


Article original : Data Analysis with Python – How I Analyzed My Empire State Building Run-Up Performance
Une course d'escaliers (tower running) est une course où l'on grimpe les marches d'un bâtiment. Ces événements ont lieu partout dans le monde. J'ai eu la chance de participer à l'Empire State Run Up à New York, édition 2023.
L'Empire State Building Run-Up (ESBRU)—la première et la plus célèbre course d'escaliers au monde—met au défi des coureurs venus de près ou de loin de gravir ses célèbres 86 étages—soit 1 576 marches.
Alors que les visiteurs peuvent atteindre l'observatoire du bâtiment via l'ascenseur en moins d'une minute, les coureurs les plus rapides ont parcouru les 86 étages à pied en environ 10 minutes.
Les leaders du sport professionnel de tower running convergent vers l'Empire State Building pour ce que certains considèrent comme le test d'endurance ultime.
J'ai eu de la chance et j'ai réussi à participer à cette course. Quelques jours après avoir terminé la course, j'ai réalisé que je voulais en savoir plus sur ma performance et ce que j'aurais pu faire pour l'améliorer.
Naturellement, je suis allé sur le site de l'organisateur de la course et j'ai commencé à regarder les chiffres. C'était lent et fastidieux, et cela a soulevé d'autres problèmes :
Obtenir les données pour une analyse hors ligne est difficile. Vous pouvez voir vos résultats et ceux des autres pour comparer, mais j'ai trouvé que les outils n'offraient pas d'option pour télécharger les données brutes et qu'ils étaient maladroits à utiliser.
La plupart des outils disponibles pour analyser les résultats de course sont payants ou ne s'appliquent pas à ce type de course. Savoir à quoi s'attendre réduit votre anxiété, vous permet de mieux vous entraîner et de garder des attentes réalistes.
À présent, vous avez probablement deviné que l'on peut résoudre les problèmes de récupération de données et d'analyse post-course en utilisant des outils Open Source à bas coût. Cela vous permet également d'appliquer différentes techniques pour en apprendre davantage sur la course et, selon la qualité des données, de faire des prédictions de performance.
C'est un article très personnel pour moi. Je partagerai mes résultats de course et vous donnerai mon avis biaisé sur l'événement. 😁
Table des matières
Comment j'ai fini par courir jusqu'au sommet de l'Empire State Building
Beaucoup d'entre nous ont déjà couru une course classique à un moment donné de leur vie – il existe de nombreuses distances comme le 5K, le 10K, le Semi-marathon et le Marathon. Mais il n'y a aucun moyen de comparer comment vous allez performer en montant les escaliers jusqu'au sommet de l'un des bâtiments les plus célèbres au monde.
Si vous vous êtes déjà trouvé au pied des gratte-ciel de New York et que vous avez levé les yeux, vous voyez l'idée. Imaginez-vous en train de monter les escaliers, tout en haut, sans vous arrêter.
Être accepté est difficile car, contrairement à une course comme le Marathon de New York, l'Empire State Building ne peut accueillir qu'environ 500 coureurs (ou devrais-je dire grimpeurs ?).
Ajoutez à cela le fait que la demande de participation est élevée, et vous comprendrez que vos chances d'entrer via la loterie sont assez minces (j'ai lu quelque part qu'il n'y a que 50 places de loterie pour plus de 5 000 candidats).
Vous imaginez ma surprise quand j'ai reçu un e-mail disant que j'avais été sélectionné pour participer après avoir essayé pendant 4 années consécutives.
J'ai paniqué. Vous êtes-vous déjà tenu à la base de l'Empire State en regardant vers le haut ? Certains jours, quand c'est nuageux, on ne voit même pas le sommet du bâtiment.
Je n'étais pas sans préparation. Mais j'ai dû ajuster ma routine d'entraînement pour être prêt pour ce défi avec une petite fenêtre de deux mois, et aucune expérience en tower running.
Le jour de la course est arrivé et voici comment cela s'est passé pour moi :
C'était dur. Je savais que je devais gérer mon allure, sinon la course se serait terminée pour moi au 20ème étage au lieu du 86ème. Il faut se concentrer sur une mentalité de "continuer d'avancer", peu importe la fatigue. Et puis c'est fini, tout simplement.
On ne sprinte pas, on monte 2 marches à la fois à un rythme régulier, et on utilise les mains courantes pour soulager le poids sur les jambes.
Pas besoin de faire une recharge massive en glucides ou de trop s'hydrater. Si vous vous débrouillez bien, vous aurez terminé en environ 30 minutes.
Personne ne pousse personne. Au moins pour les coureurs non-élites comme moi, j'ai été seul pendant la majeure partie de la course.
J'ai été dépassé et j'ai dépassé beaucoup de gens qui avaient oublié la règle de "gérer son allure". Si vous sprintez, vous serez grillé avant le 25ème étage, c'est certain.
Je me suis éclaté et j'ai ressenti une grande satisfaction d'avoir coché cette course sur ma liste de choses à faire, de la même manière que je me suis senti après avoir couru le Marathon de NYC.
Il était maintenant temps de faire une analyse post-course en utilisant plusieurs de mes outils Open Source préférés, que j'expliquerai dans la section suivante.
Ce dont vous avez besoin pour suivre ce tutoriel
Comme pour la course, la plupart des défis pour écrire cette application étaient mentaux. Il suffit de diviser le problème principal en plus petits morceaux, puis de s'attaquer à chaque morceau un à la fois :
Récupérer les données par scraping du site web (très peu de sites vous permettent d'exporter les résultats de course en CSV).
Nettoyer les données, les normaliser et les rendre prêtes pour un traitement automatique.
Poser des questions. Puis traduire ces questions en code et en tests, idéalement en utilisant les statistiques pour obtenir des réponses fiables.
Présenter les résultats. Une UI (Textuelle ou Graphique) fera des merveilles grâce à sa faible consommation, mais les graphiques sont également très parlants.
Vous devriez avoir une certaine expérience dans un langage de programmation pour tirer le meilleur parti de cet article. Mon code est écrit en Python (vous aurez besoin de la version 3.8+) et s'exécute sous Linux (j'ai utilisé la distribution Fedora 37).
En résumé, je veux montrer qu'il est possible de faire tout ce qui précède avec des technologies Open Source. Vous pourrez ensuite réutiliser ces connaissances pour d'autres projets, pas seulement pour l'analyse de courses d'escaliers. 😅
Je vous recommande vivement de récupérer le code source (il est Open Source !). Mettez les mains dans le cambouis, cassez les scripts et amusez-vous. Vous aurez besoin de Git pour cloner le dépôt :
git clone https://github.com/josevnz/tutorials.git
cd tutorials/docs/EmpireStateRunUp/
python -m ~/virtualenv/EmpireStateRunUp
. ~/virtualenv/EmpireStateRunUp/bin/activate
pip install --upgrade pip
pip install --upgrade build
pip install --upgrade wheel
pip install --editable .
Ou si vous voulez simplement exécuter le code tout en lisant ce tutoriel (en utilisant ma dernière version de Pypi) :
python -m ~/virtualenv/EmpireStateRunUp
. ~/virtualenv/EmpireStateRunUp/bin/activate
pip install --upgrade EmpireStateRunUp
Nous pouvons maintenant passer à l'étape suivante : obtenir les données.
Comment obtenir les données via le Web Scraping
Le site des résultats de la course n'a pas de fonction d'exportation, et je n'ai jamais eu de réponse de leur équipe de support pour savoir s'il existait un autre moyen d'obtenir les données de la course. La seule alternative restante était donc de faire du web scraping.
Le site web est assez basique et permet uniquement de faire défiler chaque enregistrement, j'ai donc décidé de faire du web scraping pour obtenir les résultats dans un format que je pourrais utiliser plus tard pour l'analyse de données.
Les règles du web scraping
Il y a 3 règles très simples :
Règle n°1 : Ne le faites pas. Le flux de données change, et votre scraper cassera à la minute où vous aurez fini de récupérer les données. Cela demandera du temps et des efforts. Beaucoup.
Règle n°2 : Relisez la règle n°1. Si vous ne pouvez pas obtenir les données dans un autre format, passez à la règle n°3.
Règle n°3 : Choisissez un bon Framework pour automatiser ce que vous pouvez et préparez-vous à un nettoyage de données intensif (également connu sous le nom de "donnez-moi de la patience pour les choses que je ne peux pas contrôler, comme le HTML et le CSS mal faits").
J'ai décidé d'utiliser Selenium Web Driver car il appelle un vrai navigateur, comme Firefox, pour naviguer sur le site. Selenium vous permet d'automatiser les actions du navigateur tout en obtenant le même HTML rendu que vous voyez lorsque vous naviguez sur le site.
Selenium est un outil complexe et vous demandera de passer du temps à expérimenter ce qui fonctionne et ce qui ne fonctionne pas. Voici ci-dessous un script simple que j'ai écrit pour obtenir tous les noms des coureurs et les liens de détails de la course en une seule fois :
import re
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.firefox.webdriver import WebDriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions
# AthLinks est assez aimable pour publier les résultats de la course et leur interface est très conviviale pour les humains. Pas autant pour l'analyse par machine.
