


Article original : Learn API Fundamentals and Architecture – A Beginner-Friendly Guide
Voici quelques questions pour vous : Comment vous connectez-vous à des applications avec votre compte Google, Apple ou Microsoft ? Comment fonctionnent les paiements en ligne avec Paystack ou PayPal ? Comment des applications comme Facebook et Instagram partagent-elles des informations et des notifications ?
La réponse est : elles utilisent des API. Ce sont des outils puissants qui pilotent le développement mobile et web ainsi qu'une large gamme d'applications, y compris les services cloud, les appareils IoT, les logiciels de bureau, et bien plus encore.
Les API permettent la communication entre les applications, facilitant l'échange et la vérification des données.
Dans cet article, vous apprendrez tout sur les API : les différents types, leur architecture et les compromis entre les différentes architectures.
Voici ce que nous allons aborder :
Cet article est parfaitement adapté aux débutants en développement web et mobile ainsi qu'aux développeurs cherchant une compréhension concise des API et de leur fonctionnement.
Qu'est-ce qu'une API ?
API signifie Application Programming Interface (Interface de Programmation d'Application). Il s'agit d'un ensemble de règles et de protocoles qui permettent à différents systèmes logiciels de communiquer entre eux. Une API définit la manière dont les applications demandent des services et échangent des données, agissant comme un contrat clair entre un client et un serveur.
Les API simplifient le code complexe en commandes simples, permettant aux développeurs de connecter des systèmes et d'utiliser des fonctionnalités intégrées sans avoir besoin de connaître tous les rouages internes.
Comment fonctionnent les API ?
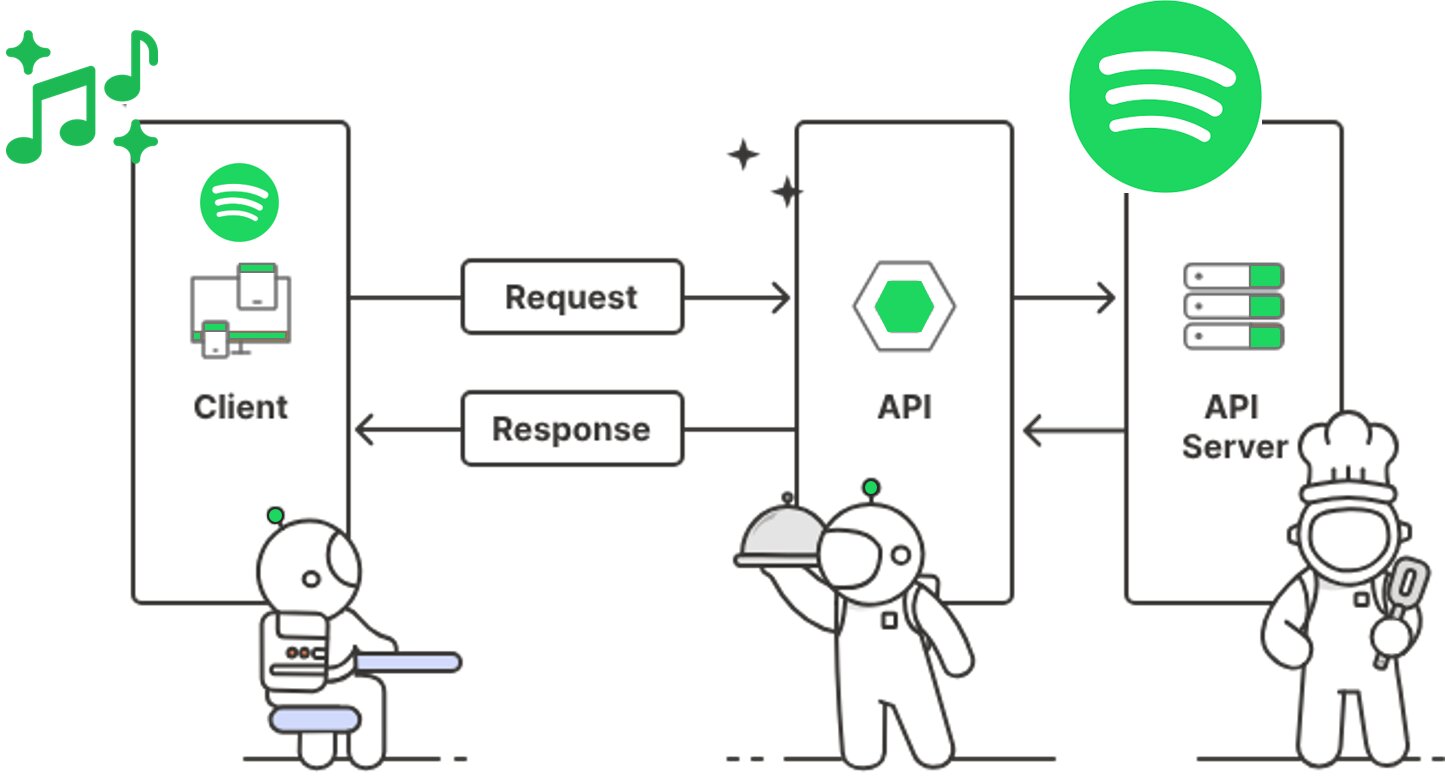
Imaginez un restaurant : le client (client) commande de la nourriture via le serveur (API), qui communique ensuite la commande à la cuisine (serveur). La cuisine prépare le repas et le renvoie au client par l'intermédiaire du serveur. Tout comme le serveur au restaurant, l'API gère les requêtes et les réponses, permettant au client de profiter du repas sans avoir besoin de connaître les détails du fonctionnement de la cuisine.
