

Article original : Apache Storm is awesome. This is why (and how) you should be using it.
Par Usama Ashraf
Les flux de données continus sont omniprésents et le deviennent encore plus avec le nombre croissant d'appareils IoT utilisés. Bien sûr, cela signifie que d'énormes volumes de données sont stockés, traités et analysés pour fournir des résultats prédictifs et exploitables.
Mais les pétaoctets de données prennent beaucoup de temps à analyser, même avec des outils comme Hadoop (aussi bon que MapReduce puisse être) ou Spark (un remède aux limitations de MapReduce).
Souvent, nous n'avons pas besoin de déduire des modèles sur de longues périodes. Parmi les pétaoctets de données entrantes collectées sur des mois, à un moment donné, nous n'avons peut-être pas besoin de prendre en compte toutes ces données, juste un instantané en temps réel. Peut-être n'avons-nous pas besoin de connaître le hashtag le plus tendance sur cinq ans, mais juste celui de maintenant.
C'est pour cela qu'Apache Storm a été conçu, pour accepter des tonnes de données arrivant extrêmement rapidement, éventuellement de diverses sources, les analyser et publier des mises à jour en temps réel vers une interface utilisateur ou un autre endroit... sans stocker aucune donnée réelle.
Cet article n'est pas le guide ultime d'Apache Storm, et ce n'est pas son but. Storm est assez vaste, et un seul article ne peut probablement pas lui rendre justice de toute façon. Bien sûr, toute addition, tout retour ou toute critique constructive sera grandement apprécié.
D'accord, maintenant que c'est dit, voyons ce que nous allons couvrir :
- La nécessité de Storm, le 'pourquoi' de celui-ci, ce qu'il est et ce qu'il n'est pas
- Une vue d'ensemble de son fonctionnement.
- À quoi ressemble approximativement une topologie Storm en code (Java)
- Mise en place et manipulation d'un cluster Storm prêt pour la production sur Docker.
- Quelques mots sur la fiabilité du traitement des messages.
Je suppose également que vous êtes au moins quelque peu familier avec Docker et la conteneurisation.
Comment cela fonctionne
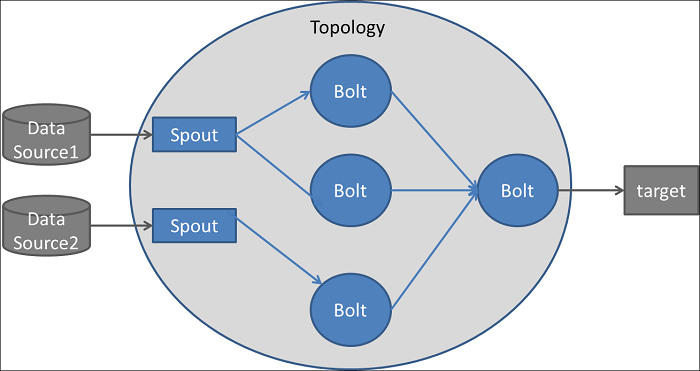
L'architecture d'Apache Storm peut être comparée à un réseau de routes reliant un ensemble de points de contrôle. Le trafic commence à un certain point de contrôle (appelé un spout) et passe par d'autres points de contrôle (appelés bolts).
Le trafic est bien sûr le flux de données qui est récupéré par le spout (à partir d'une source de données, une API publique par exemple) et acheminé vers divers bolts où les données sont filtrées, nettoyées, agrégées, analysées et envoyées à une interface utilisateur pour que les gens puissent les visualiser (ou vers toute autre cible).
Le réseau de spouts et de bolts est appelé une topologie, et les données circulent sous la forme de tuples (liste de valeurs pouvant avoir différents types).
 _Source : [https://dzone.com/articles/apache-storm-architecture](https://dzone.com/articles/apache-storm-architecture*" rel="noopener" target="blank" title=")
_Source : [https://dzone.com/articles/apache-storm-architecture](https://dzone.com/articles/apache-storm-architecture*" rel="noopener" target="blank" title=")
Une chose importante à mentionner est la direction du trafic de données.
Conventionnellement, nous aurions un ou plusieurs spouts lisant les données d'une API, d'un système de mise en file d'attente, etc. Les données circulent ensuite dans un sens vers un ou plusieurs bolts qui peuvent les transmettre à d'autres bolts et ainsi de suite. Les bolts peuvent publier les données analysées vers une interface utilisateur ou vers un autre bolt.
Mais le trafic est presque toujours unidirectionnel, comme un graphe acyclique dirigé (DAG). Bien qu'il soit certainement possible de créer des cycles, il est peu probable que nous ayons besoin d'une topologie aussi compliquée.
L'installation d'une version de Storm implique plusieurs étapes, que vous êtes libre de suivre sur votre machine. Mais plus tard, j'utiliserai des conteneurs Docker pour un déploiement de cluster Storm, et les images prendront en charge la configuration de tout ce dont nous avons besoin.