RESULTS = "https://www.athlinks.com/event/382111/results/Event/1062909/Course/2407855/Results"
LINKS = {}
def print_links(web_driver: WebDriver, page: int) -> None:
for a in web_driver.find_elements(By.TAG_NAME, "a"):
href = a.get_attribute('href')
if re.search('Bib', href):
name = a.text.strip().title()
print(f"Page={page}, {name}={href.strip()}")
LINKS[name] = href.strip()
def click(level: int) -> None:
button = WebDriverWait(driver, 20).until(
expected_conditions.element_to_be_clickable((By.CSS_SELECTOR, f"div:nth-child({level}) > button")))
driver.execute_script("arguments[0].click();", button)
sleep(2.5)
options = Options()
options.add_argument("--headless")
driver = webdriver.Firefox(options=options)
driver.get(RESULTS)
sleep(2.5)
print_links(driver, 1)
click(6)
print_links(driver, 2)
click(7)
print_links(driver, 3)
click(7)
print_links(driver, 4)
click(9)
print_links(driver, 5)
click(9)
print_links(driver, 6)
click(7)
print_links(driver, 7)
click(7)
print_links(driver, 8)
print(len(LINKS))
Le code ci-dessus est difficilement réutilisable, mais il fait le travail en effectuant les opérations suivantes :
Récupère la page web principale avec la méthode
driver.get(...).Récupère ensuite les balises
<a href, et attend un peu pour laisser le temps au HTML de s'afficher.Trouve et clique sur le bouton
>(page suivante).Répète ces étapes un total de 8 fois, car c'est le nombre de pages de résultats disponibles (chaque page contient 50 coureurs).
Pour obtenir les résultats complets de la course, j'ai écrit le code scraper.py. Le code s'occupe de la navigation sur plusieurs pages et de l'extraction des données. Démonstration ci-dessous :
(EmpireStateRunUp) [josevnz@dmaf5 EmpireStateRunUp]$ esru_scraper /home/josevnz/temp/raw_data.csv
2023-12-30 14:05:00,987 Saving results to /home/josevnz/temp/raw_data.csv
2023-12-30 14:05:53,091 Got 377 racer results
2023-12-30 14:05:53,091 Processing BIB: 19, will fetch: https://www.athlinks.com/event/382111/results/Event/1062909/Course/2407855/Bib/19
2023-12-30 14:06:02,207 Wrote: name=Wai Ching Soh, position=1, {'name': 'Wai Ching Soh', 'url': 'https://www.athlinks.com/event/382111/results/Event/1062909/Course/2407855/Bib/19', 'overall position': '1', 'gender': 'M', 'age': 29, 'city': 'Kuala Lumpur', 'state': '-', 'country': 'MYS', 'bib': 19, '20th floor position': '1', '20th floor gender position': '1', '20th floor division position': '1', '20th floor pace': '42:30', '20th floor time': '1:42', '65th floor position': '1', '65th floor gender position': '1', '65th floor division position': '1', '65th floor pace': '54:03', '65th floor time': '7:34', 'gender position': '1', 'division position': '1', 'pace': '53:00', 'time': '10:36', 'level': 'Full Course'}
...
Il n'effectue qu'une manipulation minimale des données provenant de la page web. Le but de ce code est simplement de récupérer les données aussi vite que possible avant que le formatage ne change.
Les données ne peuvent pas encore être utilisées telles quelles – elles ont besoin d'être nettoyées. Et c'est la prochaine étape de cet article.
Comment nettoyer les données
L'obtention des données n'est que la première bataille de bien d'autres à venir. Vous remarquerez des incohérences dans les données et des valeurs manquantes. Pour que vos résultats numériques soient corrects, vous devez faire des suppositions.
Heureusement pour moi, l'ensemble de données est très petit (plus de 375 enregistrements, un pour chaque coureur), j'ai donc pu établir quelques règles pour mettre de l'ordre dans le fichier de données que j'allais utiliser pour mon analyse.
J'ai également complété mes données avec un autre ensemble de données contenant les codes de pays à 3 chiffres ainsi que d'autres détails, pour une présentation plus agréable.
La méthode data_normalizer.raw_read(raw_file: Path) -> Iterable[Dict[str, Any]] effectue le gros du travail de correction des incohérences avant de sauvegarder au format CSV.
Il n'y a pas de règles strictes ici, car le nettoyage est fortement lié à l'ensemble de données. Par exemple, pour déterminer à quelle vague (wave) chaque coureur a été assigné, j'ai dû faire quelques suppositions basées sur ce que j'ai vu le jour de la course.
Laissez-moi vous montrer ce que je veux dire avec du code :
import datetime
from enum import Enum
from typing import Dict
"""
Les coureurs ont commencé par vagues, mais pour une analyse de base, nous supposerons que tous les coureurs ont pu courir
en même temps.
"""
BASE_RACE_DATETIME = datetime.datetime(
year=2023,
month=9,
day=4,
hour=20,
minute=0,
second=0,
microsecond=0
)
class Waves(Enum):
"""
22 Élite hommes
17 Élite femmes
Il y a quelques vides, donc soit certains coureurs ne se sont pas présentés, soit il y avait de la capacité excédentaire.
https://runsignup.com/Race/EmpireStateBuildingRunUp/Page-4
https://runsignup.com/Race/EmpireStateBuildingRunUp/Page-5
J'ai deviné qui allait dans quelle catégorie, en me basant sur les numéros de dossard (BIB) que j'ai vus ce jour-là
"""
ELITE_MEN = ["Elite Men", [1, 25], BASE_RACE_DATETIME]
ELITE_WOMEN = ["Elite Women", [26, 49], BASE_RACE_DATETIME + datetime.timedelta(minutes=2)]
PURPLE = ["Specialty", [100, 199], BASE_RACE_DATETIME + datetime.timedelta(minutes=10)]
GREEN = ["Sponsors", [200, 299], BASE_RACE_DATETIME + datetime.timedelta(minutes=20)]
"""
La date à laquelle les gens ont postulé pour la loterie a déterminé les couleurs. Supposons que
Ouverture loterie générale : 17/07 9H - 28/07 23H59
Date du tirage au sort : 01/08
"""
ORANGE = ["Tenants", [300, 399], BASE_RACE_DATETIME + datetime.timedelta(minutes=30)]
GREY = ["General 1", [400, 499], BASE_RACE_DATETIME + datetime.timedelta(minutes=40)]
GOLD = ["General 2", [500, 599], BASE_RACE_DATETIME + datetime.timedelta(minutes=50)]
BLACK = ["General 3", [600, 699], BASE_RACE_DATETIME + datetime.timedelta(minutes=60)]
"""
Intéressé uniquement par les personnes ayant terminé les 86 étages. C'est donc soit le parcours complet (full course), soit un abandon (dnf)
"""
class Level(Enum):
FULL = "Full Course"
DNF = "DNF"
# Les champs sont triés par intérêt
class RaceFields(Enum):
BIB = "bib"
NAME = "name"
OVERALL_POSITION = "overall position"
TIME = "time"
GENDER = "gender"
GENDER_POSITION = "gender position"
AGE = "age"
DIVISION_POSITION = "division position"
COUNTRY = "country"
STATE = "state"
CITY = "city"
PACE = "pace"
TWENTY_FLOOR_POSITION = "20th floor position"
TWENTY_FLOOR_GENDER_POSITION = "20th floor gender position"
TWENTY_FLOOR_DIVISION_POSITION = "20th floor division position"
TWENTY_FLOOR_PACE = '20th floor pace'
TWENTY_FLOOR_TIME = '20th floor time'
SIXTY_FLOOR_POSITION = "65th floor position"
SIXTY_FIVE_FLOOR_GENDER_POSITION = "65th floor gender position"
SIXTY_FIVE_FLOOR_DIVISION_POSITION = "65th floor division position"
SIXTY_FIVE_FLOOR_PACE = '65th floor pace'
SIXTY_FIVE_FLOOR_TIME = '65th floor time'
WAVE = "wave"
LEVEL = "level"
URL = "url"
FIELD_NAMES = [x.value for x in RaceFields if x != RaceFields.URL]
FIELD_NAMES_FOR_SCRAPING = [x.value for x in RaceFields]
FIELD_NAMES_AND_POS: Dict[RaceFields, int] = {}
pos = 0
for field in RaceFields:
FIELD_NAMES_AND_POS[field] = pos
pos += 1
def get_wave_from_bib(bib: int) -> Waves:
for wave in Waves:
(lower, upper) = wave.value[1]
if lower <= bib <= upper:
return wave
return Waves.BLACK
def get_description_for_wave(wave: Waves) -> str:
return wave.value[0]
J'ai utilisé des enums pour clarifier le type de données sur lesquelles je travaillais, en particulier pour les noms des champs. La cohérence est la clé.
En ce qui concerne le nettoyage des données, il y a eu quelques corrections évidentes que j'ai dû appliquer, comme :
Le format des temps comme l'allure (pace), le temps de course, etc., afin qu'ils puissent être analysés plus tard.
Mettre certaines valeurs en majuscules pour les rendre plus faciles à lire.