Un exemple plus concret : lorsque vous achetez un abonnement en ligne, vos informations de paiement sont envoyées en toute sécurité à Paystack via son API de paiement. L'API est un intermédiaire qui prend votre requête, vérifie et traite vos détails de paiement avec la banque, puis renvoie une confirmation au site web sans exposer directement de données sensibles.
Techniquement, un client initie une requête destinée à un serveur, spécifiant soit une récupération de données, soit l'exécution d'une procédure. Dès la réception et l'authentification de cette requête, l'API effectue les opérations requises. Ensuite, l'API envoie une réponse au client, incluant le résultat de la requête (succès ou échec) et tous les éléments de données demandés.
Pourquoi les API sont-elles importantes ?
Les API sont cruciales dans le développement logiciel car elles facilitent la connexion entre différentes applications et services. Elles vous permettent d'intégrer des fonctionnalités externes sans avoir à tout construire de zéro, ce qui permet de gagner du temps et de réduire la complexité grâce à des commandes standardisées.
Pour les utilisateurs, les API améliorent également la sécurité et l'expérience utilisateur. Elles servent de passerelles sécurisées qui filtrent les échanges de données entre les applications et les services externes, protégeant les informations sensibles tout en garantissant des interactions fluides et fiables.
Les types d'API
Les types d'API sont principalement classés par leur accessibilité et leur usage. Il existe quatre types d'API, à savoir :
API ouvertes (Public)
API partenaires
API internes (Private)
API composites
API ouvertes
Les API ouvertes sont des API mises à la disposition du grand public. Cela encourage les développeurs, les organisations et d'autres personnes à les utiliser pour développer des applications, les intégrer dans leurs services et les améliorer. Les API ouvertes fournissent un accès standardisé aux données ou aux services via Internet.
Voici quelques API ouvertes très utiles :
TradeWatch – Données du marché financier en temps réel
SerpAPI’s Search API – API Google SERP en temps réel
TwitterApi.io – Accès aux données historiques et en temps réel
Instagram Post Generator – Génération de posts avec des modèles issus de pages IG populaires
API partenaires
Les API partenaires sont partagées avec des partenaires commerciaux spécifiques et nécessitent souvent une authentification et des accords. Elles remplissent des fonctions essentielles pour les entreprises et les applications.
Par exemple, une API de paiement comme Paystack communique directement avec les fournisseurs de services et les plateformes bancaires pour traiter les paiements de produits et services.
API internes
Les API internes sont utilisées pour la communication interne au sein d'une organisation. Elles permettent l'intégration et rationalisent les processus internes. Les équipes internes utilisent l'API pour accéder aux données et les partager entre leurs applications. L'API n'est pas exposée au public, garantissant que la logique métier sensible reste sécurisée.
Un exemple est l'API interne d'une entreprise qui connecte ses systèmes de RH, de paie et de gestion de projet.
API composites
Les API composites combinent plusieurs appels d'API en une seule requête. Elles sont essentielles dans les architectures de microservices, où une seule opération peut nécessiter des données provenant de plusieurs services. Un seul appel d'API déclenche des requêtes vers plusieurs API sous-jacentes, et l'API composite combine ensuite les réponses pour renvoyer un résultat unifié.
Par exemple, une plateforme d'e-commerce peut utiliser une API composite pour récupérer les détails d'un produit, son prix et les informations de stock en une seule fois, réduisant ainsi la latence et simplifiant le processus d'intégration.
