint256) plutôt que Error(string).
contract ThrowMe {
function assertExample() public pure {
assert(address(this).balance == 0);
// Faire quelque chose.
}
}
Un assert est également utilisé dans des situations légèrement différentes - où un type de garde différent est requis.
Le plus souvent, vous utilisez un assert pour vérifier une pièce de données "invariante". En développement logiciel, un invariant est une ou plusieurs pièces de données dont la valeur ne change jamais pendant l'exécution du programme.
Dans l'exemple de code ci-dessus, le contrat est un petit contrat, et n'est pas conçu pour recevoir ou stocker de l'ether. Sa conception est meant pour s'assurer qu'il a toujours un solde de contrat de zéro, ce qui est l'invariant que nous testons avec un assert.
Les appels Assert() sont également utilisés dans les fonctions internes. Ils testent que l'état local ne contient pas de valeurs inattendues ou impossibles, mais qui peuvent avoir changé en raison de l'état du contrat devenant "sale".
Tout comme require(), un assert() annulera également toutes les modifications. Avant la version 0.8 de Solidity, assert() utilisait tout le gaz restant, ce qui était différent de require().
En général, vous utiliserez probablement require() plus que assert().
Une troisième approche consiste à utiliser un appel revert(). Cela est généralement utilisé dans la même situation qu'un require() mais où votre logique conditionnelle est beaucoup plus complexe.
De plus, vous pouvez lancer des erreurs personnalisées lorsque vous utilisez revert(). L'utilisation d'erreurs personnalisées peut souvent être moins coûteuse en termes de gaz utilisé, et est généralement plus informative du point de vue de la lisibilité du code et des erreurs.
Notez comment j'améliore la lisibilité et la traçabilité de mon erreur en préfixant le nom de mon erreur personnalisée avec le nom du contrat, afin que nous sachions quel contrat a lancé l'erreur.
contract ThrowMe {
// erreur personnalisée
error ThrowMe_BadInput(string errorMsg, uint inputNum);
function revertExample(uint input) public pure {
if (input < 1000 ) {
revert ThrowMe_BadInput("Number must be an even number greater than 999", input);
}
if (input < 0) {
revert("Negative numbers not allowed");
}
}
}
Dans l'exemple ci-dessus, nous utilisons revert une fois avec une erreur personnalisée qui prend deux arguments spécifiques, puis nous utilisons revert une autre fois avec seulement une donnée d'erreur de chaîne. Dans les deux cas, l'état de la blockchain est annulé et le gaz non utilisé sera retourné à l'appelant.
Héritage en Solidity
L'héritage est un concept puissant en programmation orientée objet (POO). Nous n'entrerons pas dans les détails de ce qu'est la POO. Mais la meilleure façon de raisonner sur l'héritage en programmation est de le considérer comme un moyen par lequel des morceaux de code "héritent" de données et de fonctions d'autres morceaux de code en les important et en les intégrant.
L'héritage en Solidity permet également à un développeur d'accéder, d'utiliser et de modifier les propriétés (données) et les fonctions (comportement) des contrats dont ils héritent.
Le contrat qui reçoit ce matériel hérité est appelé le contrat dérivé, le contrat enfant ou la sous-classe. Le contrat dont le matériel est mis à disposition d'un ou plusieurs contrats dérivés est appelé un contrat parent.
L'héritage facilite la réutilisation de code pratique et extensive - imaginez une chaîne de code d'application qui hérite d'un autre code, et ceux-ci à leur tour héritent d'autres et ainsi de suite. Plutôt que de taper toute la hiérarchie d'héritage, nous pouvons simplement utiliser quelques mots-clés pour "étendre" les fonctions et les données capturées par tout le code d'application dans la chaîne d'héritage. De cette manière, le contrat enfant bénéficie de tous les contrats parents dans sa hiérarchie, comme des gènes qui sont hérités à chaque génération.
Contrairement à certains langages de programmation comme Java, Solidity permet l'héritage multiple. L'héritage multiple fait référence à la capacité d'un contrat dérivé à hériter de données et de méthodes de plus d'un contrat parent. En d'autres termes, un contrat enfant peut avoir plusieurs parents.
Vous pouvez repérer un contrat enfant et identifier son contrat parent en cherchant le mot-clé is.
contract A {
string public constant A_NAME = "A";
function getName() public pure returns (string memory) {
return A_NAME;
}
}
contract B is A {
string public constant B_NAME = "B";
}
Si vous deviez déployer uniquement le Contrat B en utilisant l'IDE Remix dans le navigateur, vous noteriez que le Contrat B a accès à la méthode getName() même si elle n'a jamais été écrite comme faisant partie du Contrat B. Lorsque vous appelez cette fonction, elle retourne "A", qui est une donnée implémentée dans le Contrat A, et non dans le Contrat B. Le Contrat B a accès aux deux variables de stockage A_NAME et B_NAME, et à toutes les fonctions du Contrat A.
C'est ainsi que fonctionne l'héritage. C'est ainsi que le Contrat B réutilise le code déjà écrit dans le Contrat A, qui aurait pu être écrit par quelqu'un d'autre.
Solidity permet aux développeurs de changer la manière dont une fonction dans le contrat parent est implémentée dans le contrat dérivé. La modification ou le remplacement de la fonctionnalité du code hérité est appelé "override". Pour le comprendre, explorons ce qui se passe lorsque le Contrat B essaie d'implémenter sa propre fonction getName().
Modifiez le code en ajoutant un getName() au Contrat B. Assurez-vous que le nom de la fonction et la signature sont identiques à ceux du Contrat A. L'implémentation de la logique dans la fonction getName() d'un contrat enfant peut être totalement différente de celle du contrat parent, tant que le nom de la fonction et sa signature sont identiques.
contract A {
string public constant A_NAME = "A";
function getName() public returns (string memory) {
return A_NAME;
}
}
contract B is A {
string public constant B_NAME = "B";
function getName() public returns (string memory) {
Le compilateur vous donnera deux erreurs :
Dans le Contrat A, il indiquera que vous essayez de "remplacer une fonction non virtuelle" et vous suggérera d'ajouter le mot-clé
virtual.Dans le Contrat B, il se plaindra que la fonction
getName()manque du spécificateuroverride.
Cela signifie que votre nouveau getName dans le Contrat B tente de remplacer une fonction du même nom dans le contrat parent, mais la fonction du parent n'est pas marquée comme virtual - ce qui signifie qu'elle ne peut pas être remplacée.
Vous pourriez modifier la fonction du Contrat A et ajouter virtual comme suit :
function getName() public virtual returns (string memory) {
return A_NAME;
}
L'ajout du mot-clé virtual ne change pas le fonctionnement de la fonction dans le Contrat A. Et il n'oblige pas les contrats héritiers à devoir la réimplémenter ou la remplacer. Il signifie simplement que cette fonction peut être remplacée par n'importe quel contrat dérivé si le développeur le choisit.
L'ajout de virtual corrige la plainte du compilateur pour le Contrat A, mais pas pour le Contrat B. Cela est dû au fait que getName dans le Contrat B doit également ajouter le mot-clé override comme suit :
function getName() public pure override returns (string memory) {
return B_NAME;
}
Nous ajoutons également le mot-clé pure pour la fonction getName() du Contrat B car cette fonction ne change pas l'état de la blockchain et lit à partir d'une constante (les constantes, vous vous en souvenez, sont codées en dur dans le bytecode au moment de la compilation et ne sont pas dans l'emplacement de données de stockage).
Gardez à l'esprit que vous n'avez besoin de remplacer une fonction que si le nom et la signature sont identiques.