Un peu de code
Bien que Storm offre un support pour d'autres langages, la plupart des topologies sont écrites en Java, car c'est l'option la plus efficace que nous ayons.
Un spout très basique, qui émet simplement des chiffres aléatoires, peut ressembler à ceci :
Et un bolt simple qui prend le flux de chiffres aléatoires et émet uniquement les chiffres pairs :
Un autre bolt simple qui recevra le flux filtré de EvenDigitBolt, et multipliera simplement chaque chiffre pair par 10 et l'émettra :
En les mettant ensemble pour former notre topologie :
Parallélisme dans les topologies Storm
Comprendre pleinement le parallélisme dans Storm peut être intimidant, du moins selon mon expérience. Une topologie nécessite au moins un processus pour fonctionner. Au sein de ce processus, nous pouvons paralléliser l'exécution de nos spouts et bolts en utilisant des threads.
Dans notre exemple, RandomDigitSpout lancera un seul thread, et les données émises par ce thread seront distribuées parmi deux threads de EvenDigitBolt.
Mais la manière dont cette distribution se produit, appelée stream grouping, peut être importante. Par exemple, vous pouvez avoir un flux d'enregistrements de température provenant de deux villes, où les tuples émis par le spout ressemblent à ceci :
// Nom de la ville, température, heure de l'enregistrement
("Atlanta", 94, "2018-05-11 23:14")("New York City", 75, "2018-05-11 23:15")("New York City", 76, "2018-05-11 23:16")("Atlanta", 96, "2018-05-11 23:15")("New York City", 77, "2018-05-11 23:17")("Atlanta", 95, "2018-05-11 23:16")("New York City", 76, "2018-05-11 23:18")
Supposons que nous attachons un seul bolt dont le travail est de calculer la moyenne de température changeante de chaque ville.
Si nous pouvons raisonnablement nous attendre à ce que, dans un intervalle de temps donné, nous obtenions environ un nombre égal de tuples des deux villes, il serait logique de dédier deux threads à notre bolt. Nous pouvons envoyer les données pour Atlanta à l'un d'eux et celles de New York à l'autre.
Un fields grouping servirait notre objectif, qui partitionne les données parmi les threads par la valeur du champ spécifié dans le regroupement :
// Les tuples avec le même nom de ville iront au même thread.builder.setBolt("avg-temp-bolt", new AvgTempBolt(), 2) .fieldsGrouping("temp-spout", new Fields("city_name"));
Et bien sûr, il existe d'autres types de regroupements également. Pour la plupart des cas, cependant, le regroupement n'a probablement pas beaucoup d'importance. Vous pouvez simplement mélanger les données et les distribuer parmi les threads de bolt de manière aléatoire (shuffle grouping).
Il y a maintenant un autre composant important à cela : le nombre de processus de travail que notre topologie exécutera.
Le nombre total de threads que nous avons spécifié sera ensuite divisé équitablement parmi les processus de travail. Donc, dans notre exemple de topologie de chiffres aléatoires, nous avions un thread de spout, deux threads de bolt de chiffres pairs, et quatre threads de bolt de multiplication par dix (ce qui donne sept au total).
Chacun des deux processus de travail serait responsable de l'exécution de deux threads de bolt de multiplication par dix, un thread de bolt de chiffres pairs, et l'un des processus exécutera le thread de spout.
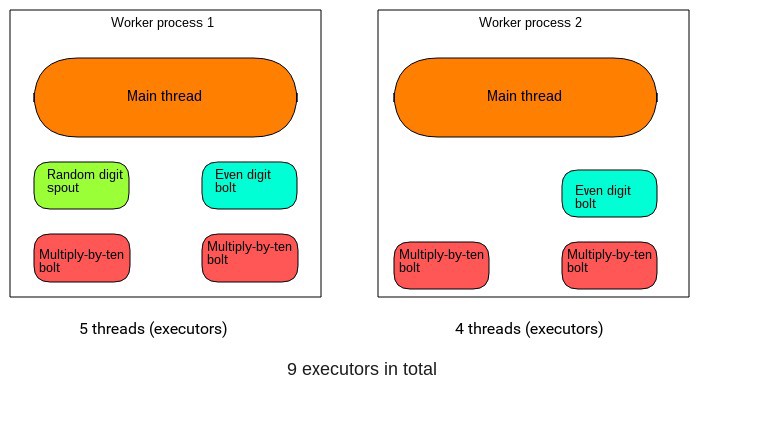
Bien sûr, les deux processus de travail auront leurs threads principaux, qui à leur tour lanceront les threads de spout et de bolt. Donc, au total, nous aurons neuf threads. Ceux-ci sont collectivement appelés executors.