La conversion précoce des chaînes en entiers pour des valeurs comme l'âge, la position, etc. En cas d'échec, assigner 'not a number' (nan).
Nous n'avons pas encore fini de préparer les données. Une fonction simple s'occupe de cette étape à l'intérieur du module data :
# Imports et déclarations d'Enum omis car ils ont été montrés précédemment.
# Consultez le code source pour 'data.py' pour plus de détails
def raw_csv_read(raw_file: Path) -> Iterable[Dict[str, Any]]:
record = {}
with open(raw_file, 'r') as raw_csv_file:
reader = csv.DictReader(raw_csv_file)
row: Dict[str, Any]
for row in reader:
try:
csv_field: str
for csv_field in FIELD_NAMES_FOR_SCRAPING:
column_val = row[csv_field].strip()
if csv_field == RaceFields.BIB.value:
bib = int(column_val)
record[csv_field] = bib
elif csv_field in [ RaceFields.GENDER_POSITION.value, RaceFields.DIVISION_POSITION.value, RaceFields.OVERALL_POSITION.value, RaceFields.TWENTY_FLOOR_POSITION.value,
RaceFields.TWENTY_FLOOR_DIVISION_POSITION.value, RaceFields.TWENTY_FLOOR_GENDER_POSITION.value, RaceFields.SIXTY_FLOOR_POSITION.value, RaceFields.SIXTY_FIVE_FLOOR_DIVISION_POSITION.value,
RaceFields.SIXTY_FIVE_FLOOR_GENDER_POSITION.value, RaceFields.AGE.value ]:
try:
record[csv_field] = int(column_val)
except ValueError:
record[csv_field] = math.nan
elif csv_field == RaceFields.WAVE.value:
record[csv_field] = get_description_for_wave(get_wave_from_bib(bib)).upper()
elif csv_field in [RaceFields.GENDER.value, RaceFields.COUNTRY.value]:
record[csv_field] = column_val.upper()
elif csv_field in [RaceFields.CITY.value, RaceFields.STATE.value,
]:
record[csv_field] = column_val.capitalize()
elif csv_field in [RaceFields.SIXTY_FIVE_FLOOR_PACE.value, RaceFields.SIXTY_FIVE_FLOOR_TIME.value, RaceFields.TWENTY_FLOOR_PACE.value,
RaceFields.TWENTY_FLOOR_TIME.value, RaceFields.PACE.value, RaceFields.TIME.value ]:
parts = column_val.strip().split(':')
for idx in range(0, len(parts)):
if len(parts[idx]) == 1:
parts[idx] = f"0{parts[idx]}"
if len(parts) == 2:
parts.insert(0, "00")
record[csv_field] = ":".join(parts)
else:
record[csv_field] = column_val
if record[csv_field] in ['-', '--']:
record[csv_field] = ""
yield record
except IndexError:
raise
Le script esru_csv_cleaner est le résultat du premier effort de nettoyage, qui prend les données brutes capturées et écrit un fichier CSV avec quelques corrections importantes :
esru_csv_cleaner --rawfile /home/josevnz/temp/raw_data.csv /home/josevnz/tutorials/docs/EmpireStateRunUp/empirestaterunup/results-full-level-2023.csv
Maintenant que les données sont prêtes, nous pouvons procéder à leur chargement et poser quelques questions sur la course.
Comment analyser les données
Une fois que les données sont propres (ou aussi propres que possible), il est temps de passer à l'analyse des chiffres. Avant d'écrire plus de code, j'ai pris une feuille de papier et je me suis posé quelques questions sur la course :
Existe-t-il des groupes ou clusters intéressants pour l'âge, le temps de course, la vague et la participation par pays ?
Un histogramme pour l'Âge et le Pays serait intéressant à voir.
Décrire les données ! (médiane, percentiles, etc.)
Trouver les valeurs aberrantes. Est-il possible d'appliquer des Z-scores ici ?
J'ai décidé d'utiliser Python Pandas pour cette tâche. Ce Framework Open Source dispose d'un arsenal d'outils pour manipuler les données et calculer des statistiques. Il possède également de bons outils pour effectuer un nettoyage supplémentaire si nécessaire.
Alors, comment fonctionne Pandas ?
Cours accéléré sur Pandas
Je vous recommande vivement de consulter 10 minutes to pandas si vous n'êtes pas familier avec l'outil. Pour mon DataFrame, j'ai utilisé le BIB comme index car il est unique, et il n'a pas de valeur spéciale pour les fonctions d'agrégation – mais l'attribut 'id' est unique.
Il est important de noter qu'à ce stade également, j'ai dû normaliser les données, ce que j'expliquerai brièvement :
# Imports et déclarations d'Enum omis car ils ont été montrés précédemment.
# Consultez le code source pour 'data.py' pour plus de détails
def load_data(data_file: Path = None, remove_dnf: bool = True) -> DataFrame:
"""
* Le code supprime par défaut les coureurs DNF pour éviter de fausser les résultats.
* Remplace les valeurs inconnues/nan par la médiane, pour faciliter l'analyse et éviter les distorsions
"""
if data_file:
def_file = data_file
else:
def_file = RACE_RESULTS_FULL_LEVEL
df = pandas.read_csv(
def_file
)
for time_field in [
RaceFields.PACE.value,
RaceFields.TIME.value,
RaceFields.TWENTY_FLOOR_PACE.value,
RaceFields.TWENTY_FLOOR_TIME.value,
RaceFields.SIXTY_FIVE_FLOOR_PACE.value,
RaceFields.SIXTY_FIVE_FLOOR_TIME.value
]:
try:
df[time_field] = pandas.to_timedelta(df[time_field])
except ValueError as ve:
raise ValueError(f'{time_field}={df[time_field]}', ve)
df['finishtimestamp'] = BASE_RACE_DATETIME + df[RaceFields.TIME.value]
if remove_dnf:
df.drop(df[df.level == 'DNF'].index, inplace=True)
# Normaliser l'Âge
median_age = df[RaceFields.AGE.value].median()
df[RaceFields.AGE.value].fillna(median_age, inplace=True)
df[RaceFields.AGE.value] = df[RaceFields.AGE.value].astype(int)
# Normaliser l'état et la ville
df.replace({RaceFields.STATE.value: {'-': ''}}, inplace=True)
df[RaceFields.STATE.value].fillna('', inplace=True)
df[RaceFields.CITY.value].fillna('', inplace=True)
# Normaliser la position globale, 3 niveaux
median_pos = df[RaceFields.OVERALL_POSITION.value].median()
df[RaceFields.OVERALL_POSITION.value].fillna(median_pos, inplace=True)
df[RaceFields.OVERALL_POSITION.value] = df[RaceFields.OVERALL_POSITION.value].astype(int)
median_pos = df[RaceFields.TWENTY_FLOOR_POSITION.value].median()
df[RaceFields.TWENTY_FLOOR_POSITION.value].fillna(median_pos, inplace=True)
df[RaceFields.TWENTY_FLOOR_POSITION.value] = df[RaceFields.TWENTY_FLOOR_POSITION.value].astype(int)
median_pos = df[RaceFields.SIXTY_FLOOR_POSITION.value].median()
df[RaceFields.SIXTY_FLOOR_POSITION.value].fillna(median_pos, inplace=True)
df[RaceFields.SIXTY_FLOOR_POSITION.value] = df[RaceFields.SIXTY_FLOOR_POSITION.value].astype(int)
# Normaliser la position par genre, 3 niveaux
median_gender_pos = df[RaceFields.GENDER_POSITION.value].median()
df[RaceFields.GENDER_POSITION.value].fillna(median_gender_pos, inplace=True)
df[RaceFields.GENDER_POSITION.value] = df[RaceFields.GENDER_POSITION.value].astype(int)
median_gender_pos = df[RaceFields.TWENTY_FLOOR_GENDER_POSITION.value].median()
df[RaceFields.TWENTY_FLOOR_GENDER_POSITION.value].fillna(median_gender_pos, inplace=True)
df[RaceFields.TWENTY_FLOOR_GENDER_POSITION.value] = df[RaceFields.TWENTY_FLOOR_GENDER_POSITION.value].astype(int)
median_gender_pos = df[RaceFields.SIXTY_FIVE_FLOOR_GENDER_POSITION.value].median()
df[RaceFields.SIXTY_FIVE_FLOOR_GENDER_POSITION.value].fillna(median_gender_pos, inplace=True)
df[RaceFields.SIXTY_FIVE_FLOOR_GENDER_POSITION.value] = df[
RaceFields.SIXTY_FIVE_FLOOR_GENDER_POSITION.value].astype(int)
# Normaliser l'âge / position par division, 3 niveaux
median_div_pos = df[RaceFields.DIVISION_POSITION.value].median()
df[RaceFields.DIVISION_POSITION.value].fillna(median_div_pos, inplace=True)
df[RaceFields.DIVISION_POSITION.value] = df[RaceFields.DIVISION_POSITION.value].astype(int)
median_div_pos = df[RaceFields.TWENTY_FLOOR_DIVISION_POSITION.value].median()
df[RaceFields.TWENTY_FLOOR_DIVISION_POSITION.value].fillna(median_div_pos, inplace=True)
df[RaceFields.TWENTY_FLOOR_DIVISION_POSITION.value] = df[RaceFields.TWENTY_FLOOR_DIVISION_POSITION.value].astype(int)
median_div_pos = df[RaceFields.SIXTY_FIVE_FLOOR_DIVISION_POSITION.value].median()
df[RaceFields.SIXTY_FIVE_FLOOR_DIVISION_POSITION.value].fillna(median_div_pos, inplace=True)
df[RaceFields.SIXTY_FIVE_FLOOR_DIVISION_POSITION.value] = df[
RaceFields.SIXTY_FIVE_FLOOR_DIVISION_POSITION.value].astype(int)
# Normaliser l'allure et le temps au 65ème étage
sixty_five_floor_pace_median = df[RaceFields.SIXTY_FIVE_FLOOR_PACE.value].median()
sixty_five_floor_time_median = df[RaceFields.SIXTY_FIVE_FLOOR_TIME.value].median()
df[RaceFields.SIXTY_FIVE_FLOOR_PACE.value].fillna(sixty_five_floor_pace_median, inplace=True)
df[RaceFields.SIXTY_FIVE_FLOOR_TIME.value].fillna(sixty_five_floor_time_median, inplace=True)
# Normaliser le BIB et le définir comme index
df[RaceFields.BIB.value] = df[RaceFields.BIB.value].astype(int)
df.set_index(RaceFields.BIB.value, inplace=True)
# L'URL était utile pendant le scraping, pas nécessaire pour l'analyse
df.drop([RaceFields.URL.value], axis=1, inplace=True)
return df
Je fais plusieurs choses ici après avoir renvoyé le CSV converti à l'utilisateur sous forme de DataFrame :
J'ai remplacé les valeurs "Not a Number" (nan) par la médiane pour éviter d'affecter les résultats de l'agrégation. Cela facilite l'analyse.
