

![Apprendre Linux pour les débutants : des bases aux techniques avancées [Livre complet]](https://cdn.hashnode.com/res/hashnode/image/upload/v1720790242560/764782a4-1bf3-45a5-857c-7fe3921bfb08.png)
Article original : Learn Linux for Beginners: From Basics to Advanced Techniques [Full Book]
Apprendre Linux est l'une des compétences les plus précieuses dans l'industrie technologique. Cela peut vous aider à accomplir vos tâches plus rapidement et plus efficacement. De nombreux serveurs puissants et supercalculateurs dans le monde fonctionnent sous Linux.
Tout en vous donnant plus d'autonomie dans votre rôle actuel, l'apprentissage de Linux peut également vous aider à évoluer vers d'autres carrières technologiques comme le DevOps, la cybersécurité et le Cloud Computing.
Dans ce manuel, vous apprendrez les bases de la ligne de commande Linux, puis vous passerez à des sujets plus avancés comme le scripting bash et l'administration système. Que vous soyez novice sous Linux ou que vous l'utilisiez depuis des années, ce livre a quelque chose à vous offrir.
Note importante : Tous les exemples de ce livre sont démontrés sous Ubuntu 22.04.2 LTS (Jammy Jellyfish). La plupart des outils en ligne de commande sont plus ou moins identiques dans les autres distributions. Cependant, certaines applications graphiques (GUI) et commandes peuvent différer si vous travaillez sur une autre distribution Linux.
Table des matières
Partie 2 : Introduction au shell Bash et aux commandes système
Partie 4 : Gérer les fichiers depuis la ligne de commande
[4.1. La hiérarchie du système de fichiers Linux][11]
Partie 1 : Introduction à Linux
1.1. Premiers pas avec Linux
Qu'est-ce que Linux ?
Linux est un système d'exploitation open-source basé sur le système d'exploitation Unix. Il a été créé par Linus Torvalds en 1991.
Open-source signifie que le code source du système d'exploitation est accessible au public. Cela permet à quiconque de modifier le code original, de le personnaliser et de distribuer le nouveau système d'exploitation à des utilisateurs potentiels.
Pourquoi devriez-vous apprendre Linux ?
Dans le paysage actuel des centres de données, Linux et Microsoft Windows s'imposent comme les principaux concurrents, Linux détenant une part majeure.
Voici plusieurs raisons convaincantes d'apprendre Linux :
Étant donné la prévalence de l'hébergement Linux, il y a de fortes chances que votre application soit hébergée sous Linux. Apprendre Linux en tant que développeur devient donc de plus en plus précieux.
Le cloud computing étant devenu la norme, il est fort probable que vos instances cloud reposent sur Linux.
Linux sert de base à de nombreux systèmes d'exploitation pour l'Internet des objets (IoT) et les applications mobiles.
En informatique, il existe de nombreuses opportunités pour ceux qui maîtrisent Linux.
Que signifie le fait que Linux soit un système d'exploitation open-source ?
Tout d'abord, qu'est-ce que l'open-source ? Un logiciel open-source est un logiciel dont le code source est librement accessible, permettant à quiconque de l'utiliser, de le modifier et de le distribuer.
Dès qu'un code source est créé, il est automatiquement considéré comme protégé par le droit d'auteur, et sa distribution est régie par le détenteur du droit d'auteur via des licences logicielles.
Contrairement à l'open-source, les logiciels propriétaires ou à code fermé restreignent l'accès à leur code source. Seuls les créateurs peuvent le visualiser, le modifier ou le distribuer.
Linux est principalement open-source, ce qui signifie que son code source est disponible gratuitement. Tout le monde peut le voir, le modifier et le distribuer. Des développeurs du monde entier peuvent contribuer à son amélioration. Cela pose les bases de la collaboration, qui est un aspect important des logiciels open-source.
Cette approche collaborative a conduit à l'adoption généralisée de Linux sur les serveurs, les ordinateurs de bureau, les systèmes embarqués et les appareils mobiles.
L'aspect le plus intéressant du caractère open-source de Linux est que n'importe qui peut adapter le système d'exploitation à ses besoins spécifiques sans être limité par des contraintes propriétaires.
Chrome OS, utilisé par les Chromebooks, est basé sur Linux. Android, qui équipe de nombreux smartphones dans le monde, est également basé sur Linux.
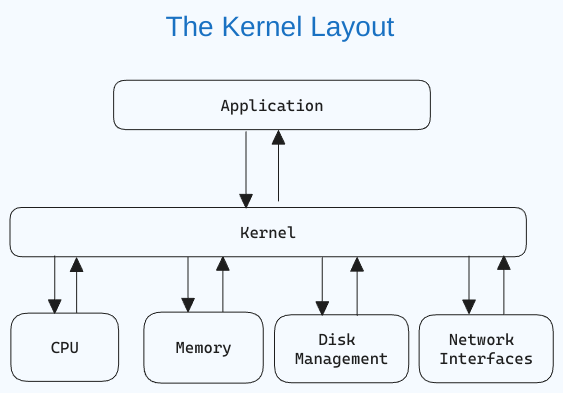
Qu'est-ce qu'un noyau Linux (Kernel) ?
Le noyau est le composant central d'un système d'exploitation qui gère l'ordinateur et ses opérations matérielles. Il gère les opérations de mémoire et le temps CPU.
Le noyau agit comme un pont entre les applications et le traitement des données au niveau matériel en utilisant la communication inter-processus et les appels système.
Le noyau est chargé en mémoire en premier lors du démarrage d'un système d'exploitation et y reste jusqu'à l'arrêt du système. Il est responsable de tâches telles que la gestion des disques, la gestion des tâches et la gestion de la mémoire.
Si vous êtes curieux de voir à quoi ressemble le noyau Linux, voici le lien GitHub.
Qu'est-ce qu'une distribution Linux ?
À ce stade, vous savez que vous pouvez réutiliser le code du noyau Linux, le modifier et créer un nouveau noyau. Vous pouvez ensuite combiner différents utilitaires et logiciels pour créer un système d'exploitation totalement nouveau.
Une distribution Linux (ou "distro") est une version du système d'exploitation Linux qui comprend le noyau Linux, des utilitaires système et d'autres logiciels. Étant open-source, une distribution Linux est un effort collaboratif impliquant plusieurs communautés de développement open-source indépendantes.
Que signifie le fait qu'une distribution soit dérivée ? Lorsqu'on dit qu'une distribution est "dérivée" d'une autre, cela signifie que la nouvelle distro est construite sur la base ou les fondations de la distro originale. Cette dérivation peut inclure l'utilisation du même système de gestion de paquets (nous y reviendrons), de la même version du noyau et parfois des mêmes outils de configuration.
Aujourd'hui, il existe des milliers de distributions Linux parmi lesquelles choisir, offrant des objectifs et des critères différents pour la sélection et le support des logiciels fournis.
Les distributions varient les unes des autres, mais elles présentent généralement plusieurs caractéristiques communes :
Une distribution se compose d'un noyau Linux.
Elle prend en charge les programmes de l'espace utilisateur (user space).
Une distribution peut être petite et à usage unique ou inclure des milliers de programmes open-source.
Un moyen d'installer et de mettre à jour la distribution et ses composants doit être fourni.
Si vous consultez la chronologie des distributions Linux, vous verrez deux distros majeures : Slackware et Debian. Plusieurs distributions en sont dérivées. Par exemple, Ubuntu et Kali sont dérivées de Debian.
Quels sont les avantages de la dérivation ? Il existe divers avantages. Les distributions dérivées peuvent tirer parti de la stabilité, de la sécurité et des vastes dépôts de logiciels de la distribution parente.
En s'appuyant sur une base existante, les développeurs peuvent concentrer leurs efforts entièrement sur les fonctionnalités spécialisées de la nouvelle distribution. Les utilisateurs des distributions dérivées bénéficient de la documentation, du support communautaire et des ressources déjà disponibles pour la distribution parente.
Certaines distributions Linux populaires sont :
Ubuntu : L'une des distributions Linux les plus utilisées et les plus populaires. Elle est conviviale et recommandée pour les débutants. En savoir plus sur Ubuntu ici.
Linux Mint : Basée sur Ubuntu, Linux Mint offre une expérience conviviale avec un accent sur le support multimédia. En savoir plus sur Linux Mint ici.
Arch Linux : Populaire parmi les utilisateurs expérimentés, Arch est une distribution légère et flexible destinée aux utilisateurs qui préfèrent une approche "faites-le vous-même" (DIY). En savoir plus sur Arch Linux ici.
Manjaro : Basée sur Arch Linux, Manjaro offre une expérience conviviale avec des logiciels préinstallés et des outils de gestion de système faciles. En savoir plus sur Manjaro ici.
Kali Linux : Kali Linux fournit une suite complète d'outils de sécurité et se concentre principalement sur la cybersécurité et le hacking. En savoir plus sur Kali Linux ici.
Comment installer et accéder à Linux
La meilleure façon d'apprendre est d'appliquer les concepts au fur et à mesure. Dans cette section, nous apprendrons comment installer Linux sur votre machine afin que vous puissiez suivre. Vous apprendrez également comment accéder à Linux sur une machine Windows.
Je vous recommande de suivre l'une des méthodes mentionnées dans cette section pour accéder à Linux afin de pouvoir pratiquer.
Installer Linux comme système d'exploitation principal
Installer Linux comme OS principal est le moyen le plus efficace d'utiliser Linux, car vous pouvez exploiter toute la puissance de votre machine.
Dans cette section, vous apprendrez comment installer Ubuntu, qui est l'une des distributions Linux les plus populaires. J'ai laissé de côté les autres distributions pour l'instant, car je veux garder les choses simples. Vous pourrez toujours explorer d'autres distributions une fois que vous serez à l'aise avec Ubuntu.
Étape 1 – Télécharger l'ISO d'Ubuntu : Allez sur le site officiel et téléchargez le fichier ISO. Assurez-vous de sélectionner une version stable étiquetée "LTS". LTS signifie Long Term Support (Support à Long Terme), ce qui signifie que vous bénéficierez de mises à jour de sécurité et de maintenance gratuites pendant une longue période (généralement 5 ans).
Étape 2 – Créer une clé USB amorçable : Il existe de nombreux logiciels capables de créer une clé USB bootable. Je recommande d'utiliser Rufus, car il est assez facile à utiliser. Vous pouvez le télécharger ici.
Étape 3 – Démarrer depuis la clé USB : Une fois votre clé USB prête, insérez-la et démarrez l'ordinateur dessus. Le menu de démarrage dépend de votre ordinateur. Vous pouvez rechercher sur Google le menu de démarrage (boot menu) correspondant à votre modèle d'ordinateur.
Étape 4 – Suivre les instructions. Une fois le processus de démarrage lancé, sélectionnez
try or install ubuntu.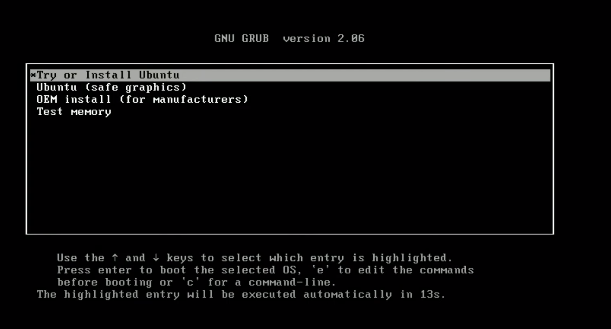
Le processus prendra un certain temps. Une fois que l'interface graphique apparaît, vous pouvez sélectionner la langue, la disposition du clavier et continuer. Saisissez votre identifiant et votre nom. Mémorisez ces informations d'identification car vous en aurez besoin pour vous connecter à votre système et accéder aux privilèges complets. Attendez la fin de l'installation.