Il est important de réaliser que si vous définissez un indice de parallélisme de spout supérieur à un (plusieurs executors), vous pouvez finir par émettre les mêmes données plusieurs fois.
Supposons que le spout lit le flux public de l'API Twitter et utilise deux executors. Cela signifie que les bolts recevant les données du spout obtiendront le même tweet deux fois. Ce n'est qu'après que le spout émet les tuples que le parallélisme des données entre en jeu. En d'autres termes, les tuples sont divisés parmi les bolts selon le regroupement de flux spécifié.
Exécuter plusieurs workers sur un seul nœud serait assez inutile. Cependant, plus tard, nous utiliserons un cluster distribué et multi-nœuds approprié et verrons comment les workers sont divisés sur différents nœuds.
Construction de notre topologie
Voici la structure de répertoire que je suggère :
yourproject/ pom.xml src/ jvm/ packagename/ RandomDigitSpout.java EvenDigitBolt.java MultiplyByTenBolt.java OurSimpleTopology.java
Maven est couramment utilisé pour construire des topologies Storm, et il nécessite un fichier pom.xml (le POM) qui définit divers détails de configuration, dépendances de projet, etc.. Entrer dans les détails du POM serait probablement excessif ici.
- Tout d'abord, nous exécuterons
mvn cleanà l'intérieur deyourprojectpour effacer tous les fichiers compilés que nous pourrions avoir, en veillant à compiler chaque module à partir de zéro. - Ensuite,
mvn packagepour compiler notre code et le packager dans un fichier JAR exécutable, à l'intérieur d'un dossiertargetnouvellement créé. Cela peut prendre plusieurs minutes la première fois, surtout si votre topologie a de nombreuses dépendances. - Pour soumettre notre topologie :
storm jar target/packagename-{version number}.jar packagename.OurSimpleTopology
Espérons qu'à présent l'écart entre le concept et le code dans Storm a été quelque peu comblé. Cependant, aucun déploiement sérieux de Storm ne sera une seule instance de topologie s'exécutant sur un seul serveur.
À quoi ressemble un cluster Storm
Pour tirer pleinement parti de la scalabilité et de la tolérance aux pannes de Storm, toute topologie de niveau production serait soumise à un cluster de machines.
Les distributions Storm sont installées sur le nœud principal (Nimbus) et tous les nœuds réplicas (Supervisors).
Le nœud principal exécute le démon Storm Nimbus et l'interface utilisateur Storm. Les nœuds réplicas exécutent les démons Storm Supervisor. Un démon Zookeeper sur un nœud séparé est utilisé pour la coordination entre le nœud principal et les nœuds réplicas.
Zookeeper, d'ailleurs, n'est utilisé que pour la gestion du cluster et jamais pour le passage de messages. Ce n'est pas comme si les spouts et les bolts s'envoyaient des données entre eux à travers lui ou quelque chose de ce genre. Le démon Nimbus trouve les Supervisors disponibles via ZooKeeper, auxquels les démons Supervisor s'enregistrent. Il effectue également d'autres tâches de gestion, dont certaines deviendront claires sous peu.
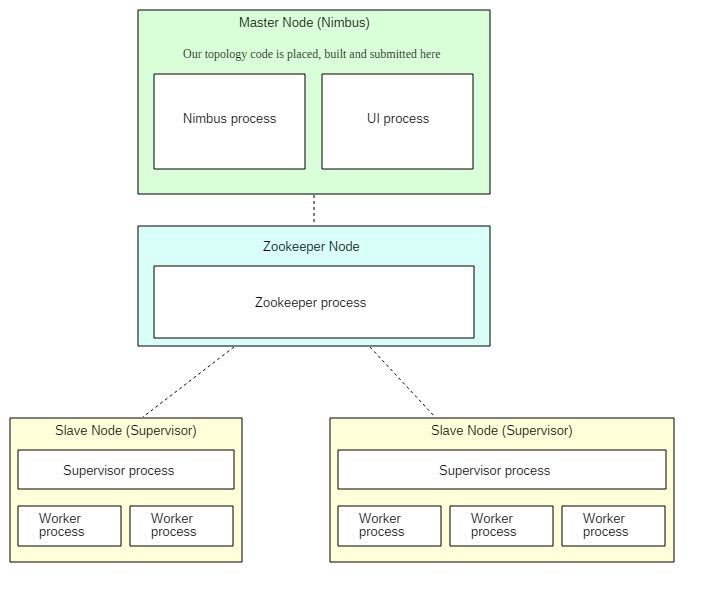
L'interface utilisateur Storm est une interface web utilisée pour gérer l'état de notre cluster. Nous y reviendrons plus tard.