Mais que se passe-t-il avec les fonctions qui ont des noms identiques mais des arguments différents ? Lorsque cela se produit, ce n'est pas une substitution, mais une surcharge. Et il n'y a pas de conflit car les méthodes ont des arguments différents, et il y a donc suffisamment d'informations dans leurs signatures pour montrer au compilateur qu'elles sont différentes.
Par exemple, dans le contrat B, nous pourrions avoir une autre fonction getName() qui prend un argument, ce qui donne effectivement à la fonction une signature différente par rapport à l'implémentation de getName() du contrat parent A. Les fonctions surchargées n'ont pas besoin de mots-clés spéciaux :
// getName() accepte maintenant un argument de chaîne.
Ne vous inquiétez pas de l'appel de méthode abi.encodepacked(). Je l'expliquerai plus tard lorsque nous parlerons de l'encodage et du décodage. Pour l'instant, comprenez simplement que encodepacked() encode les chaînes en octets puis les concatène, et retourne un tableau d'octets.
Nous avons discuté de la relation entre les chaînes de caractères Solidity et les octets dans une section précédente de ce guide (sous Typage).
De plus, puisque vous avez déjà appris les modificateurs de fonction, c'est un bon endroit pour ajouter que les modificateurs sont également héritables. Voici comment vous le feriez :
contract A {
modifier X virtual {
// ... une certaine logique
Vous pourriez vous demander quelle version d'une fonction sera appelée si une fonction du même nom et de la même signature existe dans une chaîne d'héritage.
Par exemple, disons qu'il y a une chaîne de contrats hérités comme A → B → C → D → E et que tous ont un getName() qui remplace un getName() dans le contrat parent précédent.
Quel getName() est appelé ? La réponse est le dernier - l'implémentation "la plus dérivée" dans la hiérarchie des contrats.
Les variables d'état dans les contrats enfants ne peuvent pas avoir le même nom et le même type que leurs contrats parents.
Par exemple, le Contrat B ci-dessous ne se compilera pas car sa variable d'état "masque" celle du Contrat parent A. Mais notez comment le Contrat C gère correctement cela :
contract A {
string public author = "Zubin";
function getAuthor() public virtual returns (string memory) {
return author;
}
}
Il est important de noter qu'en passant une nouvelle valeur à la variable author dans le constructeur du Contrat C, nous remplaçons effectivement la valeur dans le Contrat A. Ensuite, l'appel de la méthode héritée C.getAuthor() retournera 'Hemingway' et non 'Zubin' !
Il est également intéressant de noter que lorsqu'un contrat hérite d'un ou plusieurs contrats parents, un seul contrat combiné est créé sur la blockchain. Le compilateur compile effectivement tous les autres contrats et leurs contrats parents et ainsi de suite jusqu'à toute la hiérarchie en un seul contrat compilé (qui est appelé un contrat "aplati").
Héritage avec paramètres de constructeur
Certains constructeurs spécifient des paramètres d'entrée et ont donc besoin que vous leur passiez des arguments lors de l'instanciation du contrat intelligent.
Si ce contrat intelligent est un contrat parent, alors ses contrats dérivés doivent également passer des arguments pour instancier les contrats parents.
Il existe deux façons de passer des arguments aux contrats parents - soit dans l'instruction qui liste les contrats parents, soit directement dans les fonctions de constructeur de chaque contrat parent. Vous pouvez voir les deux approches ci-dessous :
Dans la Méthode 2 du contrat ChildTwo, vous noterez que les arguments passés aux contrats parents sont d'abord fournis au contrat enfant puis simplement transmis dans la chaîne d'héritage.
Ce n'est pas nécessaire, mais c'est un modèle très courant. Le point clé est que lorsque les fonctions de constructeur des contrats parents attendent des données à leur être passées, nous devons les fournir lorsque nous instancions le contrat enfant.
Conversion de type et transtypage en Solidity
Parfois, nous devons convertir un type de données en un autre. Lorsque nous le faisons, nous devons être très prudents lors de la conversion des données et de la manière dont les données converties sont comprises par l'ordinateur.
Comme nous l'avons vu dans notre discussion sur les données typées, JavaScript peut parfois faire des choses étranges aux données parce qu'il est typé dynamiquement. Mais c'est aussi pourquoi il est utile d'introduire le concept de transtypage et de conversions de type en général.
Prenons le code JavaScript suivant :
var a = "1"
var b = a + 9 // nous obtenons la chaîne '19'!!
typeof a // string
typeof b // string
Il existe deux façons de convertir la variable a en un entier. La première, appelée transtypage, est effectuée explicitement par le programmeur et implique généralement un opérateur de type constructeur qui utilise ().
a = Number(a) // Le transtypage de la chaîne en nombre est explicite.
typeof a // number
var b = a + 9 // 10. Un nombre. Plus intuitif!
Maintenant, réinitialisons a en une chaîne de caractères et effectuons une conversion implicite, également connue sous le nom de conversion de type. Cela est implicitement fait par le compilateur lorsque le programme est exécuté.
_a = '1'
_var b = a * 9 // Contrairement à l'addition, cela ne concatène pas mais convertit implicitement 'a' en un nombre!
En Solidity, le transtypage (conversion explicite) est permis entre certains types, et ressemblerait à ceci :
uint256 a = 2022;
bytes32 b = bytes32(a);
Dans cet exemple, nous avons converti un entier avec une taille de 256 bits (puisque 8 bits font 1 octet, cela fait 32 octets) en un tableau d'octets de taille 32.
Puisque la valeur entière de 2022 et la valeur en octets sont toutes deux de longueur 32 octets, il n'y a pas eu de "perte" d'informations dans la conversion.
Mais que se passerait-il si vous essayiez de convertir 256 bits en 8 bits (1 octet) ? Essayez d'exécuter ce qui suit dans votre IDE Remix basé sur le navigateur :
contract Conversions {
function explicit256To8() public pure returns (uint8) {
uint256 a = 2022;
uint8 b = uint8(a);
return b; // 230.
}
Pourquoi l'entier 2022 est-il converti en 230 ? C'est clairement un changement indésirable et inattendu de la valeur. Un bug, non ?
La raison est qu'un entier non signé de taille 256 bits contiendra 256 chiffres binaires (soit 0 ou 1). Ainsi, a contient la valeur entière '2022' et cette valeur, en bits, aura 256 chiffres, dont la plupart seront 0, sauf les 11 derniers chiffres qui seront... (voyez par vous-même en convertissant 2022 du système décimal en binaire ici).
La valeur de b, en revanche, n'aura que 8 bits ou chiffres, soit 11100110. Ce nombre binaire, lorsqu'il est converti en décimal (vous pouvez utiliser le même convertisseur - il suffit de remplir l'autre case !), est 230. Pas 2022.
Oups.
Alors, que s'est-il passé ? Lorsque nous avons réduit la taille de l'entier de 256 bits à 8 bits, nous avons fini par supprimer les trois premiers chiffres de données (11111100110), ce qui a totalement changé la valeur en binaire !
Cela, mes amis, est une perte d'informations.
Ainsi, lorsque vous effectuez un transtypage explicite, le compilateur vous permettra de le faire dans certains cas. Mais vous pourriez perdre des données, et le compilateur supposera que vous savez ce que vous faites parce que vous demandez explicitement à le faire. Cela peut être la source de nombreux bugs, alors assurez-vous de tester correctement votre code pour obtenir les résultats attendus et soyez prudent lorsque vous effectuez un transtypage explicite de données vers des tailles plus petites.
Le transtypage vers des tailles plus grandes ne entraîne pas de perte de données. Puisque 2022 n'a besoin que de 11 bits pour être représenté, vous pourriez déclarer la variable a comme type uint16 puis la transtyper vers une variable b de type uint256 sans perte de données.