Étape 5 – Redémarrer : Cliquez sur "Restart now" (Redémarrer maintenant) et retirez la clé USB.
Étape 6 – Connexion : Connectez-vous avec les identifiants saisis précédemment.
Et voilà ! Vous pouvez maintenant installer des applications et personnaliser votre bureau.
Pour une installation avancée, vous pouvez explorer les sujets suivants :
Partitionnement de disque.
Configuration de la mémoire swap pour activer l'hibernation.
Accéder au terminal
Une partie importante de ce manuel consiste à apprendre à utiliser le terminal, où vous exécuterez toutes les commandes. Vous pouvez rechercher le terminal en appuyant sur la touche "Windows" et en tapant "terminal". Vous pouvez épingler le Terminal dans le dock où se trouvent les autres applications pour un accès facile.
💡 Le raccourci pour ouvrir le terminal est
ctrl+alt+t
Vous pouvez également ouvrir le terminal depuis l'intérieur d'un dossier. Faites un clic droit là où vous vous trouvez et cliquez sur "Ouvrir dans un terminal". Cela ouvrira le terminal dans le même chemin.
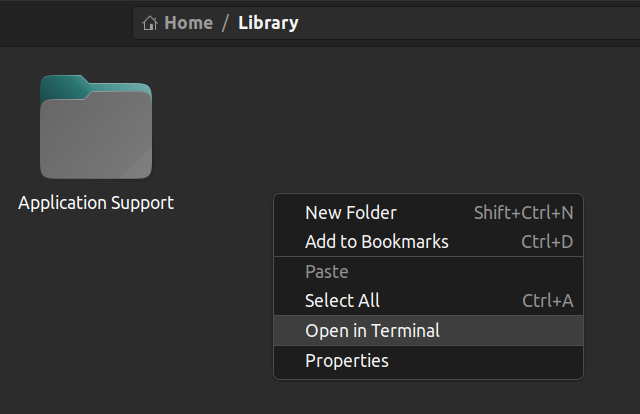
Comment utiliser Linux sur une machine Windows
Parfois, vous pourriez avoir besoin d'exécuter Linux et Windows côte à côte. Heureusement, il existe des moyens de profiter du meilleur des deux mondes sans avoir besoin d'ordinateurs différents pour chaque système d'exploitation.
Dans cette section, vous explorerez quelques façons d'utiliser Linux sur une machine Windows. Certaines sont basées sur le navigateur ou sur le cloud et ne nécessitent aucune installation d'OS avant utilisation.
Option 1 : Le "Dual-boot" Linux + Windows Avec le dual-boot, vous pouvez installer Linux à côté de Windows sur votre ordinateur, ce qui vous permet de choisir quel système d'exploitation utiliser au démarrage.
Cela nécessite de partitionner votre disque dur et d'installer Linux sur une partition séparée. Avec cette approche, vous ne pouvez utiliser qu'un seul système d'exploitation à la fois.
Option 2 : Utiliser le Windows Subsystem for Linux (WSL) Le Windows Subsystem for Linux fournit une couche de compatibilité qui vous permet d'exécuter des exécutables binaires Linux nativement sur Windows.
L'utilisation de WSL présente certains avantages. La configuration de WSL est simple et rapide. Il est léger par rapport aux machines virtuelles (VM) où vous devez allouer des ressources depuis la machine hôte. Vous n'avez pas besoin d'installer d'ISO ou d'image disque virtuelle pour les machines Linux, qui ont tendance à être des fichiers lourds. Vous pouvez utiliser Windows et Linux côte à côte.
Comment installer WSL2
Tout d'abord, activez l'option "Windows Subsystem for Linux" dans les paramètres.
Allez dans Démarrer. Recherchez "Activer ou désactiver des fonctionnalités Windows".
Cochez l'option "Sous-système Windows pour Linux" si ce n'est pas déjà fait.
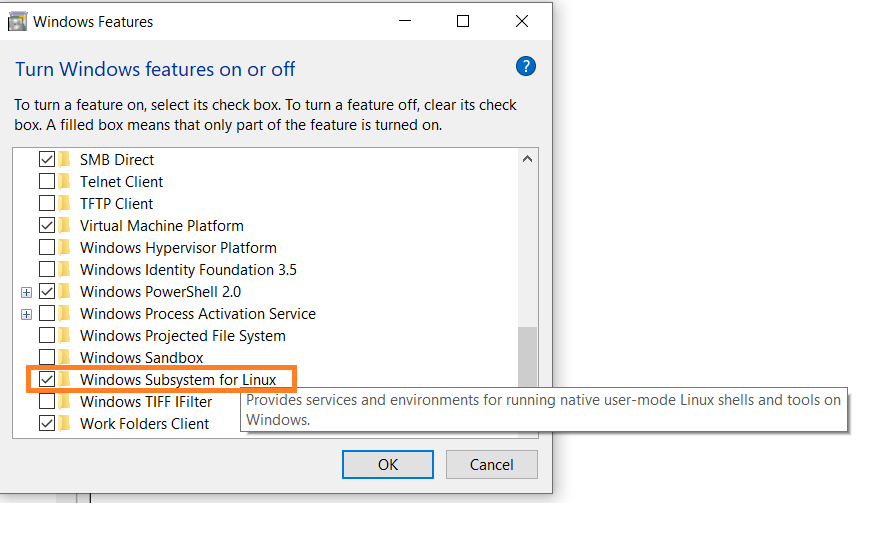
Ensuite, ouvrez votre invite de commande et saisissez les commandes d'installation.
Ouvrez l'Invite de commandes en tant qu'administrateur :
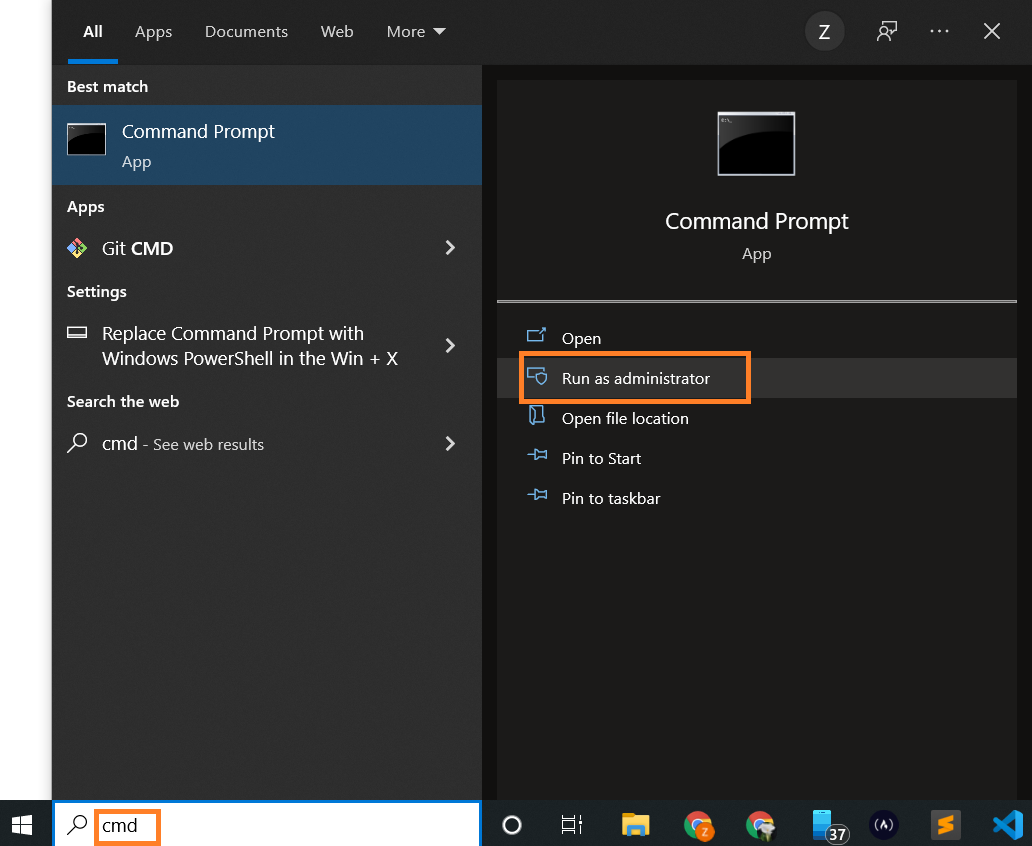
Exécutez la commande ci-dessous :
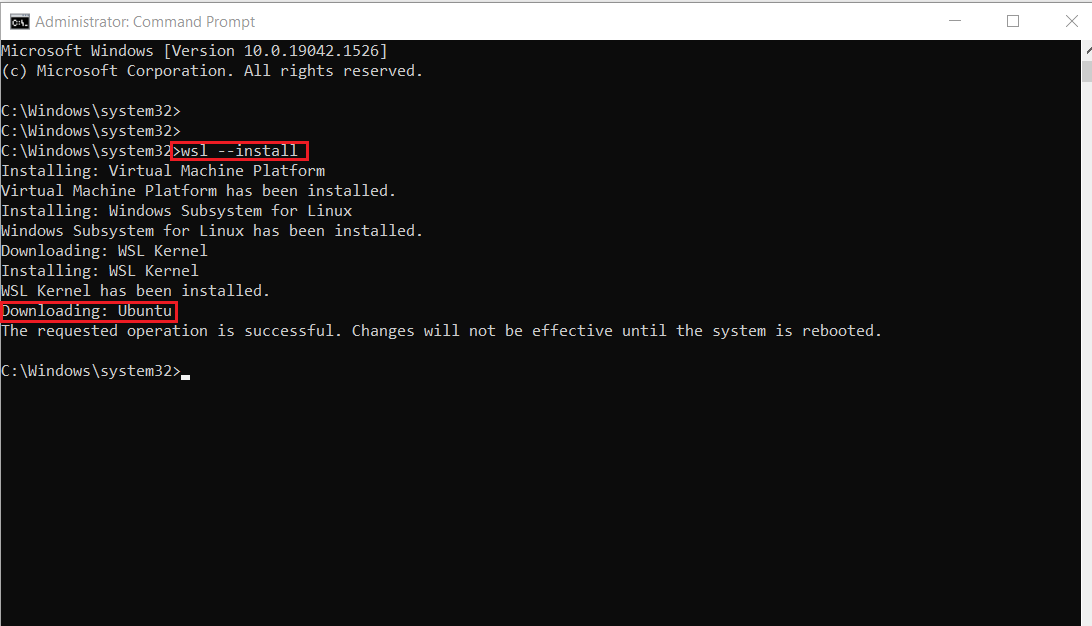
wsl --install
Voici le résultat :
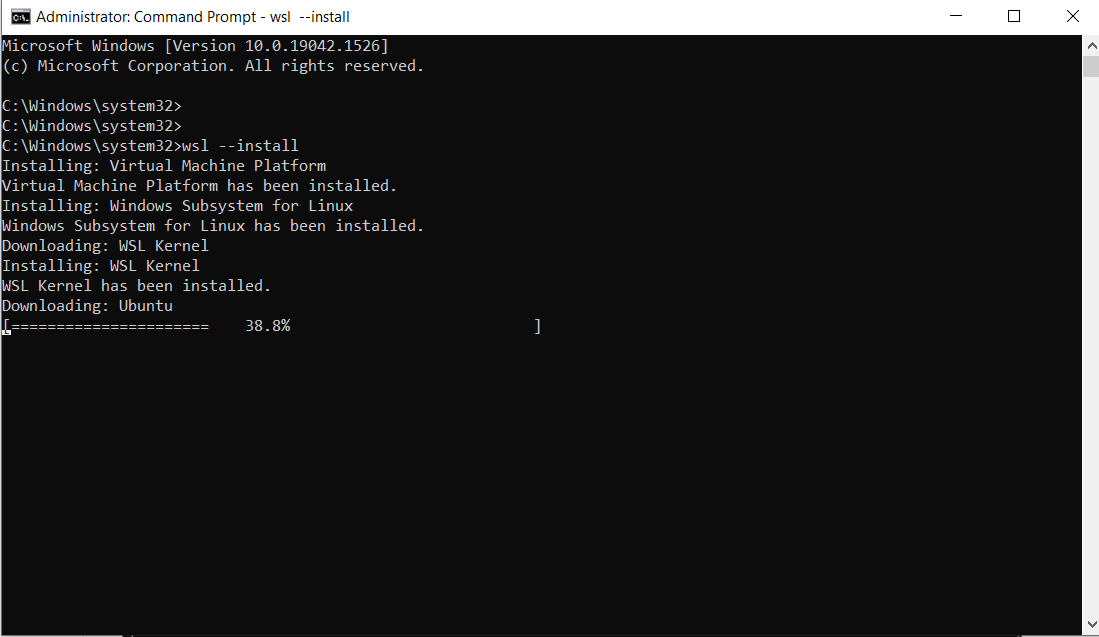
Note : Par défaut, Ubuntu sera installé.