J'ai supprimé les lignes pour les coureurs qui n'ont pas atteint le 86ème étage. Cela simplifie l'analyse et il y en a très peu.
J'ai converti certaines colonnes de chaînes de caractères en types de données natifs comme les entiers et les timestamps.
Quelques entrées n'avaient pas le genre défini. Cela affectait d'autres champs comme 'gender_position'. Pour éviter les distorsions, ceux-ci ont été remplis avec la médiane.
Au final, voici à quoi ressemblait le chargement de mon DataFrame :
(EmpireStateRunUp) [josevnz@dmaf5 EmpireStateRunUp]$ python3
Python 3.11.6 (main, Oct 3 2023, 00:00:00) [GCC 12.3.1 20230508 (Red Hat 12.3.1-1)] on linux
Type "help", "copyright", "credits" or "license" for more information.
Et l'instance de DataFrame résultante :
>>> # Utilisation de la fonction personnalisée load_data qui renvoie un DataFrame Pandas
>>> from empirestaterunup.data import load_data
>>> load_data('empirestaterunup/results-full-level-2023.csv')
name overall position time gender gender position age ... 65th floor division position 65th floor pace 65th floor time wave level finishtimestamp
bib ...
19 Wai Ching Soh 1 0 days 00:10:36 M 1 29 ... 1 0 days 00:54:03 0 days 00:07:34 ELITE MEN Full Course 2023-09-04 20:10:36
22 Ryoji Watanabe 2 0 days 00:10:52 M 2 40 ... 1 0 days 00:54:31 0 days 00:07:38 ELITE MEN Full Course 2023-09-04 20:10:52
16 Fabio Ruga 3 0 days 00:11:14 M 3 42 ... 2 0 days 00:57:09 0 days 00:08:00 ELITE MEN Full Course 2023-09-04 20:11:14
11 Emanuele Manzi 4 0 days 00:11:28 M 4 45 ... 3 0 days 00:59:17 0 days 00:08:18 ELITE MEN Full Course 2023-09-04 20:11:28
249 Alex Cyr 5 0 days 00:11:52 M 5 28 ... 2 0 days 01:01:19 0 days 00:08:35 SPONSORS Full Course 2023-09-04 20:11:52
.. ... ... ... ... ... ... ... ... ... ... ... ... ...
555 Caroline Edwards 372 0 days 00:55:17 F 143 47 ... 39 0 days 04:57:23 0 days 00:41:38 GENERAL 2 Full Course 2023-09-04 20:55:17
557 Sarah Preston 373 0 days 00:55:22 F 144 34 ... 41 0 days 04:58:20 0 days 00:41:46 GENERAL 2 Full Course 2023-09-04 20:55:22
544 Christopher Winkler 374 0 days 01:00:10 M 228 40 ... 18 0 days 01:49:53 0 days 00:15:23 GENERAL 2 Full Course 2023-09-04 21:00:10
545 Jay Winkler 375 0 days 01:05:19 U 93 33 ... 18 0 days 05:28:56 0 days 00:46:03 GENERAL 2 Full Course 2023-09-04 21:05:19
646 Dana Zajko 376 0 days 01:06:48 F 145 38 ... 42 0 days 05:15:14 0 days 00:44:08 GENERAL 3 Full Course 2023-09-04 21:06:48
[375 rows x 24 columns]
Une fois les données chargées, j'ai pu commencer à poser des questions. Par exemple, pour détecter les valeurs aberrantes, j'ai utilisé un Z-score.
Toute la logique d'analyse a été regroupée dans un seul module appelé 'analyze', séparé de la présentation, du chargement des données ou des rapports, afin de favoriser la réutilisation.
from pandas import DataFrame
import numpy as np
def get_zscore(df: DataFrame, column: str):
filtered = df[column]
return filtered.sub(filtered.mean()).div(filtered.std(ddof=0))
def get_outliers(df: DataFrame, column: str, std_threshold: int = 3) -> DataFrame:
"""
Utilise le z-score, tout ce qui est plus éloigné que 3 écarts-types est considéré comme une valeur aberrante.
"""
filtered_df = df[column]
z_scores = get_zscore(df=df, column=column)
is_over = np.abs(z_scores) > std_threshold
return filtered_df[is_over]
De plus, il est très simple d'obtenir des statistiques communes en appelant simplement describe sur nos données :
from pandas import DataFrame
def get_5_number(criteria: str, data: DataFrame) -> DataFrame:
return data[criteria].describe()
Par exemple, voici les métriques récapitulatives pour différents aspects de la course :
>>> from empirestaterunup.data import load_data
>>> df = load_data('empirestaterunup/results-full-level-2023.csv')
>>> from empirestaterunup.analyze import get_5_number
>>> from empirestaterunup.analyze import SUMMARY_METRICS
>>> print(SUMMARY_METRICS)
('age', 'time', 'pace')
>>> for key in SUMMARY_METRICS:
... ndf = get_5_number(criteria=key, data=df)
... print(ndf)
...
count 375.000000
mean 41.309333
std 11.735968
min 11.000000
25% 33.000000
50% 40.000000
75% 49.000000
max 78.000000
Name: age, dtype: float64
count 375
mean 0 days 00:23:03.461333333
std 0 days 00:08:06.313479117
min 0 days 00:10:36
25% 0 days 00:18:09
50% 0 days 00:21:20
75% 0 days 00:25:13.500000
max 0 days 01:06:48
Name: time, dtype: object
count 375
mean 0 days 01:55:17.306666666
std 0 days 00:40:31.567395588
min 0 days 00:53:00
25% 0 days 01:30:45
50% 0 days 01:46:40
75% 0 days 02:06:07.500000
max 0 days 05:34:00
Name: pace, dtype: object
S'assurer que le web scraping, le chargement des données et les analyses fonctionnent bien est impératif. Les tests font partie intégrante de l'écriture de code, j'ai donc continué à en ajouter et je suis revenu à l'écriture de tests unitaires.
Voyons comment tester notre code (n'hésitez pas à sauter la section suivante si vous êtes familier avec les tests unitaires).
Tester, tester, et après ça... encore tester
Je suppose que vous savez écrire de petits morceaux de code autonomes pour tester votre programme. C'est ce qu'on appelle des tests unitaires.
Le Framework de test unitaire unittest a été initialement inspiré par JUnit et présente une saveur similaire aux principaux frameworks de test unitaire dans d'autres langages. Il prend en charge l'automatisation des tests, le partage du code de configuration et de fermeture pour les tests, le regroupement des tests en collections et l'indépendance des tests par rapport au framework de reporting. (Tiré de la documentation Python)
J'ai essayé d'avoir un test unitaire simple pour chaque méthode que j'ai écrite dans le code. Cela m'a épargné bien des maux de tête par la suite. Au fur et à mesure que je refactorisais le code, j'ai trouvé de meilleures façons d'obtenir les mêmes résultats, produisant des chiffres corrects.
Un test unitaire dans ce contexte est une classe qui étend unittest.TestCase. Chaque méthode commençant par test_ est un test qui doit passer plusieurs assertions.