L'autre type de transtypage qui pose problème est lorsque vous effectuez un transtypage d'entiers non signés vers des entiers signés. Jouez avec l'exemple suivant :
contract Conversions {
function unsignedToSigned() public pure returns (int16, uint16) {
int16 a = -2022;
uint16 b = uint16(a);
// uint256 c = uint256(a); // Le compilateur se plaindra
return (a, b); // b est 63514
}
}
Notez que a, étant un entier signé de taille 16 bits, contient -2022 comme valeur (entier négatif). Si nous le transtypons explicitement en un entier non signé (valeurs positives uniquement), le compilateur nous permettra de le faire.
Mais si vous exécutez le code, vous verrez que b n'est pas -2022 mais 63,514 ! Parce que uint ne peut pas contenir d'informations concernant le signe moins, il a perdu ces données, et le binaire résultant est converti en un nombre décimal (base 10) massif - clairement indésirable, et un bug.
Si vous allez plus loin et décommentez la ligne qui attribue la valeur de c, vous verrez le compilateur se plaindre avec 'Explicit type conversion not allowed from "int16" to "uint256"'. Même si nous faisons un transtypage vers un plus grand nombre de bits dans uint256, parce que c est un entier non signé, il ne peut pas contenir d'informations sur le signe moins.
Ainsi, lors du transtypage explicite, assurez-vous de bien réfléchir à ce que la valeur évaluera après avoir forcé le compilateur à changer le type des données. C'est la source de nombreux bugs et erreurs de code.
Il y a plus à dire sur les conversions de type et le transtypage en Solidity, et vous pouvez approfondir certains des détails dans cet article.
Comment travailler avec les nombres à virgule flottante en Solidity
Solidity ne gère pas les points décimaux. Cela pourrait changer à l'avenir, mais actuellement, vous ne pouvez pas vraiment travailler avec des nombres à virgule fixe (flottants) comme 93,6. En fait, taper int256 floating = 93.6; dans votre IDE Remix générera une erreur comme : Error: Type rational_const 468 / 5 is not implicitly convertible to expected type int256.
Que se passe-t-il ici ? 468 divisé par 5 est 93,6, ce qui semble être une erreur étrange, mais c'est essentiellement le compilateur qui dit qu'il ne peut pas gérer les nombres à virgule flottante.
Suivez les suggestions de l'erreur et déclarez le type de la variable comme étant fixed ou ufixed16x1.
fixed floating = 93.6;
Vous obtiendrez une erreur "UnimplementedFeatureError: Not yet implemented - FixedPointType" .
Ainsi, en Solidity, nous contournons cela en convertissant le nombre à virgule flottante en un nombre entier (sans points décimaux) en le multipliant par 10 élevé à la puissance du nombre de décimales à droite du point décimal.
Dans ce cas, nous multiplions 93,6 par 10 pour obtenir 936 et nous devons garder une trace de notre facteur (10) dans une variable quelque part. Si le nombre était 93,2355, nous le multiplierions par 10 à la puissance 4 car nous devons déplacer la virgule de 4 places vers la droite pour rendre le nombre entier.
Lorsque nous travaillons avec des jetons ERC, nous noterons que les décimales sont souvent 10, 12 ou 18.
Par exemple, 1 Ether est égal à 1*(10^18) wei, ce qui correspond à 1 suivi de 18 zéros. Si nous voulions que cela soit exprimé avec une virgule flottante, nous devrions diviser 1000000000000000000 par 10^18 (ce qui nous donnera 1), mais si c'était 1500000000000000000 wei, alors diviser par 10^18 générera une erreur de compilation en Solidity, car il ne peut pas gérer la valeur de retour de 1,5.
En notation scientifique, 10^18 est également exprimé comme 1e18, où 1e représente 10 et le nombre qui suit représente l'exposant auquel 1e est élevé.
Ainsi, le code suivant produira une erreur de compilation : "Return argument type rational_const 3 / 2 is not implicitly convertible to expected type…int256" :
function divideBy1e18()public pure returns (int) {
return 1500000000000000000/(1e18); // 1.5 → Solidity ne peut pas gérer cela.
}
Le résultat de l'opération de division ci-dessus est 1,5, mais cela a un point décimal que Solidity ne supporte pas actuellement. Ainsi, les contrats intelligents Solidity retournent des nombres très grands, souvent jusqu'à 18 décimales, ce qui est plus que ce que JavaScript peut gérer. Vous devrez donc gérer cela de manière appropriée dans votre interface utilisateur en utilisant des bibliothèques JavaScript comme Ethersjs qui implémentent des fonctions d'assistance pour le type BigNumber.
Hachage, encodage et décodage ABI
À mesure que vous travaillez davantage avec Solidity, vous verrez des termes qui semblent étranges comme le hachage, l'encodage ABI et le décodage ABI.
Bien que ceux-ci puissent nécessiter un certain effort pour être compris, ils sont assez fondamentaux pour travailler avec la technologie cryptographique, et Ethereum en particulier. Ils ne sont pas complexes en principe, mais peuvent être un peu difficiles à saisir au début.
Commençons par le hachage. En utilisant les mathématiques cryptographiques, vous pouvez convertir n'importe quelle donnée en un entier unique (très grand). Cette opération est appelée hachage. Il y a quelques propriétés clés des algorithmes de hachage :
Ils sont déterministes - des entrées identiques produiront toujours une sortie identique, chaque fois et à chaque fois. Mais la chance de produire la même sortie en utilisant des entrées différentes est extrêmement improbable.
Il n'est pas possible (ou calculatoirement irréalisable) de rétro-concevoir l'entrée si vous n'avez que la sortie. C'est un processus à sens unique.
La taille (longueur) de la sortie est fixe - l'algorithme produira des sorties de taille fixe pour toutes les entrées, indépendamment de la taille de l'entrée. En d'autres termes, les sorties d'un algorithme de hachage auront toujours un nombre fixe de bits, selon l'algorithme.
Il existe de nombreux algorithmes qui sont des normes industrielles pour le hachage, mais vous verrez probablement SHA256 et Keccak256 le plus couramment. Ceux-ci sont très similaires. Et le 256 fait référence à la taille - le nombre de bits dans le hachage qui est produit.
Par exemple, allez sur ce site et copiez-collez "FreeCodeCamp" dans l'entrée de texte. En utilisant l'algorithme Keccak256, la sortie sera (toujours) 796457686bfec5f60e84447d256aba53edb09fb2015bea86eb27f76e9102b67a.
Il s'agit d'une chaîne hexadécimale de 64 caractères, et puisque chaque caractère dans une chaîne hex représente 4 bits, cette chaîne hexadécimale fait 256 bits (32 octets de long).
Maintenant, supprimez tout dans la boîte d'entrée de texte sauf le "F". Le résultat est une chaîne hexadécimale totalement différente, mais elle a toujours 64 caractères. C'est la nature "taille fixe" de l'algorithme de hachage Keccak265.
Maintenant, recopiez "FreeCodeCamp" et changez n'importe quel caractère. Vous pourriez mettre le "F" en minuscule. Ou ajouter un espace. Pour chaque changement individuel que vous faites, la sortie de la chaîne hexadécimale de hachage change beaucoup, mais la taille est constante.
C'est un avantage important des algorithmes de hachage. Le moindre changement modifie considérablement le hachage. Ce qui signifie que vous pouvez toujours tester si deux choses sont identiques (ou n'ont pas été altérées du tout) en comparant leurs hachages.
En Solidity, comparer les hachages est beaucoup plus efficace que comparer les types de données primitifs.