Notre topologie est soumise au démon Nimbus sur le nœud principal, puis distribuée parmi les processus de travail s'exécutant sur les nœuds réplicas/superviseurs. Grâce à Zookeeper, peu importe le nombre de nœuds réplicas/superviseurs que vous exécutez initialement, car vous pouvez toujours en ajouter plus de manière transparente. Storm les intégrera automatiquement dans le cluster.
Chaque fois que nous démarrons un Supervisor, il alloue un certain nombre de processus de travail (que nous pouvons configurer). Ceux-ci peuvent ensuite être utilisés par la topologie soumise. Donc, dans l'image ci-dessus, il y a un total de cinq workers alloués.
Rappelez-vous cette ligne : conf.setNumWorkers(5)
Cela signifie que la topologie essaiera d'utiliser un total de cinq workers. Et puisque nos deux nœuds Supervisor ont un total de cinq workers alloués, chacun des cinq processus de travail alloués exécutera une instance de la topologie.
Si nous avions exécuté conf.setNumWorkers(4), alors un processus de travail serait resté inactif/non utilisé. Si le nombre de workers spécifiés était de six et que le nombre total de workers alloués était de cinq, alors en raison de la limitation, seuls cinq workers de topologie réels auraient été fonctionnels.
Avant de tout configurer avec Docker, il y a quelques points importants à garder à l'esprit concernant la tolérance aux pannes :
- Si un worker sur un nœud réplica meurt, le démon Supervisor le redémarrera. Si le redémarrage échoue à plusieurs reprises, le worker sera réaffecté à une autre machine.
- Si un nœud réplica entier meurt, sa part de travail sera donnée à un autre nœud superviseur/réplica.
- Si le Nimbus tombe en panne, les workers resteront inchangés. Cependant, jusqu'à ce que le Nimbus soit restauré, les workers ne seront pas réaffectés à d'autres nœuds réplicas si, par exemple, leur nœud plante.
- Le Nimbus et les Supervisors sont eux-mêmes sans état. Mais avec Zookeeper, certaines informations d'état sont stockées afin que les choses puissent reprendre là où elles s'étaient arrêtées si un nœud plante ou si un démon meurt de manière inattendue.
- Les démons Nimbus, Supervisor et Zookeeper sont tous fail-fast. Cela signifie qu'ils ne sont pas très tolérants aux erreurs inattendues et s'arrêteront s'ils en rencontrent une. Pour cette raison, ils doivent être exécutés sous supervision en utilisant un programme de surveillance qui les surveille constamment et les redémarre automatiquement s'ils plantent jamais. Supervisord est probablement l'option la plus populaire pour cela (à ne pas confondre avec le démon Supervisor de Storm).
Note : Dans la plupart des clusters Storm, le Nimbus lui-même n'est jamais déployé en tant qu'instance unique mais en tant que cluster. Si cette tolérance aux pannes n'est pas incorporée et que notre seul Nimbus tombe en panne, nous perdrons la capacité de soumettre de nouvelles topologies, de tuer gracieusement les topologies en cours d'exécution, de réaffecter le travail à d'autres nœuds Supervisor si l'un d'eux plante, et ainsi de suite.
Pour simplifier, notre cluster illustratif utilisera une instance unique. De même, Zookeeper est très souvent déployé en tant que cluster, mais nous n'utiliserons qu'un seul.
Dockerisation du cluster
Lancer des conteneurs individuels et tout ce qui va avec peut être fastidieux, donc je préfère utiliser Docker Compose.
Nous commencerons avec un nœud Zookeeper, un nœud Nimbus et un nœud Supervisor. Ils seront définis comme des services Compose, correspondant chacun à un conteneur au début.
Plus tard, j'utiliserai Compose scaling pour ajouter un autre nœud Supervisor (conteneur). Voici le code complet et la structure du projet :
zookeeper/ Dockerfilestorm-nimbus/ Dockerfile storm.yaml code/ pom.xml src/ jvm/ coincident_hashtags/ ExclamationTopology.java storm-supervisor/ Dockerfile storm.yamldocker-compose.yml
Et notre docker-compose.yml :
N'hésitez pas à explorer les Dockerfiles. Ils installent essentiellement les dépendances (Java 8, Storm, Maven, Zookeeper) sur les conteneurs pertinents.
Les fichiers storm.yaml remplacent certaines configurations par défaut pour les installations Storm. La ligne ADD storm.yaml /conf à l'intérieur des Dockerfiles Nimbus et Supervisor les place à l'intérieur des conteneurs où Storm peut les lire.
storm-nimbus/storm.yaml :
storm-supervisor/storm.yaml :
Ces options sont adéquates pour notre cluster. Si vous êtes curieux, vous pouvez consulter toutes les configurations par défaut ici.
Exécutez docker-compose up à la racine du projet.