Types d'architectures d'API
Les API sont structurées différemment selon le cas d'utilisation, l'évolutivité, la sécurité et l'accessibilité. Il existe plusieurs façons de structurer une API, mais nous nous concentrerons uniquement sur les styles architecturaux les plus répandus dans le développement Web. Ils incluent :
REST
SOAP
GraphQL
gRPC
API REST
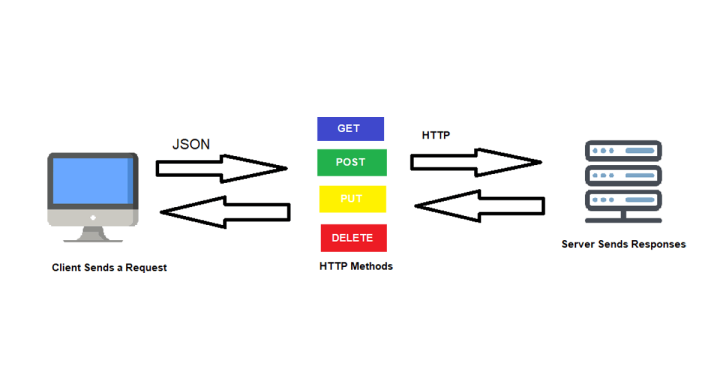
Representational State Transfer (REST) est un style architectural qui utilise les méthodes HTTP (POST, GET, PUT, DELETE) pour effectuer des opérations CRUD (Create, Read, Update, Delete) sur des URI basées sur des ressources.
Les API REST sont construites avec des frameworks comme Express.js (Node.js), Django/Flask (Python) et Spring Boot (Java).
Composants clés
Ressources et points de terminaison (endpoints) :
Les entités exposées par l'API peuvent inclure n'importe quoi : utilisateurs, produits, documents, etc.
Chaque ressource est identifiée par une URI (Uniform Resource Identifier) unique.
Méthodes HTTP :
GET : Récupère une ressource.
POST : Crée une nouvelle ressource.
PUT : Met à jour une ressource existante.
DELETE : Supprime une ressource.
PATCH : Met à jour partiellement une ressource existante.
Représentation des données :
Les ressources peuvent avoir plusieurs représentations (par exemple, JSON, XML).
L'API répond avec la représentation demandée, permettant aux données d'être structurées et analysées facilement.
En-têtes HTTP et paramètres de requête :
Les en-têtes HTTP fournissent des informations supplémentaires sur la requête ou la réponse.
Ils peuvent être utilisés pour l'authentification, la négociation de contenu et d'autres usages.
Absence d'état (Statelessness) :
Chaque requête d'un client vers un serveur doit contenir toutes les informations nécessaires pour comprendre et traiter la requête.
Le serveur ne stocke aucun état client entre les requêtes.
D'autres composants notables sont la mise en cache (cacheability), les codes de statut HTTP et HATEOAS. Ensemble, ces composants définissent la structure et le comportement des systèmes RESTful, permettant une communication fluide et efficace entre les clients et les serveurs.
Aperçu du fonctionnement
Les API REST exposent des ressources via des URI uniques et permettent aux clients d'effectuer des opérations en utilisant des méthodes HTTP telles que GET, POST, PUT, DELETE et PATCH. Les clients peuvent demander des données dans divers formats, tels que JSON ou XML, et inclure des détails supplémentaires via les en-têtes HTTP et les paramètres de requête.
Chaque requête est sans état et contient toutes les informations requises pour le traitement sans dépendre de données client stockées. L'API utilise également les codes de statut HTTP, la mise en cache et HATEOAS pour gérer les réponses et guider les interactions ultérieures, garantissant un cadre de communication fluide et efficace entre les clients et les serveurs.
Exemple pratique et cas d'utilisation réels
Pour illustrer le fonctionnement des API REST en pratique, considérons une API de livres qui permet aux utilisateurs de gérer une collection d'ouvrages. Notre exemple d'API a été créé en utilisant les frameworks NodeJS et ExpressJS. Je n'expliquerai pas ici comment ces frameworks fonctionnent réellement, car cela dépasse le cadre de cet article. Donc, si vous ne comprenez pas la syntaxe du code ci-dessous, ne vous inquiétez pas – concentrez-vous simplement sur la logique des Requêtes et des Réponses.