Par exemple, comparer deux chaînes de caractères est souvent fait en comparant les hachages de leur forme encodée en ABI (octets). Une fonction d'assistance courante pour comparer deux chaînes de caractères en Solidity ressemblerait à ceci :
function compareStrings(string memory str1, string memory str2)
public
pure
returns (bool)
{
return (keccak256(abi.encodePacked((str1))) ==
keccak256(abi.encodePacked((str2))));
}
Nous aborderons ce qu'est l'encodage ABI dans un instant, mais notez comment le résultat de encodePacked() est un tableau bytes qui est ensuite haché en utilisant l'algorithme keccak256 (c'est l'algorithme de hachage natif utilisé par Solidity). Les sorties hachées (entiers de 256 bits) sont comparées pour l'égalité.
Maintenant, tournons-nous vers l'encodage ABI. Tout d'abord, nous rappelons que l'ABI (Application Binary Interface) est l'interface qui spécifie comment interagir avec un contrat intelligent déployé. L'encodage ABI est le processus de conversion d'un élément donné de l'ABI en octets afin que l'EVM puisse le traiter.
L'EVM exécute des calculs sur des bits et des octets. Ainsi, l'encodage est le processus de conversion des données d'entrée structurées en octets afin qu'un ordinateur puisse les traiter. Le décodage est le processus inverse de conversion des octets en données structurées. Parfois, l'encodage est également appelé "sérialisation".
Vous pouvez en savoir plus sur les méthodes intégrées de Solidity fournies avec la variable globale abi qui effectuent différents types d'encodage et de décodage ici. Les méthodes qui encodent les données les convertissent en tableaux d'octets (type de données bytes). À l'inverse, les méthodes qui décodent leurs entrées attendent le type de données bytes comme entrée et le convertissent ensuite en les types de données qui ont été encodés.
Vous pouvez observer cela dans l'extrait suivant :
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.13;
contract EncodeDecode {
J'ai exécuté ce qui précède dans Remix et utilisé les entrées suivantes pour encode() : 1981, 0x3C44CdDdB6a900fa2b585dd299e03d12FA4293BC, [1,2,3,4].
Et les octets que j'ai obtenus en retour étaient représentés sous forme hexadécimale comme suit :
0x00000000000000000000000000000000000000000000000000000000000007bd0000000000000000000000003c44cdddb6a900fa2b585dd299e03d12fa4293bc000000000000000000000000000000000000000000000000000000000000006000000000000000000000000000000000000000000000000000000000000000040000000000000000000000000000000000000000000000000000000000000001000000000000000000000000000000000000000000000000000000000000000200000000000000000000000000000000000000000000000000000000000000030000000000000000000000000000000000000000000000000000000000000004
J'ai utilisé cela comme mon entrée dans la fonction decode() et j'ai récupéré mes trois arguments originaux.
Ainsi, le but de l'encodage est de convertir les données en le type de données bytes dont l'EVM a besoin pour traiter les données. Et le décodage les ramène aux données structurées lisibles par l'homme avec lesquelles nous, développeurs, pouvons travailler.
Comment appeler des contrats et utiliser la fonction de repli
Selon la conception du contrat intelligent et les spécificateurs de visibilité présents, le contrat peut être interagi avec d'autres contrats intelligents ou par des comptes détenus en externe.
Appeler depuis votre portefeuille via Remix est un exemple de ce dernier, tout comme l'utilisation de Metamask. Vous pouvez également interagir avec des contrats intelligents de manière programmatique via des bibliothèques comme EthersJS et Web3JS, les chaînes d'outils Hardhat et Truffle, et ainsi de suite.
Aux fins de ce guide Solidity, nous utiliserons Solidity pour interagir avec un autre contrat.
Il existe deux façons pour un contrat intelligent d'appeler d'autres contrats intelligents. La première façon appelle le contrat cible directement, en utilisant des interfaces (que nous avons discutées précédemment). Ou, si le contrat cible est importé dans la portée du contrat appelant, il l'appelle directement.
Cette approche est illustrée ci-dessous :
contract Target {
int256 public count;
function decrement() public {
count--;
}
}
interface ITarget {
function decrement() external;
}
contract TargetCaller {
function callDecrementInterface(address _target) public {
ITarget target = ITarget(_target);
target.decrement();
}
function callDecrementDirect(Target _target) public {
_target.decrement();
}
}
Dans Remix, vous pouvez déployer Target en premier, et appeler count() pour voir que la valeur par défaut de la variable count est 0, comme prévu. Cette valeur sera décrémentée de 1 si vous appelez la méthode decrement().
Ensuite, vous pouvez déployer TargetCaller et il y a deux méthodes que vous pouvez appeler, toutes deux décrémenteront la valeur de count dans Target.
Notez que chacune de ces deux méthodes accède au contrat Target en utilisant une syntaxe légèrement différente. Lorsque vous interagissez en utilisant l'interface ITarget, la première méthode prend l'adresse de Target alors que la deuxième méthode traite Target comme un type personnalisé.
Cette deuxième approche n'est possible que lorsque le contrat Target est déclaré dans, ou importé dans, le même fichier que TargetCaller. Le plus souvent, vous interagirez avec des contrats intelligents déployés par des tiers, pour lesquels ils publient des interfaces ABI.
Chaque fois que vous appelez ces méthodes, la valeur de count dans Target diminuera de 1. C'est une manière très courante d'interagir avec d'autres contrats intelligents.
La deuxième façon de le faire est d'utiliser la syntaxe d'appel "de bas niveau" que Solidity fournit. Vous l'utilisez lorsque vous souhaitez également envoyer un peu d'éther (valeur) au contrat cible. Nous parlerons de l'envoi de valeur dans la section suivante, mais pour l'instant, remplacez simplement le code dans Remix par ce qui suit :
contract Target {
int256 public count;
function decrement(int num) public payable {
count = count - num;
}
}
interface ITarget {
function decrement(int num) external payable;
}
contract TargetCaller {
function callDecrementLowLevel(address _target) public {
ITarget target = ITarget(_target);
target.decrement{value:0}(5);
}
// autres fonctions de décrémentation...
}
Vous noterez que decrement() prend maintenant un argument, et l'interface et le contrat Target sont mis à jour avec cette nouvelle donnée d'entrée.
Ensuite, notez que TargetCaller implémente une nouvelle fonction qui appelle decrement() avec une nouvelle syntaxe, expliquée ci-dessous.
Dans la section suivante, nous verrons des exemples de ces façons de bas niveau d'appeler un contrat intelligent cible pour lui envoyer de l'Ether.
Mais que se passe-t-il lorsque vous appelez un contrat et qu'il n'a pas réellement la fonction que vous avez essayée d'appeler ?
Cela peut se produire de manière malveillante pour exploiter le fonctionnement de Solidity sur l'EVM. Ou, plus couramment, cela peut se produire accidentellement. Cela se produit lorsque, par exemple, il y a une erreur dans l'Interface et que le compilateur ne peut pas faire correspondre la fonction et les paramètres que vous avez envoyés avec ceux qui sont réellement contenus dans le contrat. Que se passe-t-il alors ?
Pour ces situations, de nombreux contrats emploient une fonction spéciale appelée la fonction de repli. La fonction ressemble à une fonction normale mais elle n'a pas besoin du mot-clé function. Si vous voulez qu'elle gère également les situations où votre contrat reçoit de l'éther, vous devez également la marquer payable. Mais ce n'est pas la manière recommandée d'activer votre contrat pour recevoir des paiements.