Après que toutes les images ont été construites et que tous les services ont démarré, ouvrez un nouveau terminal, tapez docker ps et vous verrez quelque chose comme ceci :

Démarrage du Nimbus
Connectez-vous en SSH au conteneur Nimbus en utilisant son nom :
docker exec -it coincidenthashtagswithapachestorm_storm-nimbus_1 bash
Puis démarrez le démon Nimbus : storm nimbus

Démarrage de l'interface utilisateur Storm
De même, ouvrez un autre terminal, connectez-vous en SSH au Nimbus et lancez l'interface utilisateur avec storm ui :

Allez sur localhost:8080 dans votre navigateur et vous verrez un bon aperçu de notre cluster :
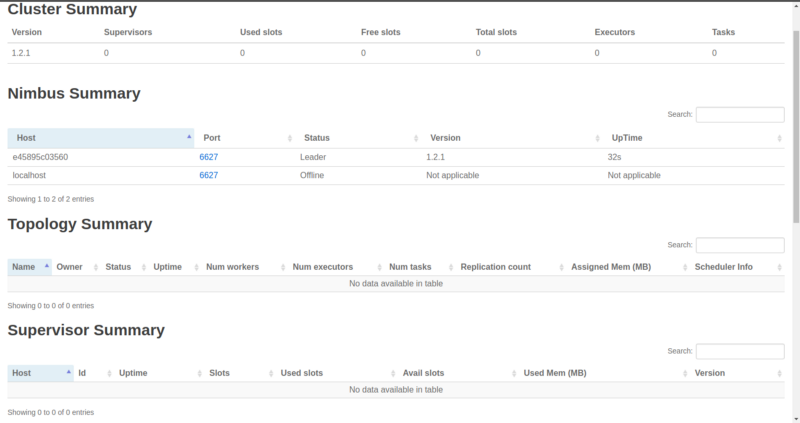
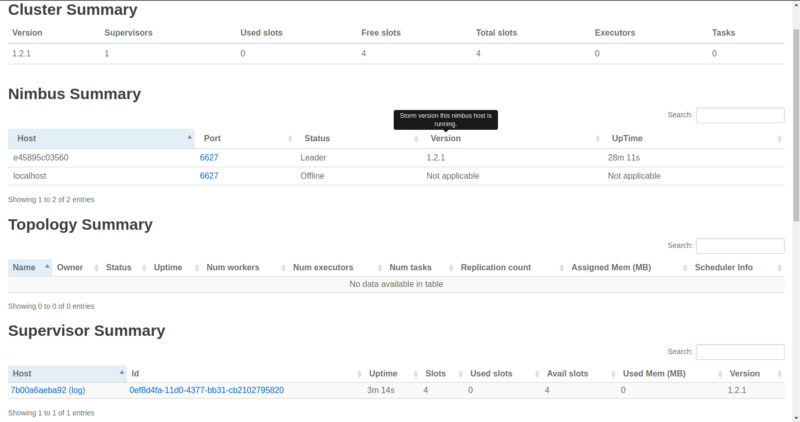
Les 'Free slots' dans le résumé du cluster indiquent combien de workers totaux (sur tous les nœuds Supervisor) sont disponibles et attendent qu'une topologie les utilise.
'Used slots' indique combien du total sont actuellement occupés par une topologie. Puisque nous n'avons pas encore lancé de Supervisors, ils sont tous les deux à zéro. Nous en viendrons aux Executors et Tasks plus tard. De plus, comme nous pouvons le voir, aucune topologie n'a encore été soumise.
Démarrage d'un nœud Supervisor
Connectez-vous en SSH au conteneur Supervisor et lancez le démon Supervisor :
docker exec -it coincidenthashtagswithapachestorm_storm-supervisor_1 bashstorm supervisor

Maintenant, allons rafraîchir notre interface utilisateur :
Note : Tout changement dans notre cluster peut prendre quelques secondes pour se refléter dans l'interface utilisateur.
Nous avons un nouveau Supervisor en cours d'exécution qui vient avec quatre workers alloués. Ces quatre workers sont le résultat de la spécification de quatre ports dans notre storm.yaml pour le nœud Supervisor. Bien sûr, ils sont tous libres (quatre slots libres).
Soumettons une topologie au Nimbus et mettons-les au travail.
Soumission d'une topologie au Nimbus
Connectez-vous en SSH au Nimbus sur un nouveau terminal. J'ai écrit le Dockerfile de sorte que nous atterrissions dans notre répertoire de travail (landing) /theproject. À l'intérieur de celui-ci se trouve code, où réside notre topologie.
Notre topologie est assez simple. Elle utilise un spout qui génère des mots aléatoires et un bolt qui ajoute simplement trois points d'exclamation (!!!) aux mots. Deux de ces bolts sont ajoutés dos à dos, et ainsi à la fin du flux nous obtiendrons des mots avec six points d'exclamation. Elle spécifie également qu'elle a besoin de trois workers ([conf.setNumWorkers(3)](https://github.com/UsamaAshraf/coincident-hashtags-with-apache-storm/blob/exclamation/storm-nimbus/code/src/jvm/coincident_hashtags/ExclamationTopology.java#L76)).