Cette API suit les principes REST en utilisant les méthodes HTTP standard pour effectuer des opérations CRUD (Create, Read, Update, Delete) :
const express = require("express"); const bodyParser = require("body-parser");
const app = express(); app.use(bodyParser.json());
const app = express();
app.use(bodyParser.json());
// Dummy Database
let books = [
{ id: 1, title: "The Pragmatic Programmer", author: "Andy Hunt" },
{ id: 2, title: "Clean Code", author: "Robert C. Martin" },
];
// GET all books (Client requests, Server responds)
app.get("/books", (req, res) => res.json(books));
// GET a single book by ID
app.get("/books/:id", (req, res) => {
const book = books.find((b) => b.id === parseInt(req.params.id));
book ? res.json(book) : res.status(404).json({ message: "Not found" });
});
// POST a new book (Client sends data, Server updates database)
app.post("/books", (req, res) => {
const newBook = { id: books.length + 1, ...req.body };
books.push(newBook);
res.status(201).json(newBook);
});
// PUT (Update) a book
app.put("/books/:id", (req, res) => {
const book = books.find((b) => b.id === parseInt(req.params.id));
if (book) {
Object.assign(book, req.body);
res.json(book);
} else {
res.status(404).json({ message: "Not found" });
}
});
// DELETE a book
app.delete("/books/:id", (req, res) => {
const index = books.findIndex((b) => b.id === parseInt(req.params.id));
if (index !== -1) {
books.splice(index, 1);
res.json({ message: "Deleted" });
} else {
res.status(404).json({ message: "Not found" });
}
});
app.listen(3000, () => console.log("API running on port 3000"));
Voici ce qui se passe dans ce code :
Le client envoie une requête : Un utilisateur (ou une application frontend) demande des données en utilisant des méthodes HTTP comme GET, POST, PUT ou DELETE. Exemple : GET
/booksdemande tous les livres ou POST/booksenvoie un nouveau livre à la base de données.Le serveur traite la requête : Le serveur reçoit la requête, cherche les données (par exemple, dans une base de données ou un tableau en mémoire) et les traite.
Le serveur envoie une réponse : Le serveur renvoie une réponse JSON contenant les données demandées ou un message de confirmation. Voici un exemple :
[
{ "id": 1, "title": "The Pragmatic Programmer", "author": "Andy Hunt" },
{ "id": 2, "title": "Clean Code", "author": "Robert C. Martin" }
]
- Le client reçoit et utilise les données : Le frontend ou un autre service consomme la réponse de l'API et l'affiche ou la traite en conséquence.
Les équipes utilisent les API REST pour les services web, les applications mobiles et les intégrations cloud. Les plateformes de médias sociaux récupèrent les publications, tandis que les sites d'e-commerce extraient les détails des produits. Les passerelles de paiement traitent les transactions et les applications météo accèdent aux prévisions en temps réel. La simplicité et l'évolutivité de REST en font le choix privilégié pour les API publiques et internes.
API SOAP
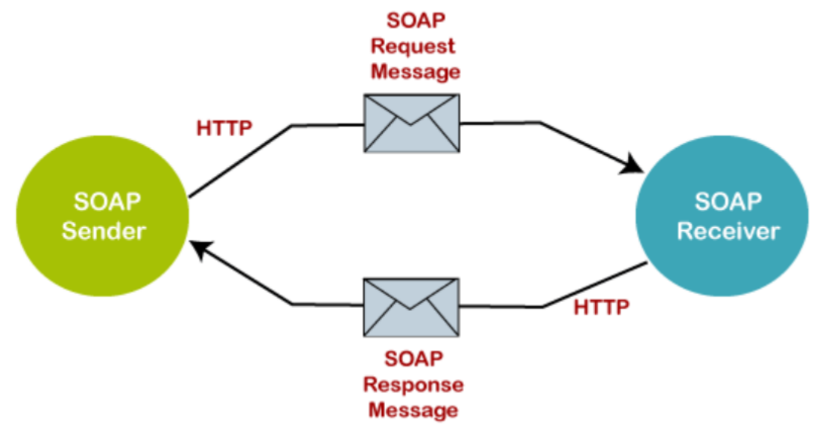
Le Simple Object Access Protocol (SOAP) utilise le XML pour la messagerie et inclut des normes intégrées pour la sécurité, les transactions et la gestion des erreurs. Son contrat formel est défini par un WSDL (Web Services Description Language).
Cette architecture privilégie la sécurité et la fiabilité grâce à des fonctionnalités telles que WS-Security et la gestion des transactions, ce qui la rend adaptée aux applications d'entreprise complexes qui nécessitent des normes rigides et une gestion robuste des erreurs.
Les API SOAP sont créées à l'aide de frameworks ou d'outils tels qu'Apache CXF, .NET WCF et JAX-WS (Java).
Composants clés
Enveloppe SOAP (SOAP envelope) :
Il s'agit de l'élément racine d'un message SOAP qui définit la structure globale du document XML.
Elle contient l'en-tête SOAP (Header) et le corps SOAP (Body).