Prenons un exemple en réutilisant notre Target, ITarget et TargetCaller précédents et en ajoutant une fonction de repli comme suit :
contract Target {
int256 public count;
function decrement(int num) public payable {
count = count - num;
}
fallback() external payable {
count++;
}
}
interface ITarget {
function decrement(int num) external payable;
function nonExistentFunction() external;
}
contract TargetCaller {
function callFallback(address _target) public {
ITarget target = ITarget(_target);
target.nonExistentFunction();
}
}
Une fois que nous déployons une nouvelle instance de Target, nous pouvons appeler count() et voir qu'elle est définie sur la valeur par défaut de zéro.
Ensuite, nous pouvons déployer TargetCaller et appeler la méthode callFallback() qui appelle en interne nonExistentFunction().
Il est intéressant de noter que l'interface indique que nonExistentFunction() est disponible mais que le contrat Target réel n'a aucune fonction de ce type. C'est pourquoi la fonction de repli de Target est déclenchée et la valeur de count est maintenant incrémentée de 1.
Le but de la fonction de repli est de gérer les appels au contrat où aucune autre fonction n'est disponible pour le gérer. Et si le repli est marqué payable, la fonction de repli permettra également au contrat intelligent de recevoir de l'Ether (bien que ce ne soit pas l'utilisation recommandée pour le repli). Nous aborderons cela dans la section suivante.
Comment envoyer et recevoir de l'Ether
Pour envoyer de l'Ether à un contrat cible depuis votre contrat intelligent, vous devez appeler le contrat cible en utilisant l'une des trois méthodes intégrées de Solidity suivantes : transfer, send ou call.
transfer lèvera une exception en cas d'échec, et send et call retourneront un booléen que vous devez vérifier avant de continuer. Parmi ces trois méthodes, transfer et send ne sont plus recommandées pour des raisons de sécurité, bien que vous puissiez toujours les utiliser et elles fonctionneront.
Les contrats intelligents ne peuvent pas recevoir d'Ether sauf dans les scénarios suivants :
Ils implémentent une fonction
payablede repli ou une fonction spécialepayablede réception, ouDe manière forcée lorsque le contrat appelant appelle
selfdestructet force un contrat cible à accepter tout son Ether restant. Le contrat appelant est ensuite supprimé de la blockchain. C'est un sujet séparé et est souvent utilisé de manière malveillante par des exploiteurs.
Il est généralement recommandé d'utiliser une fonction receive() si vous souhaitez que votre contrat intelligent reçoive de l'Ether. Vous pouvez vous en sortir en rendant simplement votre fonction de repli payable, mais la pratique recommandée est d'utiliser une fonction receive().
Si vous vous fiez uniquement à la fonction de repli, votre compilateur vous grondera avec le message suivant : "Warning: This contract has a payable fallback function, but no receive ether function. Consider adding a receive ether function."
Si vous avez à la fois receive et fallback, vous pouvez légitimement vous demander comment Solidity décide quelle fonction utiliser pour recevoir de l'Ether. Cette décision de conception vous indique également ce que ces fonctions sont censées faire.
Receive est destiné à recevoir de l'ether. Et fallback est destiné à gérer les situations où le contrat a été appelé mais, comme nous l'avons discuté dans la section précédente, il n'y a pas de méthode correspondante dans le contrat qui peut gérer l'appel.
Solidity fait correspondre la méthode qui était censée être appelée en vérifiant le champ msg.data dans la transaction envoyée par l'appelant. Si ce champ a une valeur non vide, et que cette valeur ne correspond à aucune autre fonction déclarée dans le contrat appelé, alors la méthode de repli est déclenchée.
Si msg.data est vide, alors il vérifiera s'il y a une fonction receive qui a été implémentée. Si c'est le cas, il l'utilisera pour accepter l'Ether. Si aucun receive n'existe, il utilisera par défaut la fonction de repli. Le repli est donc la méthode de repli (par défaut) lorsque rien d'autre n'a de sens.
La fonction receive est la meilleure façon d'activer votre contrat pour recevoir de l'Ether. Vous pouvez utiliser la fonction de repli pour tout scénario où votre contrat intelligent est appelé mais où il n'y a rien pour "gérer" cet appel.
Voici un arbre logique super pratique qui montre ce que receive et fallback sont censés gérer.
Quelle fonction est appelée, fallback() ou receive()?
envoyer Ether
|
msg.data est vide?
/ \
oui non
/ \
receive() existe? fallback()
/ \
oui non
/ \
receive() fallback()
(crédit : Solidity By Example)
En revenant à notre exemple où nous avons exploré la fonction de repli, nous pouvons ajouter une fonction receive à Target comme suit :
contract Target {
int256 public count;
function decrement() public payable {
count = count - num;
}
fallback() external payable {
count++;
}
Nous avons déjà vu comment callFallback changera la valeur de count dans Target. Mais si nous déployons une nouvelle instance de Target, nous pouvons maintenant lui envoyer 10 wei, comme montré ci-dessous, car il a maintenant une fonction payable receive. Avant d'envoyer 10 wei (ou tout autre montant), Target a un solde de zéro, comme montré ci-dessous.
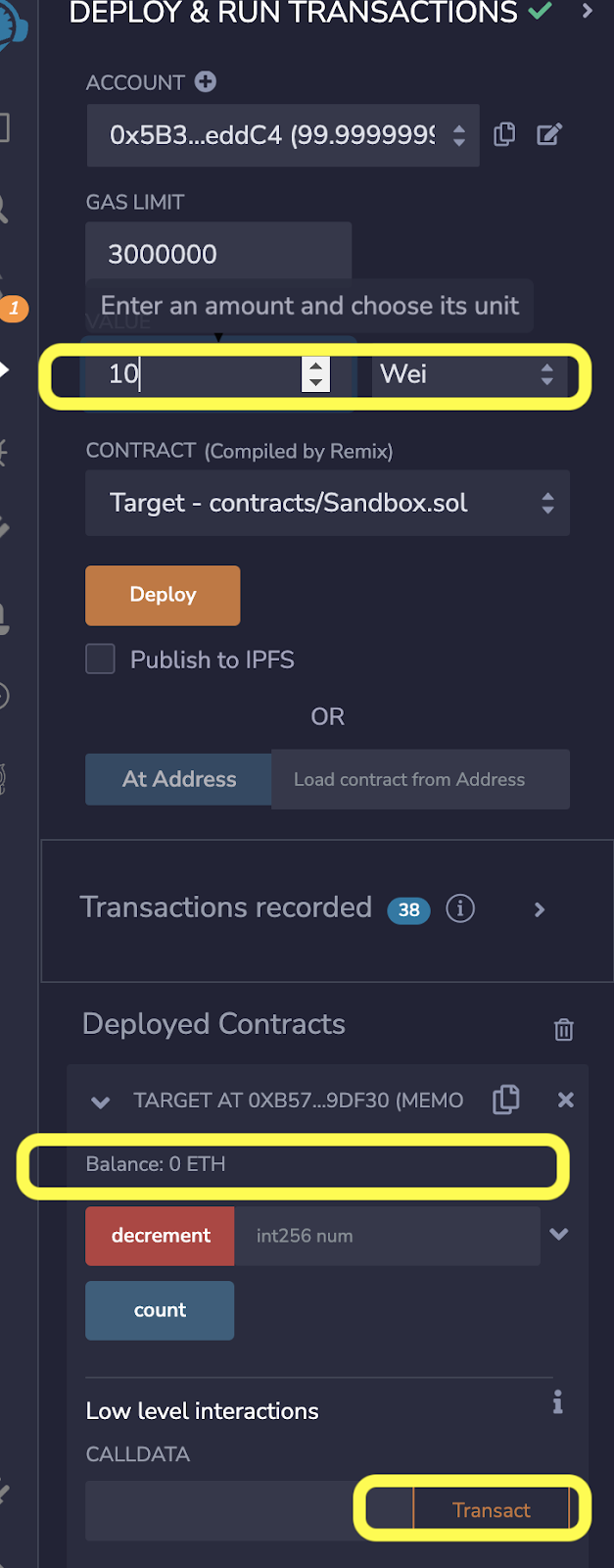
Appuyer sur le bouton Transact avec des calldata vides (msg.data) changera le solde comme montré dans l'image ci-dessous. Nous pouvons vérifier count pour voir qu'il est incrémenté de 5, ce qui est la logique dans la fonction receive.