- Une fois l'installation terminée, vous devrez redémarrer votre machine Windows.
Après le redémarrage, vous pourriez voir une fenêtre comme celle-ci :
Une fois l'installation d'Ubuntu terminée, vous serez invité à saisir votre nom d'utilisateur et votre mot de passe.
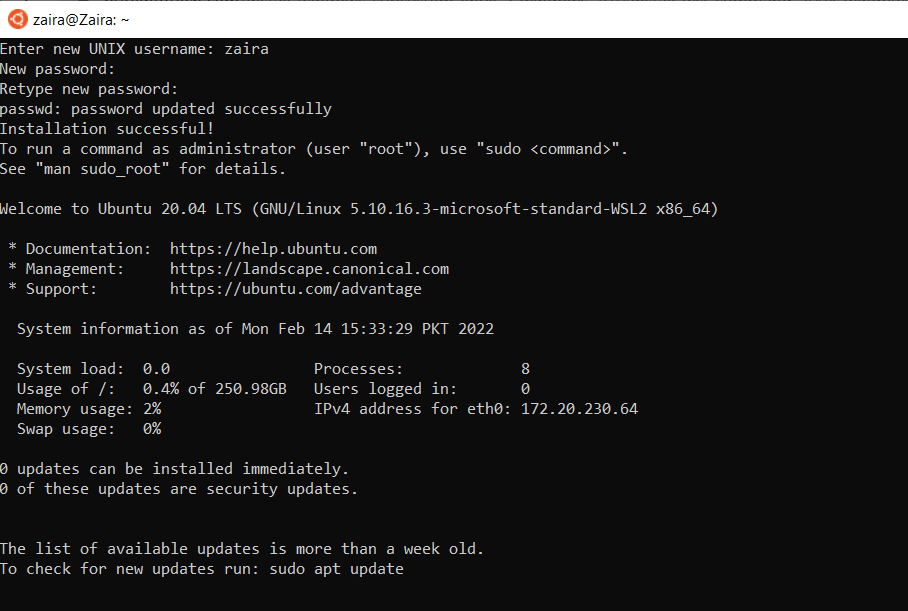
Et voilà ! Vous êtes prêt à utiliser Ubuntu.
Lancez Ubuntu en le recherchant dans le menu Démarrer.
Et voici votre instance Ubuntu lancée.
Option 3 : Utiliser une Machine Virtuelle (VM)
Une machine virtuelle (VM) est une émulation logicielle d'un système informatique physique. Elle vous permet d'exécuter plusieurs systèmes d'exploitation et applications sur une seule machine physique simultanément.
Vous pouvez utiliser un logiciel de virtualisation tel qu'Oracle VirtualBox ou VMware pour créer une machine virtuelle exécutant Linux au sein de votre environnement Windows. Cela vous permet d'exécuter Linux en tant que système d'exploitation invité à côté de Windows.
Les logiciels de VM offrent des options pour allouer et gérer les ressources matérielles pour chaque VM, y compris les cœurs de CPU, la mémoire, l'espace disque et la bande passante réseau. Vous pouvez ajuster ces allocations en fonction des besoins des systèmes d'exploitation invités et des applications.
Voici quelques-unes des options courantes disponibles pour la virtualisation :
Option 4 : Utiliser une solution basée sur le navigateur
Les solutions basées sur le navigateur sont particulièrement utiles pour des tests rapides, l'apprentissage ou l'accès à des environnements Linux depuis des appareils sur lesquels Linux n'est pas installé.
Vous pouvez utiliser soit des éditeurs de code en ligne, soit des terminaux web pour accéder à Linux. Notez que vous n'avez généralement pas les privilèges d'administration complets dans ces cas-là.
Éditeurs de code en ligne
Les éditeurs de code en ligne proposent des éditeurs avec des terminaux Linux intégrés. Bien que leur but principal soit le codage, vous pouvez également utiliser le terminal Linux pour exécuter des commandes et effectuer des tâches.
Replit est un exemple d'éditeur de code en ligne, où vous pouvez écrire votre code et accéder au shell Linux en même temps.
Terminaux Linux basés sur le web :
Les terminaux Linux en ligne vous permettent d'accéder à une interface de ligne de commande Linux directement depuis votre navigateur. Ces terminaux fournissent une interface web vers un shell Linux, vous permettant d'exécuter des commandes et de travailler avec des utilitaires Linux.
Un tel exemple est JSLinux. La capture d'écran ci-dessous montre un environnement Linux prêt à l'emploi :
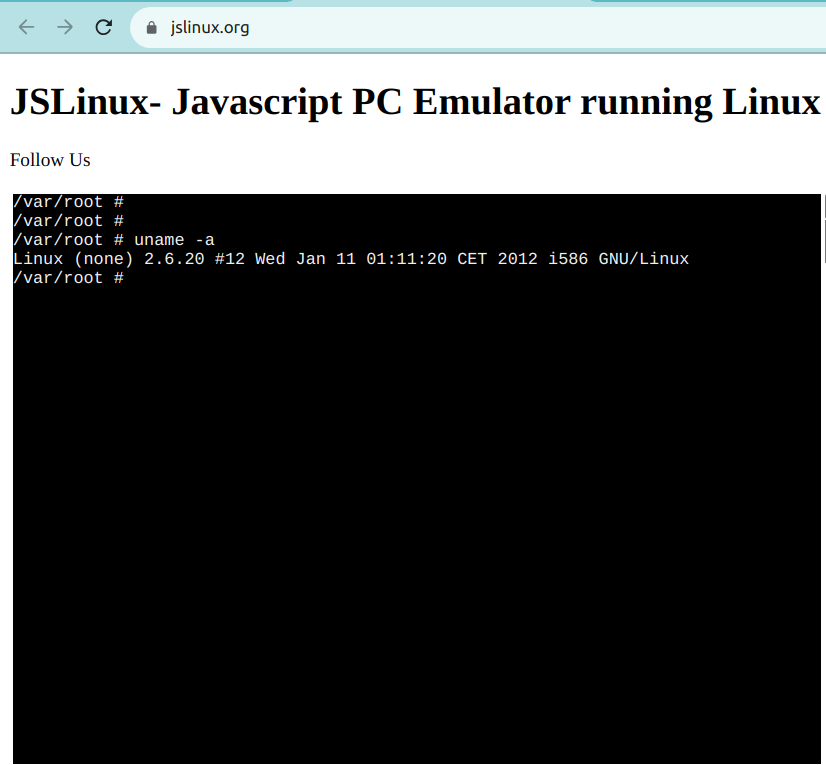
Option 5 : Utiliser une solution basée sur le Cloud
Au lieu d'exécuter Linux directement sur votre machine Windows, vous pouvez envisager d'utiliser des environnements Linux basés sur le cloud ou des serveurs privés virtuels (VPS) pour accéder à Linux et y travailler à distance.
Des services comme Amazon EC2, Microsoft Azure ou DigitalOcean fournissent des instances Linux auxquelles vous pouvez vous connecter depuis votre ordinateur Windows. Notez que certains de ces services offrent des niveaux gratuits (free tiers), mais ils ne sont généralement pas gratuits sur le long terme.
Partie 2 : Introduction au shell Bash et aux commandes système
2.1. Premiers pas avec le shell Bash
Introduction au shell bash
La ligne de commande Linux est fournie par un programme appelé le shell. Au fil des ans, le programme shell a évolué pour proposer diverses options.
Différents utilisateurs peuvent être configurés pour utiliser différents shells. Mais la plupart des utilisateurs préfèrent s'en tenir au shell par défaut actuel. Le shell par défaut pour de nombreuses distros Linux est le GNU Bourne-Again Shell (bash). Bash succède au Bourne shell (sh).
Pour connaître votre shell actuel, ouvrez votre terminal et saisissez la commande suivante :
echo $SHELL
Décomposition de la commande :
La commande
echoest utilisée pour afficher du texte sur le terminal.$SHELLest une variable spéciale qui contient le nom du shell actuel.
Dans ma configuration, le résultat est /bin/bash. Cela signifie que j'utilise le shell bash.
# sortie
echo $SHELL
/bin/bash
Bash est très puissant car il peut simplifier certaines opérations difficiles à accomplir efficacement avec une interface graphique (GUI). N'oubliez pas que la plupart des serveurs n'ont pas de GUI, et il est préférable d'apprendre à utiliser la puissance d'une interface en ligne de commande (CLI).
Terminal vs Shell
Les termes "terminal" et "shell" sont souvent utilisés de manière interchangeable, mais ils désignent des parties différentes de l'interface en ligne de commande.
Le terminal est l'interface que vous utilisez pour interagir avec le shell. Le shell est l'interprète de commandes qui traite et exécute vos commandes. Vous en apprendrez davantage sur les shells dans la Partie 6 de ce manuel.
Qu'est-ce qu'une invite (prompt) ?
Lorsqu'un shell est utilisé de manière interactive, il affiche un $ lorsqu'il attend une commande de l'utilisateur. C'est ce qu'on appelle l'invite de commande (shell prompt).
[username@host ~]$
Si le shell s'exécute en tant que root (vous en apprendrez plus sur l'utilisateur root plus tard), l'invite change en #.
[root@host ~]#
2.2. Structure des commandes
Une commande est un programme qui effectue une opération spécifique. Une fois que vous avez accès au shell, vous pouvez saisir n'importe quelle commande après le signe $ et voir le résultat sur le terminal.