Corps SOAP (SOAP body) :
Cette section contient les données réelles échangées entre le client et le serveur.
Elle inclut les messages de requête ou de réponse, qui sont généralement structurés comme des éléments XML.
WSDL (Web Services Description Language) :
Il s'agit d'un document XML qui décrit le service web, y compris ses opérations, les formats de message et les types de données.
Il agit comme un contrat entre le client et le serveur, précisant comment interagir avec l'API.
Processeur SOAP :
Il s'agit du composant logiciel qui traite les messages SOAP.
Il analyse le document XML, extrait les données pertinentes et effectue l'opération demandée.
Il existe également le point de terminaison SOAP (SOAP Endpoint), qui est l'URL où le service SOAP peut être accédé, et le schéma XML (XSD), qui définit la structure et les types de données utilisés dans le XML du message SOAP.
Aperçu du fonctionnement
Les API SOAP fonctionnent en encapsulant les données dans une structure basée sur XML définie par une enveloppe SOAP, qui contient à la fois un en-tête pour les métadonnées et un corps pour les informations réelles de requête ou de réponse. Le corps transporte les données d'échange, tandis qu'un document WSDL sert de contrat détaillant les opérations du service, les formats de message et les types de données.
Un processeur SOAP analyse ensuite le XML, extrait les données pertinentes et exécute les opérations demandées selon les règles définies par un schéma XML (XSD) d'accompagnement. La communication avec le service s'effectue via un point de terminaison SOAP spécifique, garantissant un cadre standardisé et interopérable pour les interactions de services web.
Exemples pratiques et cas d'utilisation réels
Pour illustrer les API SOAP et leur fonctionnement pratique, considérons une API de service bancaire basée sur SOAP qui fournit des opérations sécurisées pour la gestion des comptes et des transactions. Les API SOAP utilisent la messagerie XML pour garantir une communication sécurisée et structurée entre les systèmes. La création d'une API SOAP et de la messagerie XML dépassant le cadre de cet article, nous nous concentrerons ici uniquement sur la logique de requête et de réponse.
Comment ça marche :
- Récupérer les informations d'un compte : Le client envoie une requête XML pour obtenir les détails du compte d'un utilisateur :
<soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/"
xmlns:bank="http://example.com/bank">
<soapenv:Header/>
<soapenv:Body>
<bank:GetAccountDetails>
<bank:AccountNumber>123456789</bank:AccountNumber>
</bank:GetAccountDetails>
</soapenv:Body>
</soapenv:Envelope>
Le serveur répond par un message XML contenant les détails du compte :
<soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/">
<soapenv:Body>
<GetAccountDetailsResponse>
<AccountNumber>123456789</AccountNumber>
<Balance>5000.00</Balance>
<Currency>USD</Currency>
</GetAccountDetailsResponse>
</soapenv:Body>
</soapenv:Envelope>
Traiter un transfert d'argent : Le client soumet une demande de transfert avec des détails d'authentification :
<soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/" xmlns:bank="http://example.com/bank"> <soapenv:Header/> <soapenv:Body> <bank:TransferFunds> <bank:FromAccount>123456789</bank:FromAccount> <bank:ToAccount>987654321</bank:ToAccount> <bank:Amount>100.00</bank:Amount> <bank:Currency>USD</bank:Currency> </bank:TransferFunds> </soapenv:Body> </soapenv:Envelope>En cas de succès, le serveur renvoie une réponse de confirmation :
<soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/"> <soapenv:Body> <TransferFundsResponse> <Status>Success</Status> <TransactionID>TXN987654</TransactionID> </TransferFundsResponse> </soapenv:Body> </soapenv:Envelope>
Les banques, les prestataires de soins de santé et les agences gouvernementales utilisent SOAP pour des API sécurisées et fiables. Les institutions financières traitent les transactions avec une authentification stricte, tandis que les systèmes de santé échangent les données des patients selon des réglementations de conformité. Les compagnies aériennes s'appuient sur SOAP pour la réservation et la billetterie, garantissant une intégrité constante des données entre les systèmes.