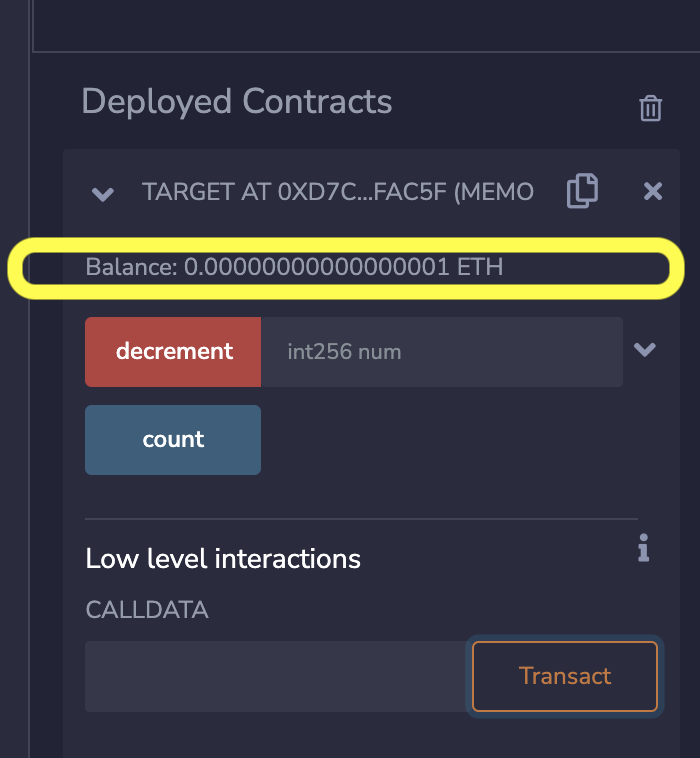
Envoyer des Wei au contrat cible et observer le solde mis à jour
Si nous appelons callFallback et lui donnons l'adresse de la nouvelle instance de Target, nous noterons qu'il n'incrémente que de 1. Si nous incluons un peu de wei, cela augmentera également le solde de Target.
Ainsi, tout transfert d'Ether vers un contrat intelligent nécessiterait que le contrat intelligent receveur ait des fonctions payable qui peuvent le recevoir. Au minimum, le contrat intelligent receveur aurait besoin d'une fonction de repli payable, bien qu'une fonction payable receive soit la meilleure approche pour recevoir des paiements en Ether.
Bibliothèques Solidity
Dans tout langage de programmation, une bibliothèque fait référence à une collection de fonctions d'assistance et utilitaires conçues pour être réutilisables dans plusieurs bases de code. Ces fonctions résolvent des problèmes de programmation spécifiques et récurrents.
En Solidity, les bibliothèques servent le même but, mais ont des attributs spéciaux.
Tout d'abord, elles sont sans état - c'est-à-dire qu'elles ne stockent pas de données (autres que les constantes car celles-ci ne changent pas l'état de la blockchain). Elles ne peuvent pas non plus recevoir de valeur (ce qui signifie qu'elles ne peuvent pas avoir de fonctions payable receive ou fallback).
Elles ne peuvent pas non plus hériter d'autres contrats ou bibliothèques, ni les bibliothèques ne peuvent avoir des contrats enfants (dérivés).
Toutes les fonctions déclarées dans une bibliothèque ne doivent pas être abstraites - c'est-à-dire qu'elles doivent toutes avoir des implémentations concrètes.
Puisque les bibliothèques Solidity sont sans état, aucune des méthodes qu'elles contiennent ne peut modifier l'état de la blockchain. Cela signifie que toutes les méthodes à l'intérieur des bibliothèques sont des fonctions pure ou view.
Un autre attribut intéressant des bibliothèques Solidity est qu'elles n'ont pas besoin d'être importées dans votre contrat intelligent. Elles peuvent être déployées en tant que contrats autonomes et ensuite appelées via leur interface dans tous les contrats intelligents consommateurs - tout comme vous le feriez avec un service API dans le monde de l'ingénierie traditionnelle.
Cependant, cela n'est vrai que lorsque la bibliothèque contient des méthodes publiques ou externes. Ensuite, cette bibliothèque peut être déployée en tant que contrat autonome avec sa propre adresse Ethereum, et devient appelable par tous les contrats intelligents consommateurs.
Si les bibliothèques ne contiennent que des méthodes internes, alors l'EVM "intègre" simplement le code de la bibliothèque dans le contrat intelligent qui utilise la bibliothèque (parce que les fonctions internes ne peuvent pas être accessibles depuis d'autres contrats intelligents).
Les bibliothèques en Solidity présentent des avantages qui vont au-delà de la réutilisation de code. Déployer une bibliothèque une seule fois sur la blockchain peut permettre d'économiser sur les coûts futurs de gaz en évitant le déploiement ou l'importation répétée du code de la bibliothèque.
Examinons une bibliothèque simple puis analysons le code pour comprendre comment utiliser le code de la bibliothèque.
library WeirdMath {
int private constant factor = 100;
function applyFactor(int self) public pure returns (int) {
return self * factor;
}
function add(int self, int numberToAdd) public pure returns (int) {
return self + numberToAdd;
}
}
Cette bibliothèque possède deux méthodes qui opèrent sur le type de données int. Le premier argument est appelé self pour des raisons qui deviendront claires sous peu. Une méthode prend un nombre puis le multiplie par une valeur constante stockée dans le code de la bibliothèque. La deuxième méthode prend deux nombres et les additionne.
Maintenant, voyons comment nous pouvons utiliser cela dans un contrat intelligent consommateur.
// SPDX-License-Identifier: MIT
pragma solidity >=0.5.22 <=0.8.17;
contract StrangeMath {
// Méthode 1 - utiliser le nom de la bibliothèque avec la notation par points
function multiplyWithFactor(int num) public pure returns (int) {
return WeirdMath.applyFactor(num);
}
// Méthode 2 - le mot-clé 'using' et la notation par points.
// Syntaxe : using <<Library Name>> for data type of the first argument in the method to be called.
using WeirdMath for int;
function addTwoNums(int num1, int num2) public pure returns (int) {
return num1.add(num2);
}
}
La première chose à noter est qu'il existe deux façons d'utiliser la bibliothèque WeirdMath.
Vous pouvez l'utiliser soit :
En invoquant le nom de la bibliothèque suivi de la fonction que vous souhaitez appeler, soit
En appelant la fonction directement sur le type de données sur lequel vous souhaitez que la fonction opère. Ce type de données doit être identique au type du paramètre
selfdans la fonction de la bibliothèque.
La première approche est démontrée par la méthode 1 dans l'extrait de code où nous invoquons la bibliothèque avec WeirdMath.add(num1, num2).
La deuxième approche utilise le mot-clé using de Solidity. L'expression return num1.add(num2); applique la fonction add de la bibliothèque WeirdMath à la variable num1. C'est la même chose que de la passer en tant que self, qui est le premier argument de la fonction add.