Généralement, les commandes Linux suivent cette syntaxe :
command [options] [arguments]
Voici la décomposition de la syntaxe ci-dessus :
command: C'est le nom de la commande que vous voulez exécuter.ls(lister),cp(copier) etrm(supprimer) sont des commandes Linux courantes.[options]: Les options, ou drapeaux (flags), souvent précédés d'un trait d'union (-) ou d'un double trait d'union (--), modifient le comportement de la commande. Elles peuvent changer la façon dont la commande fonctionne. Par exemple,ls -autilise l'option-apour afficher les fichiers cachés dans le répertoire courant.[arguments]: Les arguments sont les entrées pour les commandes qui en nécessitent. Il peut s'agir de noms de fichiers, de noms d'utilisateurs ou d'autres données sur lesquelles la commande agira. Par exemple, dans la commandecat access.log,catest la commande etaccess.logest l'entrée. En conséquence, la commandecataffiche le contenu du fichieraccess.log.
Les options et les arguments ne sont pas requis pour toutes les commandes. Certaines commandes peuvent être exécutées sans aucune option ni argument, tandis que d'autres peuvent nécessiter l'un ou les deux pour fonctionner correctement. Vous pouvez toujours vous référer au manuel de la commande pour vérifier les options et arguments qu'elle prend en charge.
💡Astuce : Vous pouvez consulter le manuel d'une commande en utilisant la commande man.
Vous pouvez accéder à la page de manuel pour ls avec man ls, et elle ressemblera à ceci :
Les pages de manuel sont un excellent moyen rapide d'accéder à la documentation. Je recommande vivement de parcourir les pages man pour les commandes que vous utilisez le plus.
2.3. Commandes Bash et raccourcis clavier
Lorsque vous êtes dans le terminal, vous pouvez accélérer vos tâches en utilisant des raccourcis.
Voici quelques-uns des raccourcis de terminal les plus courants :
| Opération | Raccourci |
| Rechercher la commande précédente | Flèche Haut |
| Sauter au début du mot précédent | Ctrl+Flèche Gauche |
| Effacer les caractères du curseur jusqu'à la fin de la ligne de commande | Ctrl+K |
| Compléter les commandes, noms de fichiers et options | Touche Tab |
| Sauter au début de la ligne de commande | Ctrl+A |
| Afficher la liste des commandes précédentes | history |
2.4. S'identifier : la commande whoami
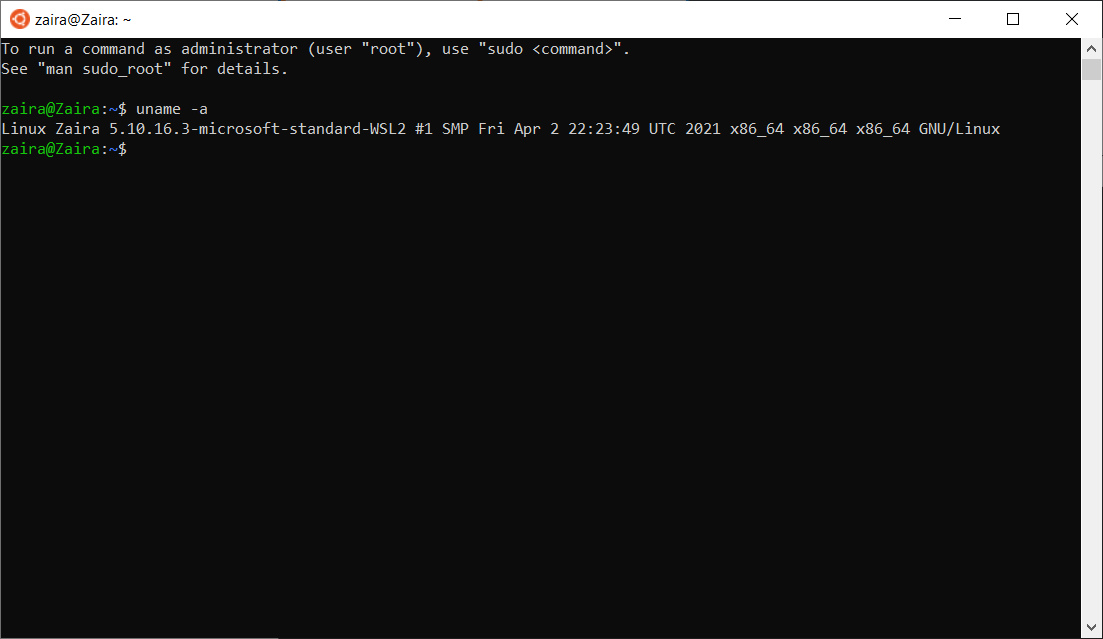
Vous pouvez obtenir le nom d'utilisateur avec lequel vous êtes connecté en utilisant la commande whoami. Cette commande est utile lorsque vous basculez entre différents utilisateurs et que vous voulez confirmer l'utilisateur actuel.
Juste après le signe $, tapez whoami et appuyez sur Entrée.
whoami
Voici le résultat que j'ai obtenu :
zaira@zaira-ThinkPad:~$ whoami
zaira
Partie 3 : Comprendre votre système Linux
3.1. Découvrir votre OS et ses spécifications
Afficher les informations système avec la commande uname
Vous pouvez obtenir des informations système détaillées grâce à la commande uname.
Lorsque vous fournissez l'option -a, elle affiche toutes les informations système.
uname -a
# sortie
Linux zaira 6.5.0-21-generic #21~22.04.1-Ubuntu SMP PREEMPT_DYNAMIC Fri Feb 9 13:32:52 UTC 2 x86_64 x86_64 x86_64 GNU/Linux
Dans la sortie ci-dessus,
Linux: Indique le système d'exploitation.zaira: Représente le nom d'hôte (hostname) de la machine.6.5.0-21-generic #21~22.04.1-Ubuntu SMP PREEMPT_DYNAMIC Fri Feb 9 13:32:52 UTC 2: Fournit des informations sur la version du noyau, la date de compilation et quelques détails supplémentaires.x86_64 x86_64 x86_64: Indique l'architecture du système.GNU/Linux: Représente le type de système d'exploitation.
Trouver les détails de l'architecture CPU avec la commande lscpu
La commande lscpu sous Linux est utilisée pour afficher des informations sur l'architecture du processeur (CPU). Lorsque vous exécutez lscpu dans le terminal, elle fournit des détails tels que :
L'architecture du CPU (par exemple, x86_64)
Le(s) mode(s) de fonctionnement du CPU (par exemple, 32 bits, 64 bits)
L'ordre des octets (Byte Order, par exemple, Little Endian)
Le nombre de CPU, et ainsi de suite.
Essayons :
lscpu
# sortie
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 48 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 12
On-line CPU(s) list: 0-11
Vendor ID: AuthenticAMD
Model name: AMD Ryzen 5 5500U with Radeon Graphics
Thread(s) per core: 2
Core(s) per socket: 6
Socket(s): 1
Stepping: 1
CPU max MHz: 4056.0000
CPU min MHz: 400.0000
C'est beaucoup d'informations, mais c'est très utile ! N'oubliez pas que vous pouvez toujours filtrer les informations pertinentes en utilisant des drapeaux spécifiques. Consultez le manuel de la commande avec man lscpu.
Partie 4 : Gérer les fichiers depuis la ligne de commande
4.1. La hiérarchie du système de fichiers Linux
Tous les fichiers sous Linux sont stockés dans un système de fichiers. Il suit une structure d'arbre inversé car la racine se trouve à la partie la plus haute.
Le / est le répertoire racine (root) et le point de départ du système de fichiers. Le répertoire racine contient tous les autres répertoires et fichiers du système. Le caractère / sert également de séparateur de répertoire entre les noms de chemins. Par exemple, /home/alice forme un chemin complet.
L'image ci-dessous montre la hiérarchie complète du système de fichiers. Chaque répertoire a un but spécifique.
Notez que cette liste n'est pas exhaustive et que différentes distributions peuvent avoir des configurations différentes.
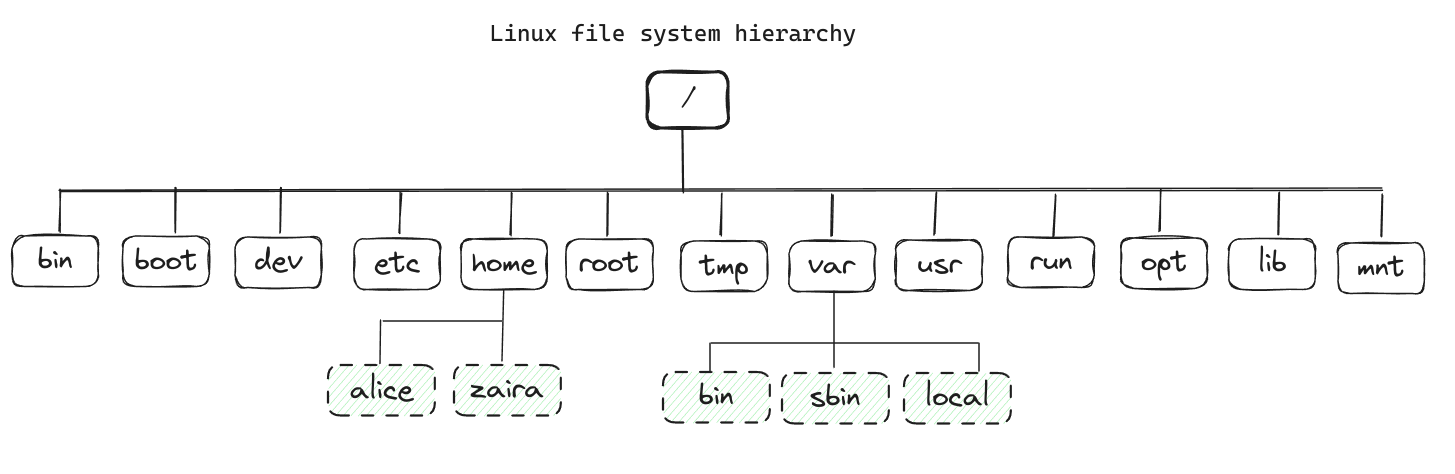
Voici un tableau montrant le but de chaque répertoire :
| Emplacement | But |
| /bin | Binaires des commandes essentielles |
| /boot | Fichiers statiques du chargeur d'amorçage (boot loader), nécessaires pour démarrer le système. |
| /etc | Configuration système spécifique à l'hôte |
| /home | Répertoires personnels des utilisateurs |
| /root | Répertoire personnel de l'administrateur (root) |
| /lib | Bibliothèques partagées essentielles et modules du noyau |
| /mnt | Point de montage pour monter un système de fichiers temporairement |
| /opt | Paquets logiciels d'applications additionnelles |
| /usr | Logiciels installés et bibliothèques partagées |
| /var | Données variables qui persistent entre les démarrages |
| /tmp | Fichiers temporaires accessibles à tous les utilisateurs |
💡 Astuce : Vous pouvez en apprendre davantage sur le système de fichiers en utilisant la commande man hier.
Vous pouvez vérifier votre système de fichiers en utilisant la commande tree -d -L 1. Vous pouvez modifier le drapeau -L pour changer la profondeur de l'arbre.
tree -d -L 1
# sortie
.
├── bin -> usr/bin
├── boot
├── cdrom
├── data
├── dev
├── etc
├── home
├── lib -> usr/lib
├── lib32 -> usr/lib32
├── lib64 -> usr/lib64
├── libx32 -> usr/libx32
├── lost+found
├── media
├── mnt
├── opt
├── proc
├── root
├── run
├── sbin -> usr/sbin
├── snap
├── srv
├── sys
├── tmp
├── usr
└── var
25 directories
Cette liste n'est pas exhaustive et les différents systèmes et distributions peuvent être configurés différemment.