Par exemple, pour m'assurer que l'analyse fonctionnait comme prévu, j'ai écrit un module de test appelé test_analyze :
# Tous les cas de test ne sont pas affichés, veuillez consulter le code complet de 'test/test_analyze.py'
import unittest
from pandas import DataFrame
from empirestaterunup.analyze import get_country_counts
from empirestaterunup.data import load_data
class AnalyzeTestCase(unittest.TestCase):
df: DataFrame
@classmethod
def setUpClass(cls) -> None:
cls.df = load_data()
def test_get_country_counts(self):
country_counts, min_countries, max_countries = get_country_counts(df=AnalyzeTestCase.df)
self.assertIsNotNone(country_counts)
self.assertEqual(2, country_counts['JPN'])
self.assertIsNotNone(min_countries)
self.assertEqual(3, min_countries.shape[0])
self.assertIsNotNone(max_countries)
self.assertEqual(14, max_countries.shape[0])
if __name__ == '__main__':
unittest.main()
Jusqu'à présent, nous avons obtenu les données et nous nous sommes assurés qu'elles répondaient aux attentes. J'ai écrit des tests séparés pour le code d'analyse ainsi que pour le scraper.
Tester l'interface utilisateur nécessite une approche différente, car il faut simuler des clics et attendre des changements d'écran. Parfois, les échecs sont faciles à repérer (comme les plantages), mais parfois les problèmes sont beaucoup plus subtils (avons-nous affiché les bonnes données ?).
Nous reviendrons sur cette modalité de test particulière après avoir introduit la manière de visualiser les résultats.
Comment visualiser les résultats
Je voulais utiliser le terminal autant que possible pour visualiser mes conclusions et limiter les dépendances au minimum. J'ai décidé d'utiliser le framework Textual pour accomplir cela.
Ce Framework est très complet et permet de construire des applications textuelles réactives et esthétiques.
Elles sont également faciles à écrire, alors avant d'approfondir les applications résultantes, faisons une pause pour en apprendre davantage sur Textual.
Interfaces utilisateur textuelles (TUI) avec Textual
Le projet Textual propose un excellent tutoriel que vous pouvez lire pour vous mettre à niveau.
Voyons un peu de code. L'une des applications s'appelle esru_outlier. Le code de la TUI réside dans le module apps, qui affiche plusieurs tableaux avec les valeurs aberrantes (outliers) que nous avons trouvées précédemment à l'aide du z-score.
OutlierApp (qui étend App) collecte toutes les informations de base dans un tableau pour chaque groupe de valeurs aberrantes, puis appelle le RunnerDetailScreen pour afficher les détails d'un coureur.
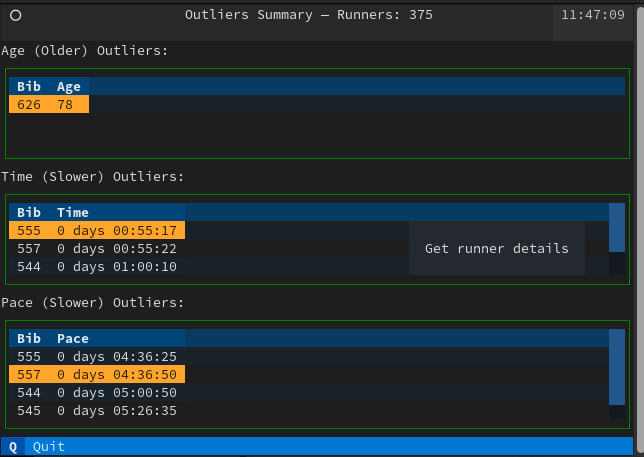
Premier écran des valeurs aberrantes (par Âge, Temps de course et Allure)
Voici le code avec des explications montrant comment construire cet écran :
# Seul le code de l'application est montré ici
# Cette application affiche 3 tableaux : SUMMARY_METRICS = (RaceFields.AGE.value, RaceFields.TIME.value, RaceFields.PACE.value)
# Chaque application dans Textual étend la classe App
class OutlierApp(App):
DF: DataFrame = None
BINDINGS = [ ("q", "quit_app", "Quit"), ] # Lie 'q' à la méthode `action_quit_app`, qui quitte ensuite l'application
CSS_PATH = "outliers.tcss" # Le style peut être fait de manière externe, similairement à l'utilisation de CSS
ENABLE_COMMAND_PALETTE = False
def action_quit_app(self):
self.exit(0)
def compose(self) -> ComposeResult:
"""
Ici, nous utilisons 'Yield' pour les Widgets/composants qui seront rendus dans l'ordre sur la TUI
Comment les composants obtiennent-ils leur mise en page à l'écran ? Ils utilisent une feuille de style en cascade (CSS) : outliers.tcss et
certains conteneurs de mise en page explicites comme la classe `Vertical` qui peut contenir d'autres Widgets
Ici, nous avons un en-tête, des tableaux et un pied de page
"""
yield Header(show_clock=True)
for column_name in SUMMARY_METRICS:
table = DataTable(id=f'{column_name}_outlier')
table.cursor_type = 'row'
table.zebra_stripes = True
table.tooltip = "Obtenir les détails du coureur"
if column_name == RaceFields.AGE.value:
label = Label(f"{column_name} (plus âgé) outliers :".title())
else:
label = Label(f"{column_name} (plus lent) outliers :".title())
yield Vertical(
label,
table
)
yield Footer()
def on_mount(self) -> None:
"""
Ici, nous remplissons chaque tableau avec les données du DataFrame. Chaque tableau contient des valeurs aberrantes de différents types.
Toutes peuvent être obtenues avec la méthode `get_outliers`.
"""
for column in SUMMARY_METRICS:
table = self.get_widget_by_id(f'{column}_outlier', expect_type=DataTable)
columns = [x.title() for x in ['bib', column]]
table.add_columns(*columns)
table.add_rows(*[get_outliers(df=OutlierApp.DF, column=column).to_dict().items()])
@on(DataTable.HeaderSelected)
def on_header_clicked(self, event: DataTable.HeaderSelected):
"""
Lorsque l'utilisateur sélectionne un en-tête de colonne, cela génère un événement 'HeaderSelected'.
L'annotation sur cette méthode indique à Textual que nous allons gérer cet événement ici.
Nous pouvons extraire le tableau, la colonne sélectionnée, puis trier le contenu du tableau.
"""
table = event.data_table
table.sort(event.column_key)
@on(DataTable.RowSelected)
def on_row_clicked(self, event: DataTable.RowSelected) -> None:
"""
De même, lorsque l'utilisateur sélectionne une ligne, cela génère une méthode RowSelected.
Ce que nous faisons dans la méthode 'on_row_clicked' est de capturer l'événement, de récupérer le contenu de la ligne et de construire
un nouvel écran modal (RunnerDetailScreen) que nous poussons par-dessus l'écran normal.
Là, nous affichons les détails du coureur différemment.
"""
table = event.data_table
row = table.get_row(event.row_key)
runner_detail = RunnerDetailScreen(df=OutlierApp.DF, row=row)
self.push_screen(runner_detail)
La classe RunnerDetailScreen (qui étend ModalScreen) gère l'affichage des détails du coureur en utilisant du Markdown formaté, qui apparaît lorsque vous cliquez sur le tableau précédemment rendu :
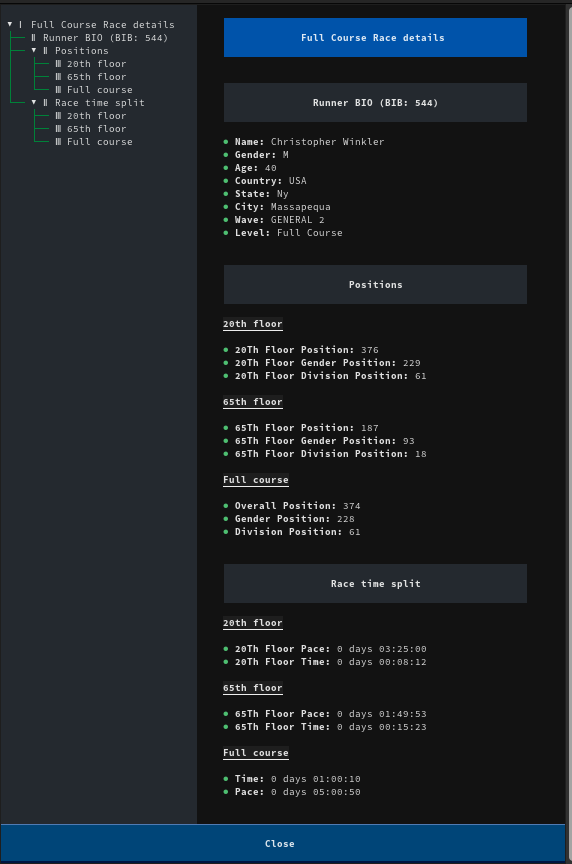
Markdown rendu avec les détails sur le coureur sélectionné
Et voici le code qui permet cela, avec des explications :
# Imports et méthodes auxiliaires omis, affichage uniquement du code lié à la TUI. Voir le fichier 'apps.py' pour le code complet
class RunnerDetailScreen(ModalScreen):
ENABLE_COMMAND_PALETTE = False # Désactive la barre de recherche, elle est active par défaut et n'est pas nécessaire ici
CSS_PATH = "runner_details.tcss" # Gère les styles via un CSS externe
def __init__(
self,
name: str | None = None,
ident: str | None = None,
classes: str | None = None,
row: List[Any] | None = None,
df: DataFrame = None,
country_df: DataFrame = None
):
"""
Surcharge le constructeur et charge les données utiles comme les codes ISO des pays.