Exécutez ces commandes :
cd codemvn cleanmvn packagestorm jar target/coincident-hashtags-1.2.1.jar coincident_hashtags.ExclamationTopology
Après que la topologie a été soumise avec succès, rafraîchissez l'interface utilisateur :
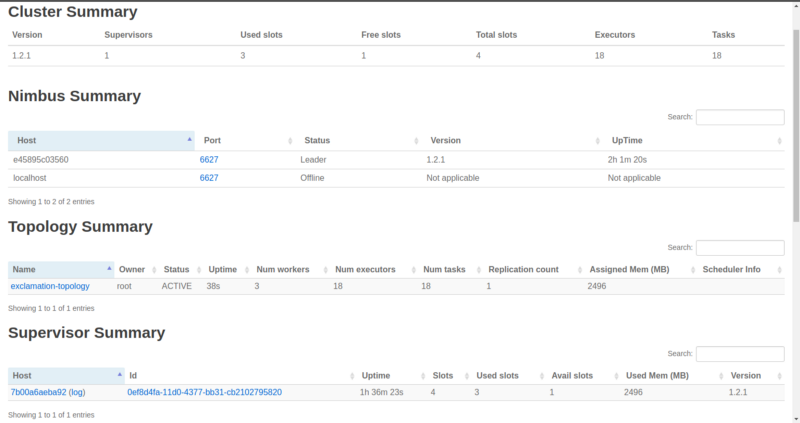
Dès que nous avons soumis la topologie, Zookeeper a été notifié. Zookeeper a à son tour notifié le Supervisor de télécharger le code depuis le Nimbus. Nous voyons maintenant notre topologie avec ses trois workers occupés, laissant un seul libre.
Et dix threads de spout de mots + trois threads de bolt exclaim1 + deux threads de bolt exclaim + les trois threads principaux des workers = un total de 18 executors.
Et vous avez peut-être remarqué quelque chose de nouveau : les tâches.
Qu'est-ce que les tâches ?
Les tâches sont un autre concept du parallélisme dans Storm. Mais ne vous inquiétez pas, une tâche est simplement une instance d'un spout ou d'un bolt qu'un executor utilise. Ce sont elles qui effectuent réellement le traitement.
Par défaut, le nombre de tâches est égal au nombre d'executors. Dans de rares cas, vous pourriez avoir besoin que chaque executor instancie plus de tâches.
// Chacun des deux executors (threads) de ce bolt instanciera// deux objets de ce bolt (total 4 objets/tasks de bolt).builder.setBolt("even-digit-bolt", new EvenDigitBolt(), 2) .setNumTasks(4) .shuffleGrouping("random-digit-spout");
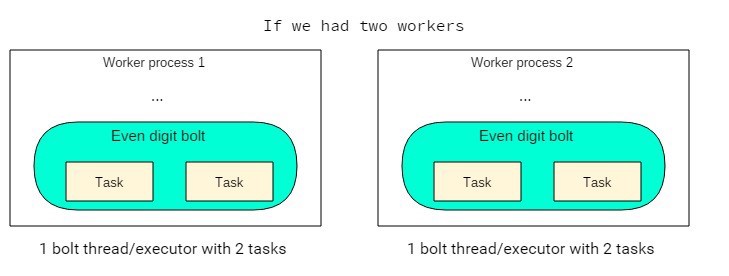
C'est une lacune de ma part, mais je ne peux pas penser à un bon cas d'utilisation où nous aurions besoin de plusieurs tâches par executor.
Peut-être si nous ajoutions un peu de parallélisme nous-mêmes, comme en créant un nouveau thread dans le bolt pour gérer une tâche longue, alors le thread principal de l'executor ne bloquera pas et pourra continuer à traiter en utilisant l'autre bolt.
Cependant, cela peut rendre notre topologie difficile à comprendre. Si quelqu'un connaît des scénarios où le gain de performance de plusieurs tâches l'emporte sur la complexité ajoutée, veuillez poster un commentaire.
En tout cas, revenons de cette légère digression, voyons un aperçu de notre topologie. Cliquez sur le nom sous Topology Summary et faites défiler vers le bas jusqu'à Worker Resources :
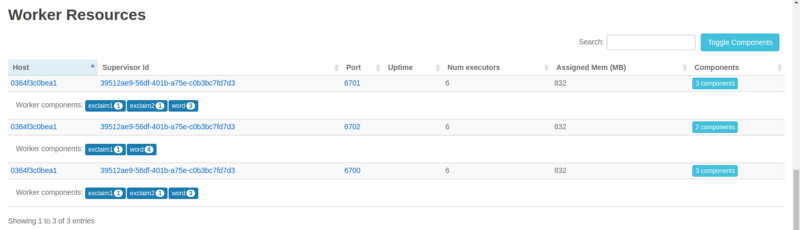
Nous pouvons clairement voir la division de nos executors (threads) parmi les trois workers. Et bien sûr, les trois workers sont sur le même nœud Supervisor unique que nous exécutons.