API GraphQL
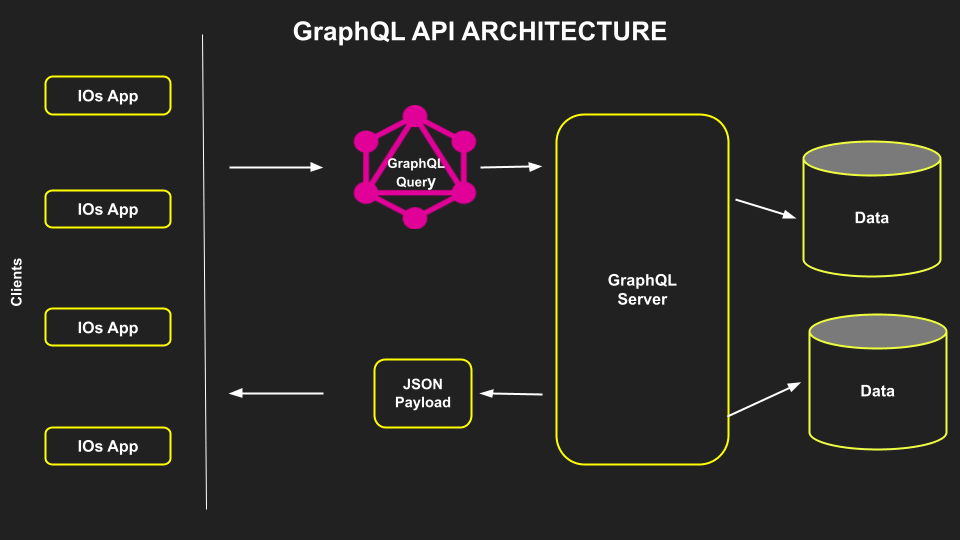
GraphQL est un langage de requête et un environnement d'exécution pour les API développé par Facebook. Il permet aux clients de demander exactement les données dont ils ont besoin en une seule requête, réduisant ainsi la sur-récupération (over-fetching) et la sous-récupération (under-fetching) de données.
Composants clés
Schéma (Schema) : C'est le cœur d'une API GraphQL. Il définit la structure de vos données, y compris les types d'objets, leurs champs et leurs relations. Il agit comme un contrat entre le client et le serveur, spécifiant quelles données peuvent être interrogées.
Types : Ils définissent la structure des objets dans vos données. Ils spécifient les champs de chaque objet et les types de données de ces champs.
Champs (Fields) : Ce sont les pièces individuelles de données qui peuvent être interrogées sur un objet.
Requêtes (Queries) : Ce sont les demandes du client pour récupérer des données. Elles spécifient les champs que le client souhaite récupérer.
Mutations : Ce sont les demandes du client pour modifier des données (créer, mettre à jour ou supprimer).
Résolveurs (Resolvers) : Ce sont des fonctions qui récupèrent les données pour chaque champ du schéma. Ils connectent le schéma GraphQL aux sources de données sous-jacentes.
Abonnements (Subscriptions) : Ils permettent des mises à jour en temps réel. Les clients peuvent s'abonner à des événements spécifiques, et le serveur poussera les mises à jour dès qu'elles se produisent.
Aperçu du fonctionnement
GraphQL définit un schéma qui spécifie les types de données disponibles et leurs relations. Les clients construisent ensuite des requêtes ou des mutations qui demandent précisément les champs de données nécessaires. Le serveur GraphQL traite ces requêtes en utilisant des résolveurs pour extraire les données des sources backend.
Le serveur valide la requête par rapport au schéma, exécute les résolveurs et renvoie une réponse JSON contenant uniquement les données demandées. Les clients peuvent établir des abonnements pour des mises à jour en temps réel, permettant au serveur de pousser les modifications de données au fur et à mesure qu'elles surviennent. Cette approche minimise l'over-fetching et l'under-fetching, améliorant l'efficacité et la flexibilité de la récupération des données.
Exemples pratiques et cas d'utilisation réels
Explorons le fonctionnement pratique des API GraphQL en considérant une API d'e-commerce propulsée par GraphQL. Cette API peut récupérer efficacement les détails des produits, les avis et la disponibilité des stocks. Le serveur est créé avec NodeJS et Apollo Server. La création du serveur dépassant le cadre de cet article, nous nous concentrerons sur le Schéma (comment une base de données relationnelle est structurée et représentée visuellement) et la logique de Requête et de Réponse.
- Schéma :
# Schema (schema.graphql)
type Product {
id: ID!
name: String!
description: String
price: Float!
inventory: Int!
category: String!
}
type Query {
product(id: ID!): Product
products(category: String): [Product!]!
}
type Mutation {
createProduct(name: String!, description: String, price: Float!, inventory: Int!, category: String!): Product!
updateProductInventory(id: ID!, inventory: Int!): Product!
}
Le Schéma définit les types de données (Product, Query, Mutation) et spécifie les requêtes disponibles (product, products), ainsi que les mutations (createProduct, updateProductInventory). Il utilise le système de types GraphQL (String, Int, Float, ID, [ ], !).