Événements et journaux en Solidity
Les contrats intelligents peuvent émettre des événements. Les événements contiennent des morceaux de données que vous, en tant que développeur, spécifiez.
Les événements ne peuvent pas être consommés par d'autres contrats intelligents. Au lieu de cela, ils sont stockés sur la blockchain sous forme de journaux, et peuvent être récupérés via les API qui lisent depuis la blockchain.
Cela signifie que votre application (le plus souvent votre application frontale) peut "lire" les journaux qui contiennent les données de l'événement depuis la blockchain. De cette manière, votre interface utilisateur peut répondre aux événements sur la blockchain.
C'est ainsi que les interfaces utilisateur des applications sont mises à jour pour répondre aux événements sur la chaîne. Puisque ces journaux sur la blockchain peuvent être interrogés, les journaux sont une forme de stockage bon marché, comme discuté précédemment dans la discussion sur les zones de stockage.
Les événements émis par un contrat intelligent peuvent être inspectés en utilisant l'explorateur de blockchain pertinent, car tout sur une blockchain publique est publiquement visible. Mais si le bytecode du contrat intelligent n'a pas été vérifié, les données de l'événement peuvent ne pas être lisibles par l'homme (elles seront encodées). Les événements des contrats intelligents vérifiés seront lisibles par l'homme.
Les nœuds et autres clients de blockchain peuvent écouter (s'abonner à) des événements spécifiques. Au cœur de cela, c'est ainsi que fonctionnent les Oracles Chainlink - les nœuds d'oracle décentralisés écoutent les événements des contrats intelligents, puis répondent en conséquence. Ils peuvent même extraire des données des événements, exécuter des calculs complexes et intensifs en ressources hors chaîne, puis soumettre des résultats de calcul cryptographiquement vérifiables sur la blockchain.
D'autres API de réseau et services d'indexation comme les sous-graphes sont rendus possibles grâce à la capacité d'interroger les données de la blockchain via les événements émis par les contrats intelligents.
Voici à quoi ressemble un Événement en Solidity :
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.7;
contract SimpleStorage {
uint256 favoriteNumber;
event storedNumber(
uint256 indexed oldNumber, // jusqu'à 3 paramètres indexés autorisés
uint256 indexed newNumber,
uint256 addedNumber,
address sender
);
function store(uint256 newNumber) public {
emit storedNumber(
favoriteNumber,
newNumber,
newNumber + favoriteNumber,
msg.sender
);
favoriteNumber = newNumber;
}
function retrieve() public view returns (uint256) {
return favoriteNumber;
}
}
Un événement est d'abord déclaré, et ses arguments et leurs types de données sont spécifiés. Toute donnée qui a le mot-clé indexed est indexée par l'EVM afin que les requêtes sur les journaux de la blockchain puissent utiliser le paramètre indexé comme filtre. Cela rend la récupération des journaux plus rapide.
Un événement peut stocker jusqu'à 4 paramètres indexés - selon qu'il est anonyme ou non anonyme. Les paramètres d'événement indexés sont également appelés "Topics" dans le monde Solidity.
La plupart des événements sont non anonymes, ce qui signifie qu'ils incluent des données sur le nom et les arguments de l'événement.
Les événements non anonymes permettent au développeur de spécifier seulement 3 topics car le premier topic est réservé pour spécifier la signature de l'événement en hexadécimal encodé ABI. Vous pouvez en savoir plus sur les topics anonymes et non anonymes ici.
Vous pouvez également explorer les événements sur l'explorateur de blockchain pertinent (comme etherscan.io).
Vous pouvez aborder cela à partir de deux points d'entrée. Vous pouvez regarder l'adresse du contrat directement puis aller à l'onglet Événements (qui vous montrera les événements émis par ce contrat uniquement). Ou vous pouvez aller à un hachage de transaction et examiner tous les événements émis par tous les contrats qui ont été touchés par cette transaction.
Par exemple, ci-dessous se trouve une capture d'écran des événements du contrat intelligent Chainlink VRF Coordinator sur le réseau principal Ethereum.

Inspection des événements du contrat Chainlink VRF Coordinator sur etherscan
L'onglet contrat a une coche verte, ce qui signifie que le contrat est vérifié, et donc le nom de l'événement et les arguments sont lisibles par l'homme. Prenez un moment pour étudier cette image car elle contient beaucoup d'informations ! Si vous souhaitez l'étudier directement sur etherscan, cliquez ici.
Ce contrat Chainlink VRF Coordinator répond aux demandes de nombres aléatoires cryptographiquement vérifiables, et fournit au contrat intelligent demandeur des nombres aléatoires (appelés "mots aléatoires").
Si vous souhaitez savoir ce que signifie "mot" en informatique, consultez mon collègue et moi-même abordant cette question dans cette vidéo du Hackathon Chainlink 2022).
Lorsque le contrat VRF Coordinator satisfait la demande de nombres aléatoires, il émet un événement RandomWordsFulfilled. Cet événement contient 4 morceaux de données, dont le premier, requestID, est indexé.
Les événements Solidity contiennent trois catégories de données :
L'adresse du contrat qui a émis l'événement.
Les topics (paramètres d'événement indexés utilisés pour filtrer les requêtes des journaux).
Les paramètres non indexés, appelés "data", et ils sont encodés en ABI et représentés en hexadécimal. Ces données doivent être décodées en ABI, de la manière décrite dans la section sur l'encodage et le décodage ABI.
Lorsque vous travaillez dans Remix, vous pouvez également inspecter les Événements dans la console comme montré ci-dessous :
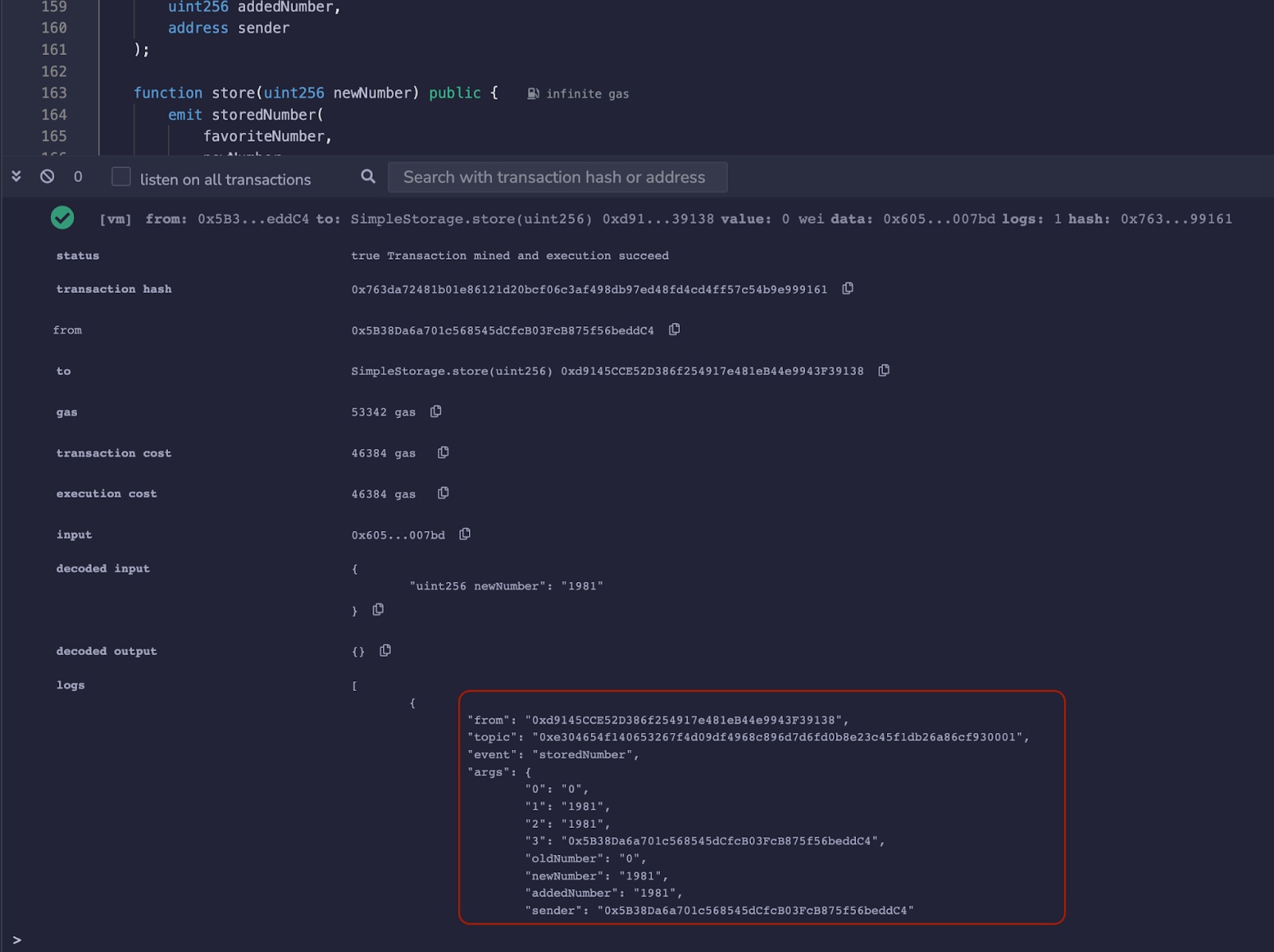
Inspection des données d'événement dans l'IDE Remix Browser