Maintenant, disons que nous voulons faire évoluer notre système !
Ajouter un autre Supervisor
À partir de la racine du projet, ajoutons un autre nœud/conteneur Supervisor :
docker-compose scale storm-supervisor=2
Connectez-vous en SSH au nouveau conteneur :
docker exec -it coincidenthashtagswithapachestorm_storm-supervisor_2 bash
Et lancez : storm supervisor
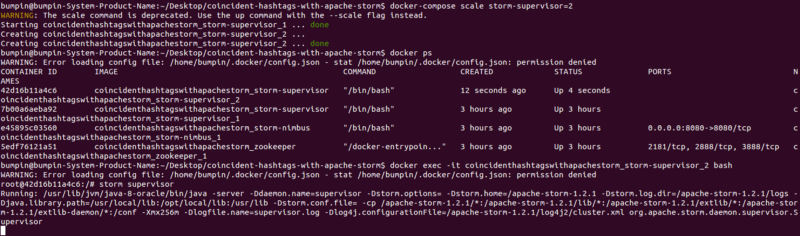
Si vous rafraîchissez l'interface utilisateur, vous verrez que nous avons ajouté avec succès un autre Supervisor et quatre workers supplémentaires (total de huit workers/slots). Pour vraiment tirer parti du nouveau Supervisor, augmentons le nombre de workers de la topologie.
- Tout d'abord, tuez celle en cours d'exécution :
storm kill exclamation-topology - Changez cette ligne en :
conf.setNumWorkers(6) - Changez le numéro de version du projet dans votre
pom.xml. Essayez d'utiliser un schéma approprié, comme la version sémantique. Je vais simplement rester avec 1.2.1. - Reconstruisez la topologie :
mvn package - Resoumettez-la :
storm jar target/coincident-hashtags-1.2.1.jar coincident_hashtags.ExclamationTopology
Rechargez l'interface utilisateur :
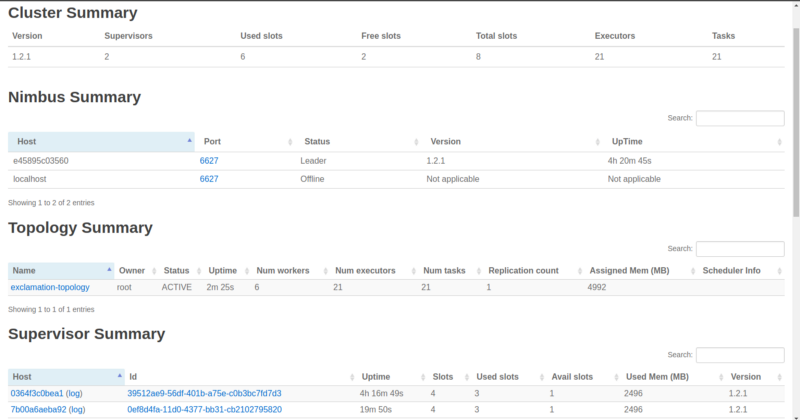
Vous pouvez maintenant voir le nouveau Supervisor et les six workers occupés sur un total de huit disponibles.
Il est également important de noter que les six occupés ont été divisés équitablement entre les deux Supervisors. Encore une fois, cliquez sur le nom de la topologie et faites défiler vers le bas.
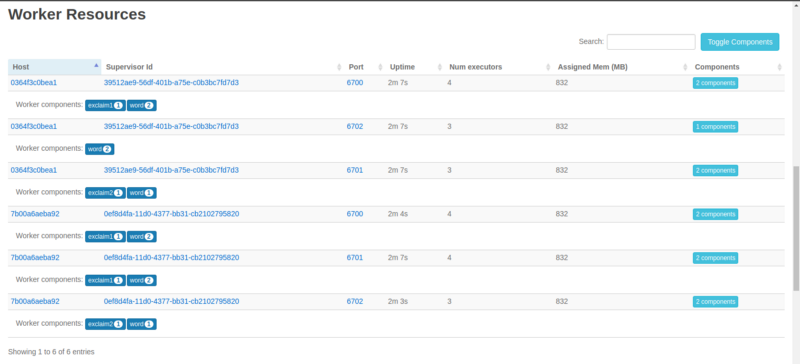
Nous voyons deux ID de Supervisor uniques, tous deux s'exécutant sur différents nœuds, et tous nos executors assez également divisés entre eux. C'est génial.