Nous récupérons le DataFrame Pandas avec les détails qui seront présentés à l'utilisateur
"""
super().__init__(name, ident, classes)
self.row = row
self.df = df
if not country_df:
self.country_df = load_country_details()
else:
self.country_df = country_df
def compose(self) -> ComposeResult:
"""
Dans compose, nous préparons le markdown et laissons le MarkdownViewer gérer les détails comme
une table des matières automatique agréable.
Notez que nous appelons `self.log.info('xxx')`. Nous l'utilisons pour le débogage lorsque cette application
est appelée avec 'textual'.
"""
bib_idx = FIELD_NAMES_AND_POS[RaceFields.BIB]
bibs = [self.row[bib_idx]]
columns, details = df_to_list_of_tuples(self.df, bibs)
self.log.info(f"Columns: {columns}")
self.log.info(f"Details: {details}")
row_markdown = ""
position_markdown = {}
split_markdown = {}
for legend in ['full', '20th', '65th']:
position_markdown[legend] = ''
split_markdown[legend] = ''
for i in range(0, len(columns)):
column = columns[i]
detail = details[0][i]
if re.search('pace|time', column):
if re.search('20th', column):
split_markdown['20th'] += f"\n* **{column.title()}:** {detail}"
elif re.search('65th', column):
split_markdown['65th'] += f"\n* **{column.title()}:** {detail}"
else:
split_markdown['full'] += f"\n* **{column.title()}:** {detail}"
elif re.search('position', column):
if re.search('20th', column):
position_markdown['20th'] += f"\n* **{column.title()}:** {detail}"
elif re.search('65th', column):
position_markdown['65th'] += f"\n* **{column.title()}:** {detail}"
else:
position_markdown['full'] += f"\n* **{column.title()}:** {detail}"
elif re.search('url|bib', column):
pass # Ignorer les colonnes sans intérêt
else:
row_markdown += f"\n* **{column.title()}:** {detail}"
yield MarkdownViewer(f"""# Détails de la course (Parcours complet)
## BIO du coureur (BIB : {bibs[0]})
{row_markdown}
## Positions
### 20ème étage
{position_markdown['20th']}
### 65ème étage
{position_markdown['65th']}
### Parcours complet
{position_markdown['full']}
## Temps intermédiaires
### 20ème étage
{split_markdown['20th']}
### 65ème étage
{split_markdown['65th']}
### Parcours complet
{split_markdown['full']}
""")
# Ce bouton est utilisé pour fermer cet écran et renvoyer l'utilisateur à l'écran précédent
btn = Button("Fermer", variant="primary", id="close")
btn.tooltip = "Retour à l'écran principal"
yield btn
@on(Button.Pressed, "#close")
def on_button_pressed(self, _) -> None:
"""
Logique simple, retire l'écran précédent et fait disparaître celui-ci
"""
self.app.pop_screen()
Cette classe est réutilisable. Il existe d'autres classes (comme BrowserApp dans ce tutoriel) qui envoient également des données lorsqu'un utilisateur clique sur une ligne de tableau, et ces détails sont affichés via cet écran modal.
Nous pouvons personnaliser l'apparence à l'aide de CSS (oui, comme une application web). Cela ressemble beaucoup au CSS d'une application web (mais ce n'est pas exactement la même chose). Par exemple, pour ajouter du style à un bouton, voici le code :
Button {
dock: bottom;
width: 100%;
height: auto;
}
Comme vous pouvez le voir, Textual est un framework assez puissant. Il me rappelle beaucoup Java Swing, mais sans la complexité supplémentaire.
Mais est-ce seulement des informations au format tabulaire ? Je voulais également avoir différents types de graphiques capables d'expliquer des comportements comme le regroupement par âge et la répartition par genre. Pour cela, j'ai écrit quelques classes dans le module 'apps' avec l'aide de Matplotlib.
Graphiques avec Matplotlib
Je voulais utiliser des graphiques pour afficher les données, et je les ai réalisés avec matplotlib. Le code pour générer une boîte à moustaches (box plot) des âges, qui montre l'âge des coureurs participants, est très simple.
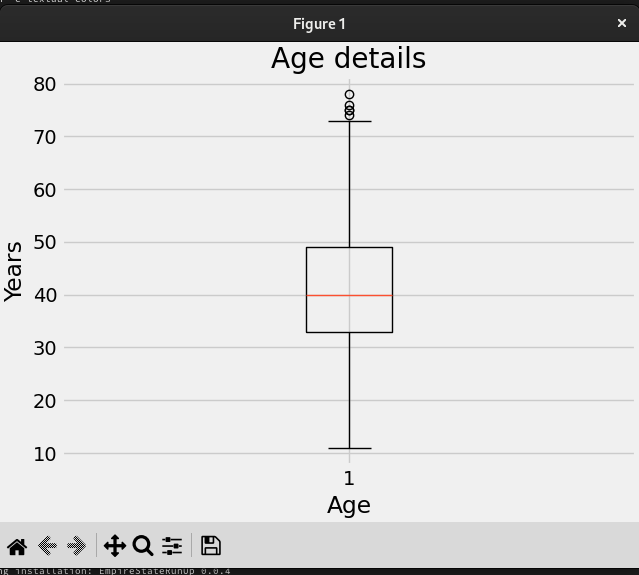
Boîte à moustaches des âges sous Matplotlib qui montre que la plupart des coureurs se situaient dans la tranche des 40-50 ans.
Et voici le code qui a produit ce graphique :
# Tout le code n'est pas affiché ici (méthodes auxiliaires, imports)
# Veuillez consulter le module apps.py pour voir tout le code manquant
class Plotter:
def plot_gender(self):
"""
Dans cette méthode, nous récupérons notre data frame en filtrant par genre et obtenons les décomptes
Puis nous créons un graphique en secteurs (pie plot)
"""
series = self.df[RaceFields.GENDER.value].value_counts()
fig, ax = plt.subplots(layout='constrained')
wedges, texts, auto_texts = ax.pie(
series.values,
labels=series.keys(),
autopct="%%%.2f",
shadow=True,
startangle=90,
explode=(0.1, 0, 0)
)
ax.set_title = "Participation par genre"
ax.set_xlabel('Distribution par genre')
# Légende avec les coureurs les plus rapides par genre
fastest = find_fastest(self.df, FastestFilters.Gender)
fastest_legend = [f"{fastest[gender]['name']} - {beautify_race_times(fastest[gender]['time'])}" for gender in
series.keys()]
ax.legend(wedges, fastest_legend,
title="Les plus rapides par genre",
loc="center left",
bbox_to_anchor=(1, 0, 0.5, 1))
Intéressant – la plupart des coureurs avaient entre 40 et 50 ans.
Revenons maintenant aux tests de la TUI.
Tester les interfaces utilisateur
Quand j'ai commencé à travailler sur ce petit projet, je savais qu'il y aurait beaucoup de tests. Ce dont je n'étais pas sûr, c'était comment j'allais pouvoir tester la TUI.
J'ai pensé qu'au moins deux manières seraient utiles avec Textual : l'une permettant de voir le flux de messages entre les composants et l'autre utilisant des tests unitaires avec une variante :
Suivre le flux de messages avec Textual
Textual prend en charge un mode de développement intéressant qui vous permet de modifier le CSS et de voir les changements sur votre application sans redémarrage. De plus, vous pouvez voir comment les événements de la TUI se propagent, ce qui est inestimable pour le débogage.
Dans un terminal, lancez la console :
(EmpireStateRunUp) [josevnz@dmaf5 EmpireStateRunUp]$ . ~/virtualenv/EmpireStateRunUp/bin/activate
(EmpireStateRunUp) [josevnz@dmaf5 EmpireStateRunUp]$ textual console
▌Textual Development Console v0.46.0
▌Run a Textual app with textual run --dev my_app.py to connect.
▌Press Ctrl+C to quit.