4.2. Naviguer dans le système de fichiers Linux
Chemin absolu vs chemin relatif
Le chemin absolu est le chemin complet depuis le répertoire racine jusqu'au fichier ou répertoire. Il commence toujours par un /. Par exemple, /home/john/documents.
Le chemin relatif, en revanche, est le chemin depuis le répertoire actuel jusqu'au fichier ou répertoire de destination. Il ne commence pas par un /. Par exemple, documents/work/project.
Localiser votre répertoire actuel avec la commande pwd
Il est facile de se perdre dans le système de fichiers Linux, surtout si vous débutez avec la ligne de commande. Vous pouvez localiser votre répertoire actuel en utilisant la commande pwd (print working directory).
Voici un exemple :
pwd
# sortie
/home/zaira/scripts/python/free-mem.py
Changer de répertoire avec la commande cd
La commande pour changer de répertoire est cd et signifie "change directory". Vous pouvez utiliser la commande cd pour naviguer vers un répertoire différent.
Vous pouvez utiliser un chemin relatif ou un chemin absolu.
Par exemple, si vous voulez naviguer dans la structure de fichiers ci-dessous (en suivant les lignes rouges) :
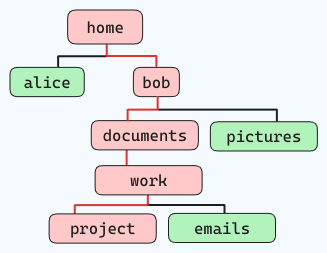
et que vous vous trouvez dans "home", la commande serait la suivante :
cd home/bob/documents/work/project
D'autres raccourcis cd couramment utilisés sont :
| Commande | Description |
cd .. | Revenir au répertoire parent |
cd ../.. | Revenir deux répertoires en arrière |
cd ou cd ~ | Aller au répertoire personnel (home) |
cd - | Retourner au chemin précédent |
4.3. Gérer les fichiers et les répertoires
Lorsque vous travaillez avec des fichiers et des répertoires, vous pouvez vouloir copier, déplacer, supprimer et créer de nouveaux fichiers et répertoires. Voici quelques commandes qui peuvent vous y aider.
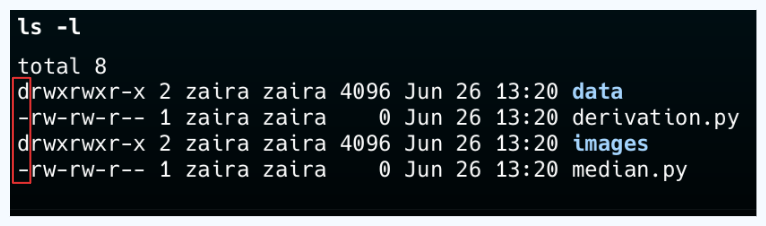
💡Astuce : Vous pouvez différencier un fichier d'un dossier en regardant la première lettre dans la sortie de ls -l. Un '-' représente un fichier et un 'd' représente un dossier.
Créer de nouveaux répertoires avec la commande mkdir
Vous pouvez créer un répertoire vide en utilisant la commande mkdir.
# crée un répertoire vide nommé "foo" dans le dossier actuel
mkdir foo
Vous pouvez également créer des répertoires de manière récursive en utilisant l'option -p.
mkdir -p tools/index/helper-scripts
# sortie de tree
.
└── tools
└── index
└── helper-scripts
3 directories, 0 files
Créer de nouveaux fichiers avec la commande touch
La commande touch crée un fichier vide. Vous pouvez l'utiliser ainsi :
# crée un fichier vide "file.txt" dans le dossier actuel
touch file.txt
Les noms de fichiers peuvent être enchaînés si vous souhaitez créer plusieurs fichiers en une seule commande.
# crée les fichiers vides "file1.txt", "file2.txt" et "file3.txt" dans le dossier actuel
touch file1.txt file2.txt file3.txt
Supprimer des fichiers et des répertoires avec les commandes rm et rmdir
Vous pouvez utiliser la commande rm pour supprimer à la fois des fichiers et des répertoires non vides.
| Commande | Description |
rm file.txt | Supprime le fichier file.txt |
rm -r directory | Supprime le répertoire directory et tout son contenu |
rm -f file.txt | Supprime le fichier file.txt sans demander de confirmation |
rmdir directory | Supprime un répertoire vide |
🛑 Notez que vous devez utiliser le drapeau -f avec prudence car aucune confirmation ne vous sera demandée avant la suppression. Soyez également prudent lorsque vous exécutez des commandes rm dans le dossier root car cela pourrait entraîner la suppression de fichiers système importants.
Copier des fichiers avec la commande cp
Pour copier des fichiers sous Linux, utilisez la commande cp.
- Syntaxe pour copier des fichiers :
cp source_file destination_of_file
Cette commande copie un fichier nommé file1.txt vers un nouvel emplacement /home/adam/logs.
cp file1.txt /home/adam/logs
La commande cp crée également une copie d'un fichier avec le nom fourni.
Cette commande copie un fichier nommé file1.txt vers un autre fichier nommé file2.txt dans le même dossier.
cp file1.txt file2.txt
Déplacer et renommer des fichiers et dossiers avec la commande mv
La commande mv est utilisée pour déplacer des fichiers et des dossiers d'un répertoire à un autre.
Syntaxe pour déplacer des fichiers : mv source_file destination_directory
Exemple : Déplacer un fichier nommé file1.txt vers un répertoire nommé backup :
mv file1.txt backup/
Pour déplacer un répertoire et son contenu :
mv dir1/ backup/
Le renommage des fichiers et dossiers sous Linux se fait également avec la commande mv.
Syntaxe pour renommer des fichiers : mv old_name new_name
Exemple : Renommer un fichier de file1.txt à file2.txt :
mv file1.txt file2.txt
Renommer un répertoire de dir1 à dir2 :
mv dir1 dir2
4.4. Localiser des fichiers et des dossiers avec la commande find
La commande find vous permet de rechercher efficacement des fichiers, des dossiers, ainsi que des périphériques de type caractère ou bloc.
Voici la syntaxe de base de la commande find :
find /path/ -type f -name file-to-search
Où,
/pathest le chemin où le fichier est censé se trouver. C'est le point de départ de la recherche. Le chemin peut également être/ou.qui représentent respectivement la racine et le répertoire courant.-typereprésente les descripteurs de fichiers. Ils peuvent être l'un des suivants :f– Fichier régulier tel que des fichiers texte, des images et des fichiers cachés.d– Répertoire. Ce sont les dossiers pris en compte.l– Lien symbolique. Les liens symboliques pointent vers des fichiers et sont similaires à des raccourcis.c– Périphériques de caractères. Les fichiers utilisés pour accéder aux périphériques de caractères. Les pilotes communiquent avec eux en envoyant et recevant des caractères uniques (octets). Exemples : claviers, cartes son, souris.b– Périphériques de blocs. Les fichiers utilisés pour accéder aux périphériques de blocs. Les pilotes communiquent avec eux en envoyant et recevant des blocs entiers de données. Exemples : clés USB, CD-ROM.-nameest le nom du type de fichier que vous souhaitez rechercher.
Comment rechercher des fichiers par nom ou extension
Supposons que nous devions trouver des fichiers qui contiennent "style" dans leur nom. Nous utiliserons cette commande :
find . -type f -name "style*"
# sortie
./style.css
./styles.css
Maintenant, disons que nous voulons trouver des fichiers avec une extension particulière comme .html. Nous modifierons la commande ainsi :
find . -type f -name "*.html"
# sortie
./services.html
./blob.html
./index.html
Comment rechercher des fichiers cachés
Un point au début du nom de fichier représente des fichiers cachés. Ils sont normalement masqués mais peuvent être visualisés avec ls -a dans le répertoire courant.
Nous pouvons modifier la commande find comme indiqué ci-dessous pour rechercher des fichiers cachés :
find . -type f -name ".*"
Lister et trouver des fichiers cachés
ls -la
# contenu du dossier
total 5
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:17 .
drwxr-x--- 61 zaira zaira 4096 Mar 26 14:12 ..
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:17 .bash_history
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:17 .bash_logout
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:17 .bashrc
find . -type f -name ".*"
# sortie de find
./.bash_logout
./.bashrc
./.bash_history
Ci-dessus, vous pouvez voir une liste de fichiers cachés dans mon répertoire personnel.
Comment rechercher des fichiers de log et des fichiers de configuration
Les fichiers de log ont généralement l'extension .log, et nous pouvons les trouver ainsi :
find . -type f -name "*.log"
De même, nous pouvons rechercher des fichiers de configuration ainsi :
find . -type f -name "*.conf"
Comment rechercher d'autres fichiers par type
Nous pouvons rechercher des fichiers de périphériques de caractères en fournissant c à -type :
find / -type c
De même, nous pouvons trouver des fichiers de périphériques de blocs en utilisant b :
find / -type b
Comment rechercher des répertoires
Dans l'exemple ci-dessous, nous trouvons les dossiers en utilisant le drapeau -type d.
ls -l
# liste du contenu du dossier
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:22 hosts
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:23 hosts.txt
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:22 images
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:23 style
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:22 webp
find . -type d
# sortie find répertoire
.
./webp
./images
./style
./hosts
Comment rechercher des fichiers par taille
Une utilisation incroyablement utile de la commande find consiste à lister les fichiers en fonction d'une taille particulière.
find / -size +250M
Ici, nous listons les fichiers dont la taille dépasse 250 Mo.
Les autres unités incluent :
G: Giga-octets.M: Méga-octets.K: Kilo-octets.c: octets.
Remplacez simplement par l'unité appropriée.
find <répertoire> -type f -size +N<Type Unité>
Comment rechercher des fichiers par date de modification
En utilisant le drapeau -mtime, vous pouvez filtrer les fichiers et dossiers en fonction de l'heure de modification.
find /path -name "*.txt" -mtime -10
Par exemple,
-mtime +10 signifie que vous recherchez un fichier modifié il y a plus de 10 jours.
-mtime -10 signifie moins de 10 jours.
-mtime 10 si vous omettez le + ou le -, cela signifie exactement 10 jours.
4.5. Commandes de base pour visualiser des fichiers
Concaténer et afficher des fichiers avec la commande cat
La commande cat sous Linux est utilisée pour afficher le contenu d'un fichier. Elle peut également être utilisée pour concaténer des fichiers et en créer de nouveaux.
Voici la syntaxe de base de la commande cat :
cat [options] [file]
La façon la plus simple d'utiliser cat est sans aucune option ni argument. Cela affichera le contenu du fichier sur le terminal.
Par exemple, si vous voulez voir le contenu d'un fichier nommé file.txt, vous pouvez utiliser la commande suivante :
cat file.txt
Cela affichera tout le contenu du fichier sur le terminal d'un seul coup.
Visualiser des fichiers texte de manière interactive avec less et more
Alors que cat affiche l'intégralité du fichier d'un coup, less et more vous permettent de visualiser le contenu d'un fichier de manière interactive. C'est utile lorsque vous voulez faire défiler un gros fichier ou rechercher un contenu spécifique.