Requêtes et Réponse
Récupération des données produit - Un client demande des champs spécifiques d'un produit (par exemple, le nom, le prix et la description) :
query { product(id: "123") { name price description } }En cas de succès, le serveur répond avec uniquement les données demandées :
{ "data": { "product": { "name": "Wireless Headphones", "price": 99.99, "inStock": true } } }Créer un nouveau produit :
mutation { createProduct(name: "Mouse", price: 30, inventory: 100, category: "Electronics") { id name price } }Mettre à jour les informations d'un produit :
mutation { updateProduct(id: "123", price: 89.99) { name price } }En cas de succès, le serveur renvoie les détails mis à jour :
{ "data": { "updateProduct": { "name": "Wireless Headphones", "price": 89.99 } } }
Des entreprises comme Facebook et Shopify utilisent GraphQL pour des API efficaces et flexibles. Les applications d'e-commerce et sociales ne récupèrent que les données nécessaires, réduisant ainsi l'over-fetching. Les applications mobiles optimisent les performances, tandis que les outils d'analyse agrègent des données complexes de manière transparente.
API gRPC
Remote Procedure Call (gRPC) est un framework RPC haute performance qui sérialise les données structurées en utilisant HTTP/2 et les Protocol Buffers. Il prend en charge la communication synchrone et asynchrone ainsi que des fonctionnalités comme le streaming.
HTTP/2 est la dernière évolution de HTTP, conçue avec des fonctionnalités passionnantes comme le tramage binaire, le multiplexage, la compression d'en-tête et le server push pour booster les performances et réduire la latence. gRPC tire pleinement parti de ces capacités, permettant une communication rapide, efficace et simultanée, ce qui en fait un choix parfait pour les microservices et les applications en temps réel.
Composants clés
Définition du service : Elle est définie dans un fichier .proto. Elle spécifie les services offerts et les méthodes RPC disponibles, agissant comme le contrat entre le client et le serveur.
Les messages sont des structures de données définies à l'aide de Protocol Buffers, qui sérialisent et désérialisent efficacement les données entre les systèmes.
Stubs : Code client et serveur généré automatiquement qui permet au client d'appeler des méthodes distantes comme si elles étaient locales et permet au serveur d'implémenter la logique du service.
Canaux (Channels) : Ils gèrent la connexion entre le client et le serveur, s'occupant de la communication réseau sous-jacente.
Méthodes RPC : gRPC prend en charge différents types d'appels, y compris l'unaire (requête-réponse unique), le streaming client, le streaming serveur et le streaming bidirectionnel, chacun adapté à différents cas d'utilisation.
Intercepteurs et métadonnées : Ils fournissent des mécanismes pour ajouter des fonctionnalités supplémentaires, telles que l'authentification, la journalisation et la gestion des erreurs, en attachant des métadonnées aux appels RPC.
Aperçu du fonctionnement
gRPC permet aux développeurs de définir des contrats de service et des types de messages dans un fichier .proto avec Protocol Buffers, servant de plan directeur pour les méthodes RPC disponibles. Le générateur de code produit des stubs client et serveur, permettant d'invoquer des procédures distantes comme des fonctions locales, tandis que les canaux gèrent la communication réseau basée sur HTTP/2.
Il prend en charge les flux unaires, le streaming client, le streaming serveur et le streaming bidirectionnel pour différents modèles d'échange de données. De plus, des intercepteurs et des métadonnées peuvent être intégrés pour des tâches comme l'authentification et la journalisation, maintenant le système robuste, sécurisé et efficace.
Exemples pratiques et cas d'utilisation réels
Considérons une application de covoiturage qui utilise gRPC pour une communication rapide entre les clients (applications mobiles) et les services backend. gRPC utilise la sérialisation binaire via les protocol buffers (Protobuf) au lieu de formats textuels comme JSON ou XML. Cela rend la communication réseau nettement plus rapide et plus efficace.
- Le fichier .proto définit la structure de l'API :
syntax = "proto3";
service RideService {
rpc RequestRide(RideRequest) returns (RideResponse);
rpc StreamRideUpdates(RideUpdateRequest) returns (stream RideUpdate);
}
message RideRequest {
string user_id = 1;
string pickup_location = 2;
string destination = 3;
}
message RideResponse {
string ride_id = 1;
string driver_name = 2;
string car_model = 3;
}
message RideUpdate {
string ride_id = 1;
string status = 2;
string driver_location = 3;
}
message RideUpdateRequest {
string ride_id = 1;
}
Lorsqu'un client envoie une RideRequest, elle est sérialisée dans un format binaire compact à l'aide de Protobuf. Cela réduit la taille de la charge utile, accélère la transmission et améliore l'efficacité. Le serveur la désérialise en un objet structuré avant de la traiter.