Ensuite, dans un autre terminal, lancez votre application en utilisant le mode développement :
(EmpireStateRunUp) [josevnz@dmaf5 EmpireStateRunUp]$ textual run --dev --command esru_browser
Si vous retournez sur le terminal de votre console, vous verrez tous les messages envoyés avec App.log ainsi que les événements :
───────────────────────────────────────────────────────────────────────────── Client '127.0.0.1' connected ─────────────────────────────────────────────────────────────────────────────
[18:28:17] SYSTEM app.py:2188
Connected to devtools ( ws://127.0.0.1:8081 )
[18:28:17] SYSTEM app.py:2192
---
[18:28:17] SYSTEM app.py:2194
driver=<class 'textual.drivers.linux_driver.LinuxDriver'>
[18:28:17] SYSTEM app.py:2195
loop=<_UnixSelectorEventLoop running=True closed=False debug=False>
[18:28:17] SYSTEM app.py:2196
features=frozenset({'debug', 'devtools'})
[18:28:17] SYSTEM app.py:2228
STARTED FileMonitor({PosixPath('/home/josevnz/EmpireStateCleanup/docs/EmpireStateRunUp/empirestaterunup/browser.tcss')})
[18:28:17] EVENT message_pump.py:706
Load() >>> BrowserApp(title='Race Runners', classes={'-dark-mode'}) method=None
[18:28:17] EVENT message_pump.py:697
Mount() >>> DataTable(id='runners') method=<ScrollView.on_mount>
[18:28:17] EVENT message_pump.py:697
Mount() >>> DataTable(id='runners') method=<Widget.on_mount>
[18:28:17] EVENT message_pump.py:697
Mount() >>> Footer() method=<Footer.on_mount>
[18:28:17] EVENT message_pump.py:697
Mount() >>> Footer() method=<Widget.on_mount>
[18:28:17] EVENT message_pump.py:697
Mount() >>> ToastRack(id='textual-toastrack') method=<Widget.on_mount>
...
RowHighlighted(cursor_row=0, row_key=<textual.widgets._data_table.RowKey object at 0x7fc8d98800d0>) >>> BrowserApp(title='Race Runners', classes={'-dark-mode'}) method=None
[18:28:17] EVENT message_pump.py:697
Mount() >>> ScrollBarCorner() method=<Widget.on_mount>
[18:28:17] EVENT message_pump.py:706
Resize(size=Size(width=2, height=1), virtual_size=Size(width=178, height=47), container_size=Size(width=178, height=47)) >>> ScrollBarCorner() method=None
[18:28:17] EVENT message_pump.py:706
Show() >>> ScrollBarCorner() method=None
Utiliser unittest et Pilot
Le framework dispose de la classe Pilot que vous pouvez utiliser pour effectuer des appels automatisés aux Widgets Textual et attendre des événements. Cela signifie que vous pouvez simuler l'interaction de l'utilisateur avec l'application pour valider qu'elle se comporte comme prévu. C'est plus puissant que les tests unitaires classiques car vous pouvez également couvrir les interactions UI avec les résultats attendus :
import unittest
from textual.widgets import DataTable, MarkdownViewer
from empirestaterunup.apps import BrowserApp
class AppTestCase(unittest.IsolatedAsyncioTestCase):
async def test_browser_app(self):
app = BrowserApp()
self.assertIsNotNone(app)
async with app.run_test() as pilot:
"""
Tester la palette de commandes
"""
await pilot.press("ctrl+\\")
for char in "jose".split():
await pilot.press(char)
await pilot.press("enter")
# Cela renvoie l'écran du coureur. Vérifiez qu'il contient du contenu
markdown_viewer = app.screen.query(MarkdownViewer).first()
self.assertTrue(markdown_viewer.document)
await pilot.click("#close") # Fermer le nouvel écran, retirer l'original
# Retourner à l'écran principal, maintenant sélectionner un coureur mais en utilisant le tableau
table = app.screen.query(DataTable).first()
coordinate = table.cursor_coordinate
self.assertTrue(table.is_valid_coordinate(coordinate))
await pilot.press("enter")
await pilot.pause()
markdown_viewer = app.screen.query(MarkdownViewer).first()
self.assertTrue(markdown_viewer)
# Après avoir validé le markdown une fois de plus, fermer l'application
# Quitter l'application en appuyant sur q
await pilot.press("q")
if __name__ == '__main__':
unittest.main()
C'est inestimable, et c'est quelque chose qui nécessite souvent un ensemble d'outils externes pour être validé (par exemple, en Java, vous avez la classe Robot).
Comment exécuter les applications
Enfin, il est temps de se familiariser avec les mini-applications (vous pouvez voir une démonstration animée des applications TUI ici).
Naviguer dans les données
esru_browser est un navigateur simple qui vous permet de naviguer dans les données brutes de la course.
esru_browser
L'application affiche tous les détails de la course pour chaque coureur dans un tableau permettant le tri par colonne.
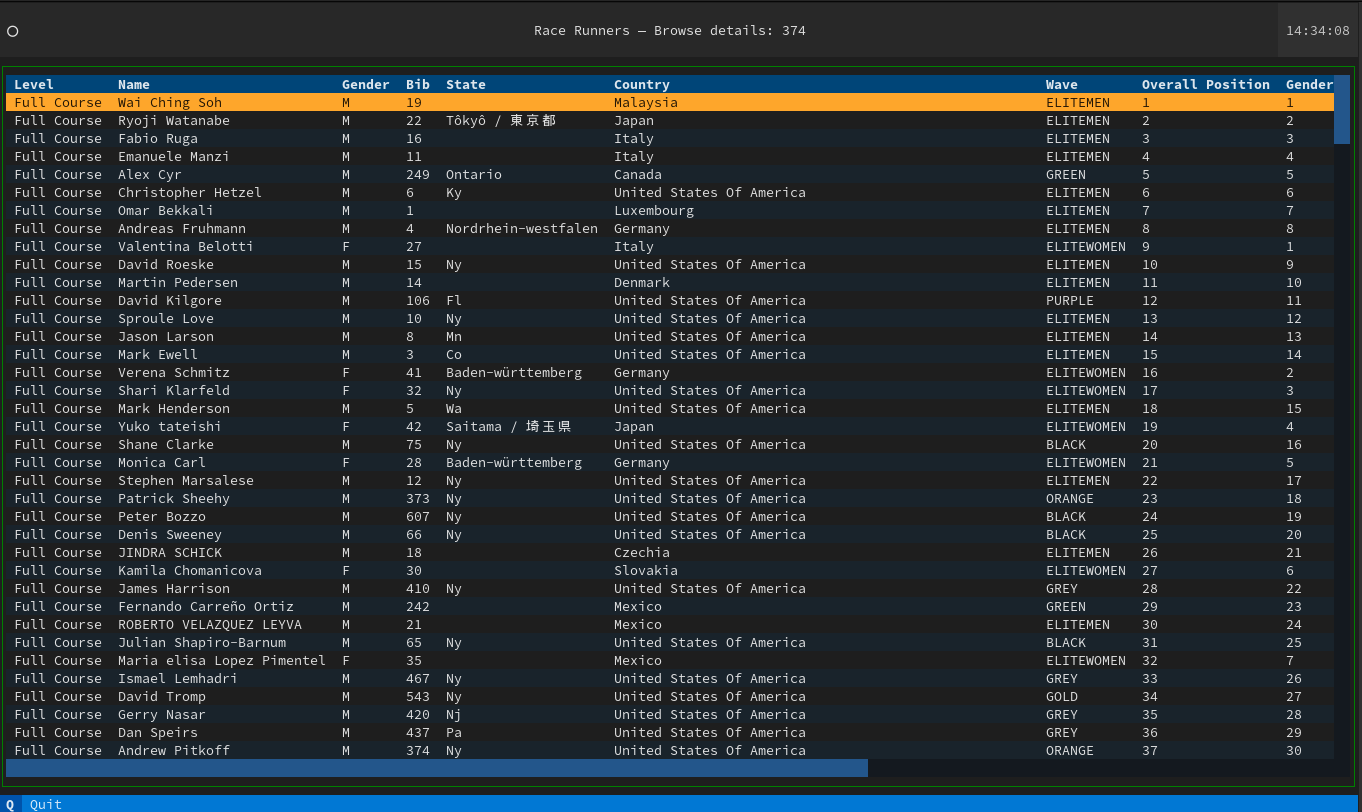
La fenêtre esru_browser affiche tous les résultats des coureurs. Ici, vous pouvez trier, rechercher des coureurs et cliquer pour obtenir plus de détails.
Et la palette de commandes permet de rechercher des coureurs par nom (c'est essentiellement une barre de recherche avec une logique floue) :

Les correspondances s'affichent sur la palette au fur et à mesure que vous tapez.
Rapports récapitulatifs
Pour obtenir des informations sur le comportement des coureurs, vous avez besoin de rapports récapitulatifs (plutôt que de détailler chaque coureur un par un).
Cette application fournit des détails sur les points suivants :
Le décompte, l'écart-type, la moyenne, le minimum, le maximum, les percentiles 45 %, 50 % et 75 % pour l'âge, le temps et l'allure.
La répartition des groupes et des décomptes pour l'Âge, la Vague et le Genre.
esru_numbers
Quelques faits intéressants sur la course :
L'âge moyen était de 41 ans, et le groupe d'âge le plus représenté était celui des 40 ans.
Le plus grand nombre de personnes appartenait à la 'BLACK WAVE'.
La majorité des gens ont terminé la course entre 20 et 30 minutes.
Le plus jeune coureur avait 11 ans, et le plus âgé 78 ans.

esru_numbers donne une vue d'ensemble de tous les coureurs, classés par catégories.
Trouver les valeurs aberrantes (outliers)
Cette application utilise le Z-score pour trouver les valeurs aberrantes pour plusieurs métriques de cette course :
esru_outlier

L'écran principal de esru_outlier vous montre les coureurs qui n'ont pas suivi les schémas habituels.