La syntaxe de la commande less est :
less [options] [file]
La commande more est similaire à less mais possède moins de fonctionnalités. Elle est utilisée pour afficher le contenu d'un fichier un écran à la fois.
La syntaxe de la commande more est :
more [options] [file]
Pour les deux commandes, vous pouvez utiliser la barre d'espace pour descendre d'une page, la touche Entrée pour descendre d'une ligne, et la touche q pour quitter le visualiseur.
Pour revenir en arrière, vous pouvez utiliser la touche b, et pour avancer, la touche f.
Afficher la dernière partie des fichiers avec tail
Parfois, vous n'avez besoin de voir que les dernières lignes d'un fichier au lieu du fichier entier. La commande tail sous Linux est utilisée pour afficher la dernière partie d'un fichier.
Par exemple, tail file.txt affichera par défaut les 10 dernières lignes du fichier file.txt.
Si vous souhaitez afficher un nombre différent de lignes, vous pouvez utiliser l'option -n suivie du nombre de lignes souhaité.
# Affiche les 50 dernières lignes du fichier file.txt
tail -n 50 file.txt
💡Astuce : Un autre usage de tail est son option de suivi (-f). Cette option vous permet de voir le contenu d'un fichier au fur et à mesure qu'il est écrit. C'est un utilitaire utile pour visualiser et surveiller les fichiers de log en temps réel.
Afficher le début des fichiers avec head
Tout comme tail affiche la dernière partie d'un fichier, vous pouvez utiliser la commande head sous Linux pour afficher le début d'un fichier.
Par exemple, head file.txt affichera par défaut les 10 premières lignes du fichier file.txt.
Pour changer le nombre de lignes affichées, vous pouvez utiliser l'option -n suivie du nombre de lignes souhaité.
Compter les mots, les lignes et les caractères avec wc
Vous pouvez compter les mots, les lignes et les caractères dans un fichier en utilisant la commande wc (word count).
Par exemple, l'exécution de wc syslog.log m'a donné le résultat suivant :
1669 9623 64367 syslog.log
Dans la sortie ci-dessus,
1669représente le nombre de lignes dans le fichiersyslog.log.9623représente le nombre de mots dans le fichiersyslog.log.64367représente le nombre de caractères dans le fichiersyslog.log.
Ainsi, la commande wc syslog.log a compté 1669 lignes, 9623 mots et 64367 caractères dans le fichier syslog.log.
Comparer des fichiers ligne par ligne avec diff
Comparer et trouver les différences entre deux fichiers est une tâche courante sous Linux. Vous pouvez comparer deux fichiers directement dans la ligne de commande en utilisant la commande diff.
La syntaxe de base de la commande diff est :
diff [options] file1 file2
Voici deux fichiers, hello.py et also-hello.py, que nous allons comparer à l'aide de la commande diff :
# contenu de hello.py
def greet(name):
return f"Hello, {name}!"
user = input("Enter your name: ")
print(greet(user))
# contenu de also-hello.py
more also-hello.py
def greet(name):
return fHello, {name}!
user = input(Enter your name: )
print(greet(user))
print("Nice to meet you")
- Vérifier si les fichiers sont identiques ou non
diff -q hello.py also-hello.py
# Sortie
Files hello.py and also-hello.py differ
- Voir comment les fichiers diffèrent. Pour cela, vous pouvez utiliser le drapeau
-upour voir une sortie unifiée :
diff -u hello.py also-hello.py
--- hello.py 2024-05-24 18:31:29.891690478 +0500
+++ also-hello.py 2024-05-24 18:32:17.207921795 +0500
@@ -3,4 +3,5 @@
user = input(Enter your name: )
print(greet(user))
+print("Nice to meet you")
Dans la sortie ci-dessus :
--- hello.py 2024-05-24 18:31:29.891690478 +0500indique le fichier comparé et son horodatage.+++ also-hello.py 2024-05-24 18:32:17.207921795 +0500indique l'autre fichier comparé et son horodatage.@@ -3,4 +3,5 @@montre les numéros de lignes où les changements se produisent. Dans ce cas, cela indique que les lignes 3 à 4 du fichier original ont changé pour devenir les lignes 3 à 5 dans le fichier modifié.user = input(Enter your name: )est une ligne du fichier original.print(greet(user))est une autre ligne du fichier original.+print("Nice to meet you")est la ligne supplémentaire dans le fichier modifié.
- Pour voir le diff dans un format côte à côte, vous pouvez utiliser le drapeau
-y:
diff -y hello.py also-hello.py
# Sortie
def greet(name): def greet(name):
return fHello, {name}! return fHello, {name}!
user = input(Enter your name: ) user = input(Enter your name: )
print(greet(user)) print(greet(user))
> print("Nice to meet you")
Dans la sortie :
Les lignes qui sont identiques dans les deux fichiers sont affichées côte à côte.
Les lignes qui sont différentes sont affichées avec un symbole
>indiquant que la ligne n'est présente que dans l'un des fichiers.
Partie 5 : L'essentiel de l'édition de texte sous Linux
Les compétences en édition de texte via la ligne de commande sont parmi les plus cruciales sous Linux. Dans cette section, vous apprendrez à utiliser deux éditeurs de texte populaires sous Linux : Vim et Nano.
Je vous suggère de maîtriser l'un des deux éditeurs de texte de votre choix et de vous y tenir. Cela vous fera gagner du temps et vous rendra plus productif. Vim et Nano sont des choix sûrs car ils sont présents sur la plupart des distributions Linux.
5.1. Maîtriser Vim : le guide complet
Introduction à Vim
Vim est un outil d'édition de texte populaire pour la ligne de commande. Vim présente plusieurs avantages : il est puissant, personnalisable et rapide. Voici quelques raisons pour lesquelles vous devriez envisager d'apprendre Vim :
La plupart des serveurs sont accessibles via une CLI, donc en administration système, vous n'avez pas forcément le luxe d'une GUI. Mais Vim est là pour vous – il sera toujours disponible.
Vim utilise une approche centrée sur le clavier, car il est conçu pour être utilisé sans souris, ce qui peut considérablement accélérer les tâches d'édition une fois que vous avez appris les raccourcis clavier. Cela le rend également plus rapide que les outils GUI.
Certains utilitaires Linux, par exemple l'édition de tâches cron, fonctionnent dans le même format d'édition que Vim.
Vim convient à tous – débutants comme utilisateurs avancés. Vim prend en charge les recherches de chaînes complexes, la mise en évidence des recherches et bien plus encore. Grâce aux plugins, Vim offre des capacités étendues aux développeurs et administrateurs système, notamment la complétion de code, la coloration syntaxique, la gestion de fichiers, le contrôle de version, et plus encore.
Vim a deux variantes : Vim (vim) et Vim tiny (vi). Vim tiny est une version plus petite de Vim à laquelle il manque certaines fonctionnalités.
Comment commencer à utiliser vim
Commencez à utiliser Vim avec cette commande :
vim your-file.txt
your-file.txt peut être soit un nouveau fichier, soit un fichier existant que vous souhaitez modifier.
Naviguer dans Vim : Maîtriser le mouvement et les modes de commande
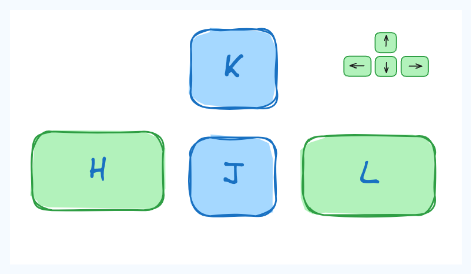
Aux débuts de la CLI, les claviers n'avaient pas de touches fléchées. Par conséquent, la navigation se faisait à l'aide de l'ensemble des touches disponibles, hjkl étant l'une d'entre elles.
Étant centré sur le clavier, l'utilisation des touches hjkl peut considérablement accélérer les tâches d'édition de texte.
Note : Bien que les touches fléchées fonctionnent parfaitement, vous pouvez toujours expérimenter avec les touches hjkl pour naviguer. Certaines personnes trouvent cette méthode de navigation plus efficace.
💡Astuce : Pour vous souvenir de la séquence hjkl, utilisez ceci : h (gauche), j (bas), k (haut), l (droite).
Les trois modes de Vim
Vous devez connaître les 3 modes de fonctionnement de Vim et savoir comment basculer entre eux. Les frappes de touches se comportent différemment dans chaque mode. Les trois modes sont les suivants :
Mode Commande (Command mode).
Mode Édition (Edit/Insert mode).
Mode Visuel (Visual mode).
Mode Commande. Lorsque vous lancez Vim, vous arrivez par défaut dans le mode commande. Ce mode vous permet d'accéder aux autres modes.
⚠ Pour passer à d'autres modes, vous devez d'abord être en mode commande.
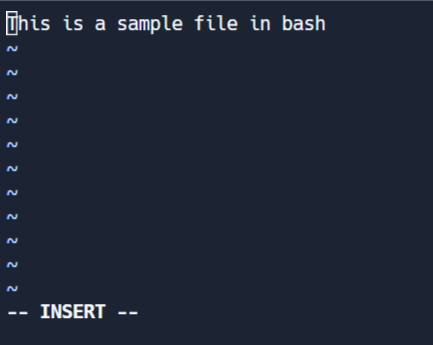
Mode Édition
Ce mode vous permet d'apporter des modifications au fichier. Pour entrer en mode édition, appuyez sur i (pour insert) tout en étant en mode commande. Notez l'indicateur '-- INSERT --' en bas de l'écran.