Vous pouvez également accéder de manière programmatique aux événements en utilisant l'objet de reçus de contrat dans EthersJS. En utilisant l'extrait de code que nous avons utilisé ci-dessus dans le contrat SimpleStorage, nous pouvons accéder aux événements en utilisant EthersJS et Hardhat avec le JavaScript suivant :
const transactionResponse = await simpleStorage.store(1981)
const receipt = await transactionResponse.wait()
console.log(receipt.events[0].args.newNumber.toString()) // 1981
Vous pouvez également utiliser des bibliothèques telles que la bibliothèque EtherJs dans votre application frontale pour écouter les événements et filtrer les événements historiques. Les deux sont utiles lorsque votre application doit répondre aux événements sur la blockchain.
Logique temporelle en Solidity
Le temps en Solidity est spécifié en relation avec chaque bloc qui est ajouté à la blockchain.
La variable globale block.timestamp fait référence au temps, en millisecondes, auquel le bloc a été généré et ajouté à la blockchain. Le compte des millisecondes fait référence au nombre de millisecondes qui se sont écoulées depuis le début de l'époque Unix (en informatique, c'est le 1er janvier 1970).
Contrairement aux références Web2 aux timestamps en millisecondes, la valeur peut ne pas s'incrémenter à chaque milliseconde.
Un bloc contient souvent plusieurs transactions, et puisque block.timestamp fait référence au moment où le bloc a été miné, toutes les transactions dans un bloc miné auront la même valeur de timestamp. Ainsi, le timestamp fait vraiment référence au temps du bloc, et non tant au moment où l'appelant a initié la transaction.
Solidity supporte directement les unités de temps suivantes : secondes, minutes, heures, jours et semaines.
Ainsi, nous pourrions faire quelque chose comme uint lastWeek = block.timestamp - 1 weeks; pour calculer le timestamp d'exactement 1 semaine avant que ce bloc actuel ne soit miné, jusqu'aux millisecondes. Cette valeur serait la même que block.timestamp - 7 days;.
Vous pouvez également utiliser cela pour calculer les dates d'expiration futures, où, par exemple, vous pourriez vouloir qu'une opération soit possible entre maintenant et la semaine prochaine. Vous pourriez faire cela avec uint registrationDeadline = block.timestamp + 1 weeks; et ensuite nous pourrions utiliser le registrationDeadline comme validation ou garde dans une fonction comme suit :
function registerVoter(address voter) public view {
require(block.timestamp <= registrationDeadline, "registration deadline has passed.");
// Enregistrer le votant....
}
Dans cette fonction, nous enregistrons le votant uniquement si le timestamp du bloc actuel n'est pas passé la date limite d'enregistrement.
Cette logique est utilisée de manière extensive lorsque nous voulons nous assurer que certaines opérations sont effectuées au bon moment, ou dans un intervalle.
C'est également l'une des façons dont Chainlink Automation, une manière décentralisée d'automatiser l'exécution de votre contrat intelligent, peut être configurée. Le réseau d'oracles décentralisés Chainlink peut être configuré pour déclencher automatiquement vos contrats intelligents, et vous pouvez exécuter une large variété d'automatisations en vérifiant des conditions, y compris des conditions liées au temps. Ceux-ci sont utilisés de manière extensive pour les airdrops, les promotions, les récompenses spéciales, les earn-outs et ainsi de suite.
Conclusion et ressources supplémentaires
Félicitations ! Vous avez réussi ce voyage épique. Si vous avez investi du temps à assimiler ce guide et exécuté certains des codes dans l'IDE Remix, vous êtes maintenant formé à Solidity.
À partir de maintenant, c'est une question de pratique, de répétition et d'expérience. Alors que vous construisez votre prochaine application décentralisée géniale, n'oubliez pas de revenir aux bases et de vous concentrer sur la sécurité. La sécurité est particulièrement importante dans l'espace Web3.
Vous pouvez obtenir de bonnes informations sur les meilleures pratiques à partir des blogs d'OpenZeppelin et des ressources de Trail of Bits, entre autres.
Vous pouvez également obtenir plus d'expérience pratique en suivant le cours complet de développeur blockchain full-stack de bout en bout que mon collègue Patrick Collins a publié sur freeCodeCamp (c'est gratuit !).
Il existe d'autres ressources comme blockchain.education et le prochain programme Web3 de freeCodeCamp qui peuvent consolider vos apprentissages.
Dans tous les cas, ce guide peut être votre "compagnon de bureau" pour ce rafraîchissement rapide des concepts de base, quel que soit votre niveau d'expérience.
L'important à retenir est que la technologie Web3 est toujours en évolution. Il y a un besoin urgent de développeurs prêts à relever des défis complexes, à apprendre de nouvelles compétences et à résoudre des problèmes importants qui accompagnent l'architecture décentralisée.
Cela pourrait (et devrait) être vous ! Alors suivez simplement votre curiosité et n'ayez pas peur de lutter en cours de route.
Et encore une fois, j'ai l'intention de garder ce guide à jour. Donc si vous voyez quelque chose qui n'est pas tout à fait correct, est obsolète ou peu clair, mentionnez-le simplement dans un tweet et taggez-moi ainsi que freeCodeCamp - un grand coup de chapeau à vous tous pour faire partie de la mise à jour de ce guide.
Maintenant... allez être génial !
Post Scriptum
Si vous êtes sérieux à propos d'un changement de carrière vers le code, vous pouvez en savoir plus sur mon parcours d'avocat à ingénieur logiciel. Consultez l'épisode 53 du podcast freeCodeCamp ainsi que l'épisode 207 de "Lessons from a Quitter". Ceux-ci fournissent le plan de mon changement de carrière.
Si vous êtes intéressé par un changement de carrière et devenir un codeur professionnel, n'hésitez pas à me contacter ici. Vous pouvez également consulter mon webinaire gratuit sur le changement de carrière vers le code si c'est ce dont vous rêvez.