Parce que ces résultats permettent de remonter jusqu'au numéro de dossard (BIB), vous pouvez cliquer sur une ligne et obtenir plus de détails sur un coureur :

Et vous pouvez obtenir des détails pour chaque outlier. Oui, le code est réutilisable et est le même pour afficher les détails de n'importe quel coureur.
Textual offre un excellent support pour le rendu du Markdown ainsi que des langages de programmation. Jetez un œil au code pour le constater par vous-même.
Quelques graphiques pour vous
L'application esru_plot propose quelques graphiques pour vous aider à visualiser les données. À l'intérieur, la classe Plotter s'occupe de tout le gros travail.
Graphiques d'âge
Le programme peut générer deux variantes pour les mêmes données, l'une étant un diagramme en boîte (Box diagram) :
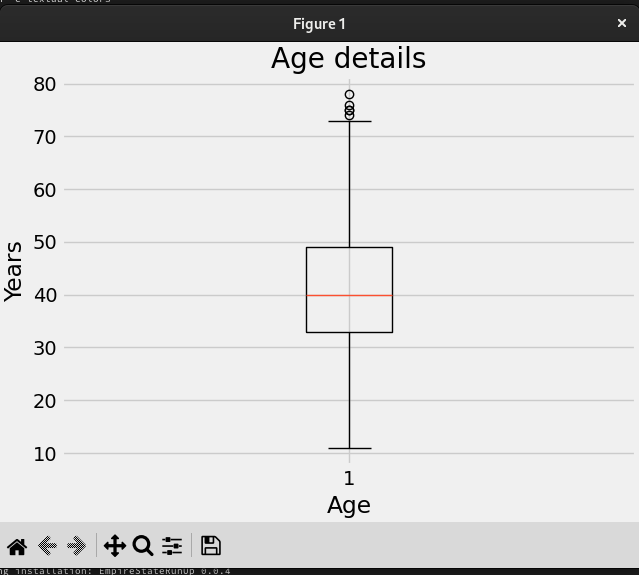
Le diagramme en boîte des âges que nous avons vu précédemment.
La seconde est un histogramme classique :
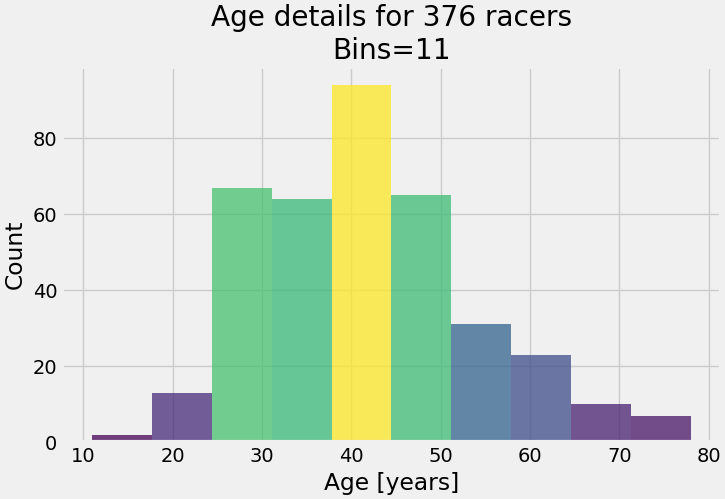
L'histogramme des âges montre la même chose que le diagramme en boîte mais les tranches sont plus visibles. Même données, plusieurs façons d'expliquer la démographie des coureurs.
Vous pouvez voir sur les deux graphiques que le groupe d'âge avec le plus de participants est la tranche des 40-45 ans et que les valeurs aberrantes se trouvent dans les groupes des 10-20 ans et des 70-80 ans.
Graphique des participants par pays
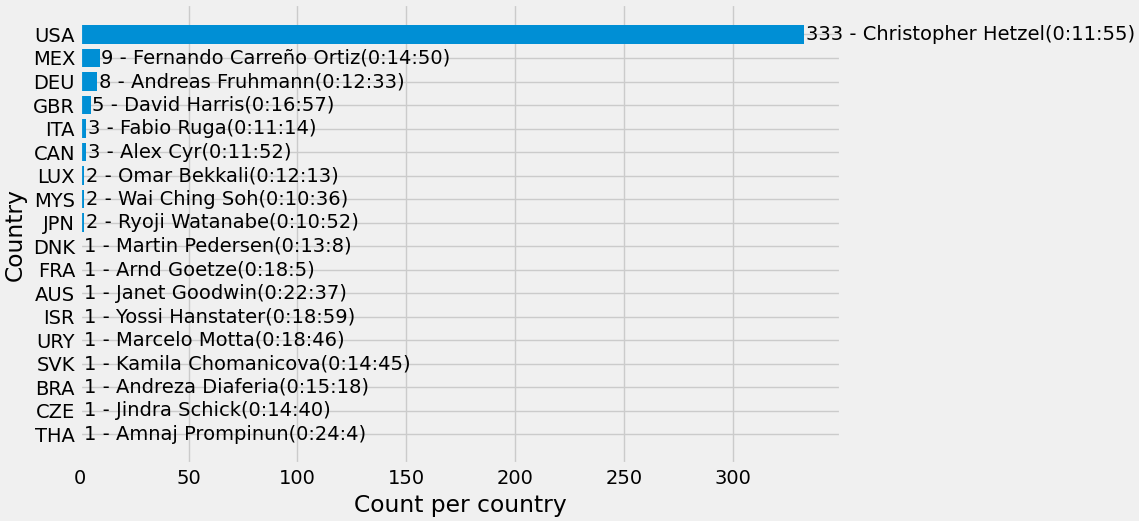
Ce graphique montre tous les pays avec le nombre de participants, avec le meilleur coureur de chacun.
Pas de surprise ici : l'écrasante majorité des coureurs vient des États-Unis, suivis du Mexique. Il est intéressant de noter que le gagnant de la course 2023 vient de Malaisie, avec seulement 2 coureurs participants.
Répartition par genre
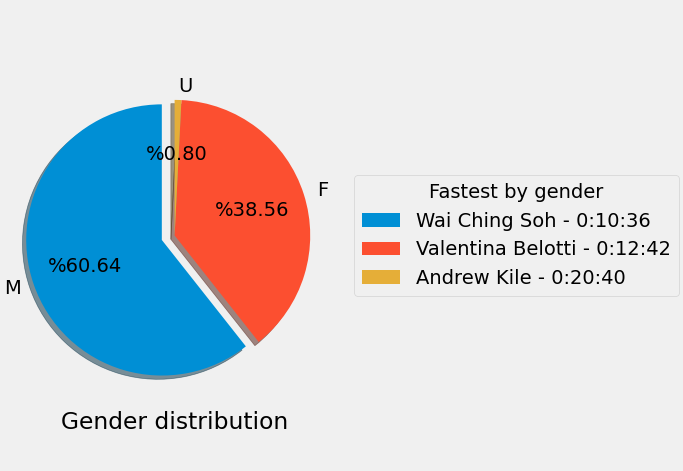
Le diagramme circulaire de répartition par genre montrant le meilleur coureur pour chaque catégorie.
La majorité des coureurs se sont identifiés comme Hommes, suivis des Femmes.
Que pouvons-nous apprendre d'autre ?

NYC était bien représentée lors de l'événement. Oui, je parle de la police de New York courant en équipement complet, pas de moi sur la gauche ;-)
Participer à cette course a été une expérience formidable. Le meilleur, c'est que cela a alimenté ma curiosité et m'a conduit à écrire ce code pour obtenir des faits plus intéressants sur la course.
Il y a bien plus à apprendre sur les outils que vous venez de voir dans ce tutoriel :
Il existe de nombreux jeux de données de courses publics, et vous pouvez les utiliser pour appliquer ce que vous avez appris ici. Jetez simplement un œil à ce jeu de données du Marathon de New York, période 1970-2018. Quelles autres questions pouvez-vous poser sur les données ?
Vous n'avez vu qu'une infime partie de ce que vous pouvez faire avec Textual. Je vous encourage à explorer le module apps.py. Jetez également un œil aux exemples d'applications.
Selenium Web driver n'est pas seulement un outil de web scraping mais aussi de test automatisé d'applications web. Il n'y a rien de mieux que d'avoir votre navigateur effectuant des tests automatisés pour vous. C'est un framework imposant, alors soyez prêt à passer du temps à lire et à exécuter vos tests. Je vous suggère vivement de regarder les exemples. Le tâtonnement (essai et erreur) vous donnera de meilleurs résultats.
Postulez à la loterie de l'Empire Estate Run Up ou courez pour une œuvre caritative, si vous aimez ce genre de course. Qui a dit que King Kong était le seul à pouvoir atteindre le sommet ?
Malheureusement, je ne suis pas en position de vous offrir des conseils d'entraînement. Chaque personne est différente. Je vous recommande de consulter votre médecin avant de participer à une course comme celle-ci, et de demander conseil à un entraîneur de course à pied professionnel.
Mais le plus important de tout, croyez que vous pouvez le faire (la course et l'écriture d'outils pour traiter les données de la course) et amusez-vous en le faisant. C'est un prérequis pour tout projet.