Mode Visuel
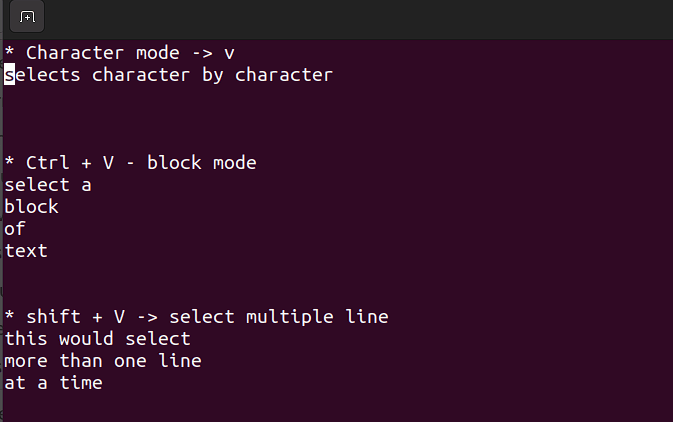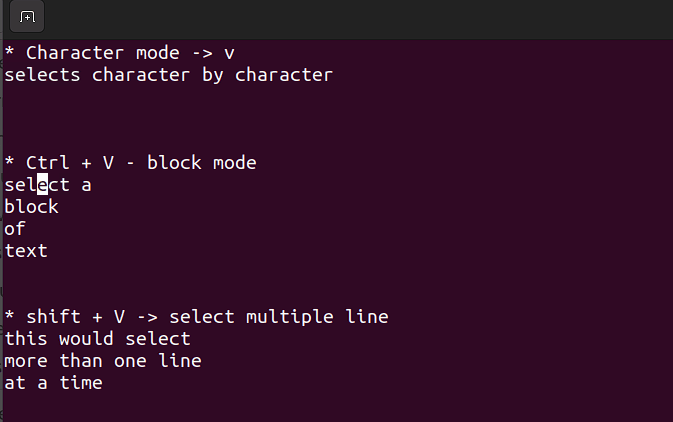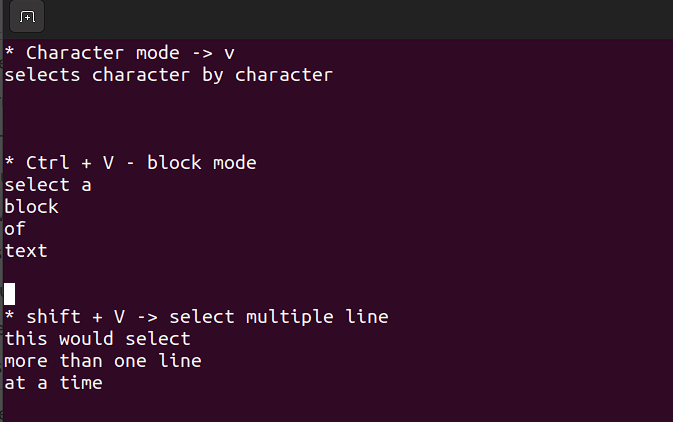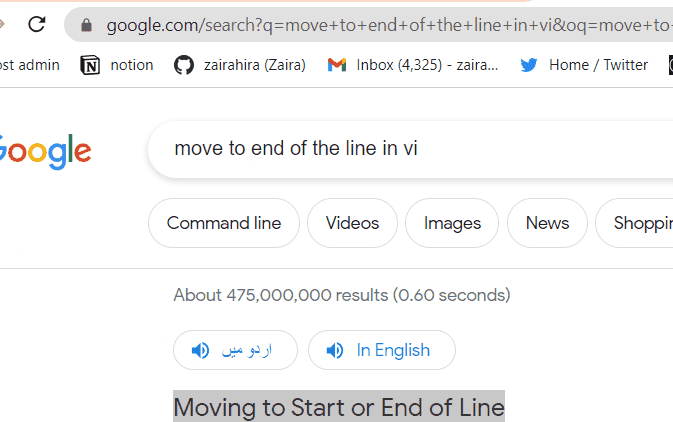
Ce mode vous permet de travailler sur un seul caractère, un bloc de texte ou des lignes de texte. Décomposons-le en étapes simples. N'oubliez pas d'utiliser les combinaisons ci-dessous en mode commande.
Shift + V→ Sélectionner plusieurs lignes.Ctrl + V→ Mode bloc.v→ Mode caractère.
Le mode visuel est pratique lorsque vous devez copier-coller ou modifier des lignes en masse.
Mode commande étendue.
Le mode commande étendue vous permet d'effectuer des opérations avancées comme la recherche, l'affichage des numéros de ligne et la mise en évidence du texte. Nous aborderons le mode étendu dans la section suivante.
Comment ne pas se perdre ? Si vous oubliez votre mode actuel, appuyez simplement deux fois sur Echap (ESC) et vous reviendrez en mode commande.
Éditer efficacement dans Vim : Copier/coller et rechercher
1. Comment copier et coller dans Vim
Le copier-coller est connu sous les termes 'yank' (arracher) et 'put' (poser) dans le jargon Linux. Pour copier-coller, suivez ces étapes :
Sélectionnez le texte en mode visuel.
Appuyez sur
'y'pour copier (yank).Déplacez votre curseur à la position requise et appuyez sur
'p'(put).
2. Comment rechercher du texte dans Vim
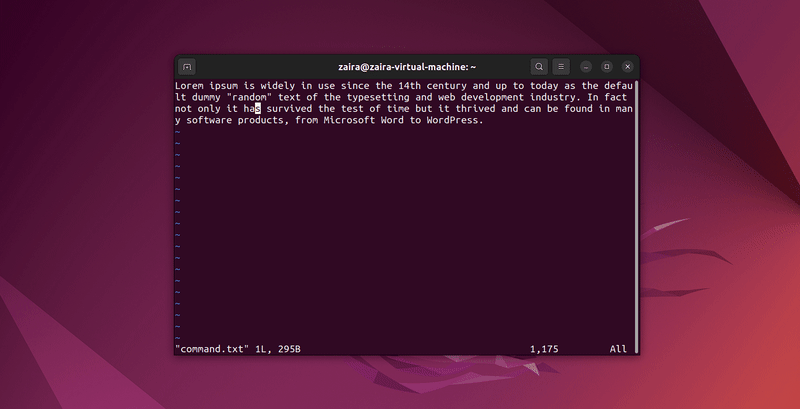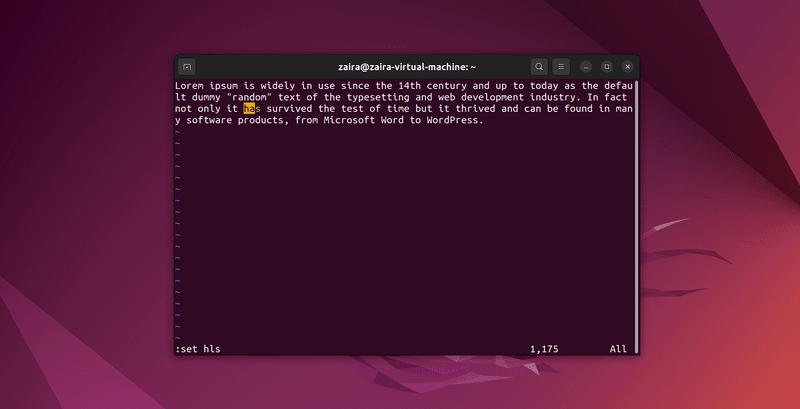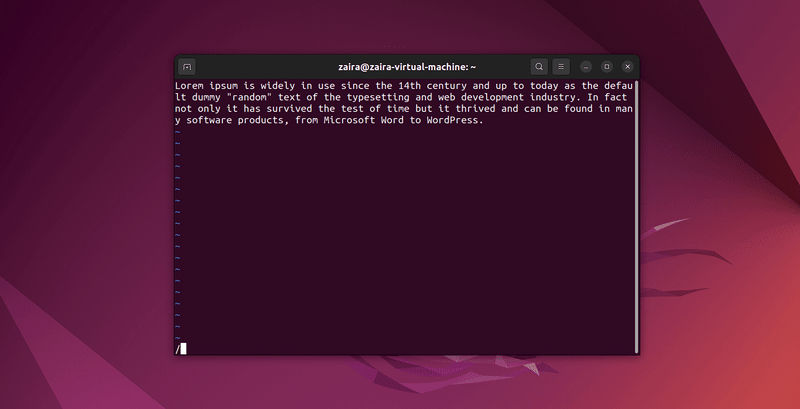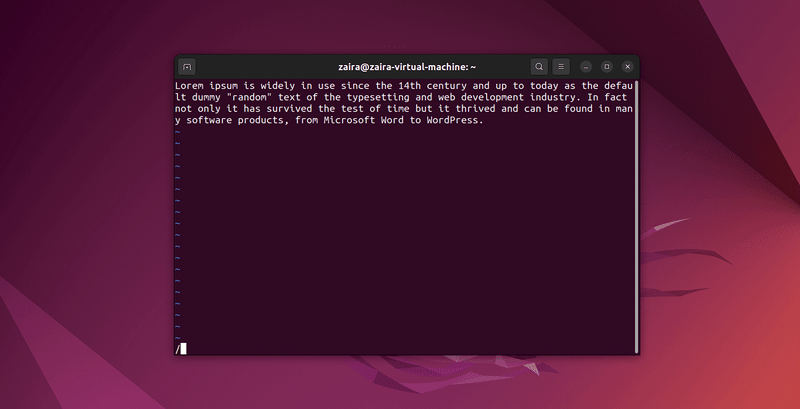
N'importe quelle série de caractères peut être recherchée dans Vim en utilisant le / en mode commande. Pour rechercher, utilisez /string-to-match.
En mode commande, tapez :set hls (highlight search) et appuyez sur Entrée. Recherchez avec /string-to-match. Cela mettra en évidence les résultats.
Recherchons quelques chaînes :
3. Comment quitter Vim
Tout d'abord, passez en mode commande (en appuyant deux fois sur Echap) puis utilisez ces drapeaux :
Quitter sans sauvegarder →
:q!Quitter et sauvegarder →
:wq!
Raccourcis dans Vim : Accélérer l'édition
Note : Tous ces raccourcis ne fonctionnent qu'en mode commande.
Navigation de base
h: Déplacer à gauchej: Déplacer vers le bask: Déplacer vers le hautl: Déplacer à droite0: Aller au début de la ligne$: Aller à la fin de la lignegg: Aller au début du fichierG: Aller à la fin du fichierCtrl+d: Descendre d'une demi-pageCtrl+u: Monter d'une demi-page
Édition
i: Entrer en mode insertion avant le curseurI: Entrer en mode insertion au début de la lignea: Entrer en mode insertion après le curseurA: Entrer en mode insertion à la fin de la ligneo: Ouvrir une nouvelle ligne sous la ligne actuelle et entrer en mode insertionO: Ouvrir une nouvelle ligne au-dessus de la ligne actuelle et entrer en mode insertionx: Supprimer le caractère sous le curseurdd: Supprimer la ligne actuelleyy: Copier (yank) la ligne actuellep: Coller sous le curseurP: Coller au-dessus du curseur
Recherche et Remplacement
/: Rechercher un motif vers l'avant?: Rechercher un motif vers l'arrièren: Répéter la dernière recherche dans la même directionN: Répéter la dernière recherche dans la direction opposée:%s/old/new/g: Remplacer toutes les occurrences deoldparnewdans le fichier
Sortie
:w: Sauvegarder le fichier sans quitter:q: Quitter Vim (échoue s'il y a des modifs non sauvegardées):wqou:x: Sauvegarder et quitter:q!: Quitter sans sauvegarder
Fenêtres multiples
:splitou:sp: Diviser la fenêtre horizontalement:vsplitou:vsp: Diviser la fenêtre verticalementCtrl+w suivi de h/j/k/l: Naviguer entre les fenêtres divisées
5.2. Maîtriser Nano
Premiers pas avec Nano : l'éditeur de texte convivial
Nano est un éditeur de texte convivial, facile à utiliser et parfait pour les débutants. Il est préinstallé sur la plupart des distributions Linux.
Pour créer un nouveau fichier avec Nano, utilisez la commande suivante :
nano
Pour commencer à éditer un fichier existant avec Nano, utilisez la commande suivante :
nano filename
Liste des raccourcis clavier dans Nano
Étudions les raccourcis clavier les plus importants dans Nano. Vous utiliserez ces combinaisons pour effectuer diverses opérations comme sauvegarder, quitter, copier, coller, etc.
Écrire dans un fichier et sauvegarder
Une fois que vous avez ouvert Nano, vous pouvez commencer à écrire du texte. Pour sauvegarder le fichier, appuyez sur Ctrl+O. Vous serez invité à saisir le nom du fichier. Appuyez sur Entrée pour confirmer.
Quitter Nano
Vous pouvez quitter Nano en appuyant sur Ctrl+X. Si vous avez des modifications non sauvegardées, Nano vous proposera de les enregistrer avant de quitter.
Copier et coller
Pour sélectionner une région, utilisez ALT+A. Un marqueur apparaîtra. Utilisez les flèches pour sélectionner le texte. Une fois sélectionné, quittez le marqueur avec ALT+^.
Pour copier le texte sélectionné, appuyez sur Alt+6. Pour coller le texte, appuyez sur Ctrl+U.