Requête et Réponse :
Demander une course : Le client envoie une demande de course d'un simple clic sur un bouton, ce qui implique :
{ "user_id": "U123", "pickup_location": "Central Park", "destination": "Times Square" }Le serveur répond avec les détails du chauffeur :
{ "ride_id": "R456", "driver_name": "John Doe", "car_model": "Toyota Prius" }Vous vous demandez peut-être pourquoi les requêtes et les réponses sont affichées en JSON alors que gRPC n'utilise pas de formats textuels comme JSON et XML. Le flux binaire compressé utilisé dans gRPC n'est pas lisible par l'homme comme le JSON. C'est un format d'encodage compact et efficace qui nécessite une désérialisation Protobuf en coulisses pour être compris. En format de flux binaire compressé, la requête ou la réponse ressemblera à ceci :
08 D2 04 12 0D 43 65 6E 74 72 61 6C 20 50 61 72 6B 1A 0B 54 69 6D 65 73 20 53 71 75 61 72 65Streaming des mises à jour de la course : Une fois qu'une course est attribuée, le serveur diffuse des mises à jour en temps réel au client :
{ "ride_id": "R456", "status": "Driver on the way", "driver_location": "5th Avenue" }
Les entreprises utilisent gRPC pour des applications en temps réel haute performance nécessitant une communication de service efficace. Des géants de la technologie comme Google, Netflix et Dropbox utilisent gRPC pour des microservices évolutifs. Les applications de covoiturage diffusent l'emplacement des chauffeurs en direct, tandis que les plateformes fintech gèrent des transactions sécurisées à faible latence. Les systèmes IoT et les applications d'IA dépendent de gRPC pour l'échange de données en temps réel et des interactions efficaces.
Comment choisir une architecture d'API
La sélection d'une architecture d'API implique d'équilibrer divers facteurs, notamment la performance, l'évolutivité, la facilité d'utilisation et la sécurité, selon les besoins spécifiques de votre projet.
REST est connu pour sa simplicité et sa conception sans état, ce qui facilite l'évolutivité et l'utilisation, mais sa sécurité dépend principalement de mesures externes comme HTTPS et des mécanismes d'authentification appropriés.
SOAP, bien que plus complexe, fournit des normes de sécurité intégrées robustes (comme WS-Security) et un support transactionnel fiable, ce qui le rend adapté aux environnements d'entreprise.
GraphQL offre une récupération de données efficace et de hautes performances en permettant aux clients de ne demander que les données dont ils ont besoin. Cependant, il peut nécessiter des mesures de sécurité supplémentaires telles que la limitation de la profondeur des requêtes et une authentification appropriée côté serveur.
gRPC offre des performances exceptionnelles et est idéal pour les microservices ayant des besoins en données en temps réel. Il exploite HTTP/2 et TLS pour une communication sécurisée et efficace, bien qu'il présente une courbe d'apprentissage plus raide.
Le tableau ci-dessous résume les caractéristiques et les compromis entre ces architectures :
| Caractéristique | REST | SOAP | GraphQL | gRPC |
| Performance | Modérée (Risque d'over-fetching) | Faible | Élevée | Élevée |
| Évolutivité | Élevée | Modérée | Élevée | Très élevée (Efficace pour les microservices et le temps réel) |
| Facilité d'utilisation | Simple et largement adopté | Complexe | Intuitif pour les clients (La complexité côté serveur peut croître) | Courbe d'apprentissage raide |
| Sécurité | Repose sur des mécanismes externes (HTTPS, OAuth, etc.) | Sécurité intégrée forte via WS-Security et contrats formels | Nécessite des mesures supplémentaires (validation de requête, limitation de débit) | Haute sécurité avec support TLS intégré et protocoles d'authentification robustes |
Conclusion et tendances futures
Les API sont devenues un pilier du développement logiciel moderne, facilitant une communication et un échange de données fluides entre diverses applications. Leur impact est indéniable, des API publiques qui alimentent l'innovation aux API privées qui rationalisent les processus internes.
Comprendre les diverses architectures d'API, comme REST, SOAP, GraphQL et gRPC, permet aux développeurs de sélectionner l'approche optimale pour leurs besoins spécifiques, en équilibrant performance, évolutivité et facilité d'utilisation.
Pour l'avenir, le paysage des API s'apprête à connaître des changements passionnants. Avec les API pilotées par l'IA, les architectures décentralisées et les mesures de sécurité améliorées, nous verrons de nouvelles façons de construire et d'interagir avec les logiciels. L'évolution continue des normes d'API et la croissance des plateformes low-code/no-code rendent le développement d'API plus accessible à tous.