Mais Storm offre une autre manière astucieuse de le faire pendant que la topologie est en cours d'exécution — le rééquilibrage.
Sur le Nimbus, nous exécuterions :
storm rebalance exclamation-topology -n 6
Ou pour changer le nombre d'executors pour un composant particulier :
storm rebalance exclamation-topology -e even-digit-bolt=3
Traitement fiable des messages
Une question que nous n'avons pas abordée est de savoir ce qui se passe si un bolt échoue à traiter un tuple.
Storm nous fournit un mécanisme par lequel le spout d'origine (plus précisément, la tâche) peut rejouer le tuple échoué. Cette garantie de traitement ne se produit pas toute seule. C'est un choix de conception conscient, et cela ajoute de la latence.
Les spouts envoient des tuples aux bolts, qui émettent des tuples dérivés des tuples d'entrée vers d'autres bolts et ainsi de suite. Ce tuple original unique déclenche un arbre entier de tuples.
Si un tuple enfant, pour ainsi dire, du tuple original échoue, alors toute mesure corrective (retours en arrière, etc.) devra probablement être prise à plusieurs bolts. Cela pourrait devenir assez compliqué, et donc ce que fait Storm, c'est qu'il permet au tuple original d'être émis à nouveau directement à partir de la source (le spout).
Par conséquent, toute opération effectuée par les bolts qui est une fonction des tuples entrants doit être idempotente.
Un tuple est considéré comme "complètement traité" lorsque chaque tuple de son arbre a été traité, et chaque tuple doit être explicitement reconnu par les bolts.
Cependant, ce n'est pas tout. Il y a une autre chose à faire explicitement : maintenir un lien entre le tuple original et ses tuples enfants. Storm pourra alors retracer l'origine des tuples enfants et ainsi pouvoir rejouer le tuple original. Cela s'appelle l'ancrage. Et cela a été fait dans notre bolt d'exclamation :
// ExclamationBolt
// 'tuple' est le tuple original reçu du spout de mots de test.// Il a été ancré au/avec le tuple sortant._collector.emit(tuple, new Values(exclamatedWord.toString()));
// Reconnaître explicitement que le tuple a été traité._collector.ack(tuple);
L'appel ack entraînera l'appel de la méthode ack sur le spout, si elle a été implémentée.
Donc, disons que vous lisez les données de tuple à partir d'une file d'attente et que vous ne pouvez les retirer de la file d'attente que si le tuple a été complètement traité. La méthode ack est l'endroit où vous feriez cela.
Vous pouvez également émettre des tuples sans ancrage :
_collector.emit(new Values(exclamatedWord.toString()))
et renoncer à la fiabilité.
Un tuple peut échouer de deux manières :
- Un bolt meurt et un tuple expire. Ou, il expire pour une autre raison. Le délai d'expiration est de 30 secondes par défaut et peut être modifié en utilisant
config.put(Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS, 60) - La méthode
failest explicitement appelée sur le tuple dans un bolt :_collector.fail(tuple). Vous pouvez faire cela en cas d'exception.
Dans ces deux cas, la méthode fail sur le spout sera appelée, si elle est implémentée. Et si nous voulons que le tuple soit rejoué, cela devrait être fait explicitement dans la méthode fail en appelant emit, tout comme dans nextTuple(). Lors du suivi des tuples, chacun doit être ack ou fail. Sinon, la topologie finira par manquer de mémoire.
Il est également important de savoir que vous devez faire tout cela vous-même lors de l'écriture de spouts et de bolts personnalisés. Mais le cœur de Storm peut aider. Par exemple, un bolt implémentant BaseBasicBolt fait l'acking automatiquement. Ou les spouts intégrés pour les sources de données populaires comme Kafka prennent en charge la logique de mise en file d'attente et de relecture après l'accusé de réception et l'échec.
Dernières remarques
Concevoir une topologie ou un cluster Storm consiste toujours à ajuster les différents paramètres que nous avons et à trouver où le résultat semble optimal.
Il y a quelques points qui aideront dans ce processus, comme l'utilisation d'un fichier de configuration pour lire les indices de parallélisme, le nombre de workers, etc., afin de ne pas avoir à éditer et recompiler votre code à plusieurs reprises.
Définissez vos bolts de manière logique, un par tâche indivisible, et gardez-les légers et efficaces. De même, les méthodes nextTuple() de vos spouts doivent être optimisées.
Utilisez efficacement l'interface utilisateur Storm. Par défaut, elle ne nous montre pas l'image complète, seulement 5 % du total des tuples émis. Pour les surveiller tous, utilisez config.setStatsSampleRate(1.0d).
Surveillez les valeurs Acks et Latency pour les bolts et topologies individuels via l'interface utilisateur. C'est ce que vous voulez examiner lors de l'ajustement des paramètres.