Couper et coller
Sélectionnez la région avec ALT+A. Une fois sélectionnée, coupez le texte avec Ctrl+K. Pour coller le texte coupé, appuyez sur Ctrl+U.
Navigation
Utilisez Alt + \ pour aller au début du fichier.
Utilisez Alt + / pour aller à la fin du fichier.
Afficher les numéros de ligne
Lorsque vous ouvrez un fichier avec nano -l filename, vous pouvez voir les numéros de ligne sur le côté gauche.
Recherche
Vous pouvez aller à un numéro de ligne spécifique avec Alt + G. Saisissez le numéro de ligne et appuyez sur Entrée.
Vous pouvez également lancer une recherche de chaîne avec Ctrl + W et appuyer sur Entrée. Si vous voulez chercher en arrière, vous pouvez appuyer sur Alt + W après avoir initié la recherche avec Ctrl + W.
Résumé des raccourcis dans Nano
Général
Ctrl+X: Quitter NanoCtrl+O: Sauvegarder le fichierCtrl+R: Lire un fichier dans le fichier actuelCtrl+G: Afficher l'aide
Édition
Ctrl+K: Couper la ligne actuelleCtrl+U: Coller le contenu coupéAlt+6: Copier la ligne actuelleCtrl+J: Justifier le paragraphe actuel
Navigation
Ctrl+A: Aller au début de la ligneCtrl+E: Aller à la fin de la ligneCtrl+C: Afficher la position actuelle du curseurCtrl+_(Ctrl+Shift+-) : Aller à une ligne spécifiqueCtrl+Y: Monter d'une pageCtrl+V: Descendre d'une page
Recherche et Remplacement
Ctrl+W: Rechercher une chaîneAlt+W: Répéter la dernière recherche en sens inverseCtrl+\: Rechercher et remplacer
Partie 6 : Scripting Bash
6.1. Définition du scripting Bash
Un script bash est un fichier contenant une séquence de commandes qui sont exécutées ligne par ligne par le programme bash. Il vous permet d'effectuer une série d'actions, telles que naviguer vers un répertoire spécifique, créer un dossier et lancer un processus via la ligne de commande.
En enregistrant des commandes dans un script, vous pouvez répéter la même séquence d'étapes plusieurs fois et les exécuter simplement en lançant le script.
6.2. Avantages du scripting Bash
Le scripting Bash est un outil puissant et polyvalent pour automatiser les tâches d'administration système, gérer les ressources et effectuer d'autres tâches de routine dans les systèmes Unix/Linux.
Certains avantages du scripting shell sont :
Automatisation : Les scripts shell vous permettent d'automatiser des tâches et processus répétitifs, ce qui fait gagner du temps et réduit le risque d'erreurs manuelles.
Portabilité : Les scripts shell peuvent être exécutés sur diverses plateformes et systèmes d'exploitation, y compris Unix, Linux, macOS et même Windows via des émulateurs.
Flexibilité : Les scripts shell sont hautement personnalisables et peuvent être facilement modifiés pour répondre à des besoins spécifiques.
Accessibilité : Ils sont faciles à écrire et ne nécessitent aucun outil spécial. Ils peuvent être édités avec n'importe quel éditeur de texte.
Intégration : Ils peuvent être intégrés à d'autres outils comme des bases de données, des serveurs web et des services cloud.
Débogage : Ils sont faciles à déboguer grâce aux outils intégrés de rapport d'erreurs.
6.3. Aperçu du shell Bash et de l'interface en ligne de commande
Les termes "shell" et "bash" sont souvent utilisés de manière interchangeable, mais il existe une subtile différence.
Le terme "shell" désigne un programme qui fournit une interface en ligne de commande pour interagir avec un système d'exploitation. Bash (Bourne-Again SHell) est l'un des shells Unix/Linux les plus couramment utilisés et est le shell par défaut dans de nombreuses distributions.
Jusqu'à présent, les commandes que vous saisissiez étaient entrées dans un "shell".
Bien que Bash soit un type de shell, il en existe d'autres comme le Korn shell (ksh), le C shell (csh) et le Z shell (zsh). Chaque shell a sa propre syntaxe, mais ils partagent tous le même but.
Vous pouvez déterminer votre type de shell avec la commande ps :
ps
# sortie :
PID TTY TIME CMD
20506 pts/0 00:00:00 bash <--- le type de shell
20931 pts/0 00:00:00 ps
6.4. Comment créer et exécuter des scripts Bash
Conventions de nommage des scripts
Par convention, les scripts bash se terminent par .sh. Cependant, ils peuvent parfaitement fonctionner sans cette extension.
Ajouter le Shebang
Les scripts Bash commencent par un shebang. Le shebang est une combinaison de hash # et bang ! suivie du chemin vers le shell bash. C'est la première ligne du script. Elle indique au système d'exécuter le fichier via l'interprète bash.
Voici un exemple de déclaration shebang :
#!/bin/bash
Vous pouvez trouver le chemin de votre shell bash avec la commande :
which bash
Créer votre premier script bash
Notre premier script demande à l'utilisateur de saisir un chemin. En retour, son contenu sera listé.
Créez un fichier nommé run_all.sh avec l'éditeur de votre choix.
vim run_all.sh
Ajoutez les commandes suivantes dans votre fichier et sauvegardez-le :
#!/bin/bash
echo "Today is " `date`
echo -e "\nenter the path to directory"
read the_path
echo -e "\n your path has the following files and folders: "
ls $the_path
Décomposition ligne par ligne :
- Ligne #1 : Le shebang (
#!/bin/bash) pointe vers le chemin du shell bash. - Ligne #2 : La commande
echoaffiche la date et l'heure actuelles. Notez quedateest entre accents graves (backticks). - Ligne #4 : On demande à l'utilisateur de saisir un chemin valide.
- Ligne #5 : La commande
readlit l'entrée et la stocke dans la variablethe_path. - Ligne #8 : La commande
lsutilise la variable contenant le chemin et affiche les fichiers et dossiers.
Exécuter le script bash
Pour rendre le script exécutable, attribuez les droits d'exécution à votre utilisateur avec cette commande :
chmod u+x run_all.sh
Ici,
chmodmodifie les droits du fichier pour l'utilisateur actuel (u).+xajoute les droits d'exécution.run_all.shest le fichier que nous souhaitons exécuter.
Vous pouvez lancer le script par l'une de ces méthodes :
sh run_all.shbash run_all.sh./run_all.sh
6.5. Les bases du scripting Bash
Commentaires dans le scripting bash
Les commentaires commencent par un #. Cela signifie que toute ligne débutant par un # est un commentaire et sera ignorée par l'interprète.
Variables et types de données dans Bash
Les variables permettent de stocker des données. Il n'y a pas de types de données stricts dans Bash ; une variable peut stocker des nombres, des caractères ou des chaînes.
- Assigner une valeur directement :
country=Netherlands - Assigner via une commande :
current_date=$(date)
Pour accéder à la valeur d'une variable, ajoutez $ devant son nom : echo $country.
Conventions de nommage des variables
- Doivent commencer par une lettre ou un souligné (
_). - Peuvent contenir des lettres, des chiffres et des soulignés.
- Sont sensibles à la casse (
myvar!=MYVAR). - Ne doivent pas contenir d'espaces ou de caractères spéciaux.
Entrées et sorties dans les scripts Bash
Récupérer des entrées :
- Utiliser
readpour l'entrée utilisateur. - Lire depuis un fichier avec une boucle
while. - Utiliser les arguments de ligne de commande (
$1,$2, etc.).
Afficher des sorties :
echopour afficher dans le terminal.>pour écrire dans un fichier (écrase le contenu).>>pour ajouter à la fin d'un fichier.
Instructions conditionnelles (if/else)
Syntaxe :
if [[ condition ]];
then
statement
elif [[ condition ]]; then
statement
else
do this by default
fi
Boucles et branchements
Boucle While : s'exécute tant qu'une condition est vraie. Boucle For : s'exécute un nombre spécifique de fois ou sur une liste d'éléments. Case statements : utilisés pour comparer une valeur à plusieurs motifs (équivalent du switch).
Partie 7 : Gérer les paquets logiciels sous Linux
7.1. Paquets et gestion des paquets
Un paquet est une archive contenant tous les fichiers nécessaires à l'exécution d'un programme, ainsi que des scripts d'installation.
Source vs Binaire
- Source : Code lisible par l'humain qui doit être compilé.
- Binaire : Code compilé prêt à être exécuté par la machine.
Gestionnaires de paquets
Chaque distribution possède son propre gestionnaire. Sous Ubuntu/Debian, c'est apt. Il gère automatiquement les dépendances (autres logiciels nécessaires au fonctionnement du programme choisi).
7.2. Installer un paquet via la ligne de commande
sudo apt update: Met à jour la liste des paquets disponibles.sudo apt install <nom_paquet>: Installe un logiciel.sudo apt upgrade: Met à jour tous les logiciels installés.sudo apt remove <nom_paquet>: Désinstalle un logiciel.
7.4. Installer des paquets téléchargés (.deb)
Pour installer un fichier .deb téléchargé manuellement :
sudo dpkg -i package_name.deb
Partie 8 : Sujets avancés sur Linux
8.1. Gestion des utilisateurs
- Root : Le super-utilisateur avec tous les droits (UID 0).
- Utilisateurs système : Pour faire tourner des services.
- Utilisateurs réguliers : Pour les humains.
Les informations des utilisateurs sont stockées dans /etc/passwd et les groupes dans /etc/group.
Permissions de fichiers (rwx)
r(read) : lire.w(write) : écrire/modifier.x(execute) : exécuter.
Utilisez chmod pour changer les permissions et chown pour changer le propriétaire.
8.2 Connexion à des serveurs distants via SSH
SSH (Secure Shell) permet de se connecter à une machine distante de manière sécurisée sur le port 22.
ssh username@server_ip
8.3. Analyse et parsing de logs avancés
Les outils principaux sont :
grep: recherche de motifs.sed: éditeur de flux pour transformer du texte.awk: langage de traitement de texte structuré (colonnes).cut: extraction de sections de lignes.sort/uniq: tri et suppression des doublons.
8.4. Gérer les processus Linux
Un processus est une instance de programme en cours d'exécution.
ps aux: liste tous les processus.top: affiche les processus en temps réel.kill -9 <PID>: force l'arrêt d'un processus.fg/bg: passer un processus au premier ou à l'arrière-plan.
8.6 Automatisation avec Cron
Les tâches Cron permettent de planifier des scripts.
Syntaxe : minute heure jour mois jour_semaine commande
Exemple : 0 22 * * 1-5 script.sh (tous les jours de la semaine à 22h).
8.7. Réseau
ifconfigouip addr: voir les interfaces réseau.ping: tester la connectivité.netstat: voir les connexions actives.curl: transférer des données via URL.
8.8. Dépannage (Troubleshooting)
uptime: charge système et temps d'activité.free -h: utilisation de la mémoire vive.df -h: espace disque disponible.sar: rapports d'activité système historiques.
Conclusion
Merci d'avoir lu ce livre jusqu'au bout. Si vous l'avez trouvé utile, n'hésitez pas à le partager.
Ce livre ne s'arrête pas là. Je continuerai à l'améliorer et à ajouter de nouveaux contenus. Si vous trouvez des erreurs ou avez des suggestions, n'hésitez pas à ouvrir une PR ou une Issue.
Apprendre Linux est un voyage continu. Restez curieux et continuez à pratiquer !