


Article original : So Malcolm Gladwell got the data all wrong...or did he?
Dans cet article, je vais partager quelques explorations de débutant que j'ai faites dans les domaines de l'analyse de données et du hockey professionnel.
J'ai récemment entrepris un voyage un peu fou dans le monde de l'analyse de données. Il n'y a rien de si fou dans l'analyse de données, bien sûr. C'est mon voyage qui est un peu étrange.
Vous voyez, je me suis construit une belle carrière dans l'administration cloud et Linux, mais je ne suis pas développeur. Et, en dehors de quelques chevauchements évidents, les données constituent un univers à part de l'administration - un univers où la programmation à un certain niveau ne peut tout simplement pas être évitée.
Mais certaines parties de mon travail m'obligent à suivre de près les grandes tendances en développement dans la technologie. Et les données sont importantes. Depuis des années, j'observe tous les enfants (non) cool qui jouent avec les chiffres qui font fonctionner le monde moderne et, franchement, je suis jaloux.
Alors me voilà. Je vais me débattre dans un territoire très peu familier, faire quelques erreurs stupides et m'amuser. Vous voulez me rejoindre ?
Cet article ne commencera pas par les bases absolues. Si vous cherchez toujours à faire vos premiers pas en Python, consultez ceci. Et si vous voulez savoir comment commencer avec un environnement de programmation comme les notebooks Jupyter que j'utilise, regardez par ici. Je supposerai que vous êtes déjà à l'aise avec tout cela.
Les dates de naissance comptent-elles dans le sport ?
Je vais commencer par la question à laquelle je vais essayer de répondre :
Avez-vous plus de chances de réussir en tant qu'athlète d'élite si votre anniversaire tombe tôt dans l'année civile ?
Il a été affirmé que les sports de jeunesse qui divisent les participants par âge et fixent la date limite annuelle au 31 décembre rendent involontairement plus difficile pour les joueurs de la seconde moitié de l'année de réussir. C'est parce qu'ils seront en compétition contre des joueurs qui sont de plusieurs mois plus âgés.
À un âge plus jeune, ces mois peuvent faire une très grande différence en termes de force physique, de taille et de coordination. Si vous étiez un entraîneur de ligue mineure cherchant à investir dans des talents pour une meilleure équipe dans une ligue plus forte, qui choisiriez-vous ? Et qui bénéficierait à long terme de votre attention supplémentaire ?
C'est là que l'écrivain bien connu, penseur, (et fellow Canadian) Malcolm Gladwell intervient. Gladwell n'était pas en fait la source originale de cette idée, bien qu'il soit celui qui y est le plus souvent associé.
Plutôt, ces honneurs reviennent au psychologue Roger Barnesly qui a remarqué une distribution étrange des dates de naissance parmi les joueurs lors d'un match de hockey junior d'élite auquel il assistait. Pourquoi tant de ces athlètes talentueux étaient-ils nés tôt dans l'année ? Gladwell a simplement mentionné l'idée de Barnesly dans son livre Outliers, c'est là que je l'ai découverte.
Mais est-ce que tout cela est vrai ? L'observation de Barnesly n'était-elle qu'une supposition intrigante, ou les données du monde réel la confirment-elles ?
Où la NHL cache-t-elle ses données ?
Quelques-uns de mes enfants sont encore adolescents, donc, pour le meilleur ou pour le pire, il est impossible d'échapper à la longue ombre du hockey dans ma maison. Pour nourrir leur appétit insatiable pour de telles choses, j'ai découvert l'existence d'une API officielle robuste mais non documentée maintenue par la Ligue nationale de hockey. Cette URL :
https://statsapi.web.nhl.com/api/v1/teams/15/roster
...par exemple, produira un ensemble de données au format JSON contenant l'effectif officiel actuel des Washington Capitals. En changeant ce 15 dans l'URL en, disons, 10, vous obtiendrez les mêmes informations sur les Toronto Maple Leafs.
Il existe de nombreux points de terminaison de ce type dans le cadre de l'API. Beaucoup de ces points de terminaison peuvent, en outre, être modifiés en utilisant la syntaxe d'expansion d'URL.
Fait amusant : si vous regardez l'icône du site dans l'onglet du navigateur tout en étant sur une page web générée par l'API de la NHL, vous verrez la marque déposée de la Major League Baseball. Comment cela a-t-il pu se produire ?
Comment utiliser Python pour extraire les statistiques de la NHL
Sachant tout cela, je pourrais extraire les données de l'effectif de chaque équipe pour obtenir le numéro d'identification de chaque joueur, puis utiliser ces identifiants pour interroger le point de terminaison unique de chaque joueur et lire sa date de naissance. Je pourrais ensuite extraire le mois de naissance de chaque joueur de la NHL dans un DataFrame Pandas où l'ensemble complet pourrait être calculé et affiché sous forme d'histogramme.
Voici le code que j'ai écrit pour faire tout cela. Je ne vais pas le discuter en détail ici, bien que cela puisse arriver plus tard.
import pandas as pd
import requests
import json
import matplotlib.pyplot as plt
import numpy as np
df3 = pd.DataFrame(columns=['months'])
for team_id in range(1, 11, 1):
url = 'https://statsapi.web.nhl.com/api/v1/teams/{}/roster'.format(team_id)
r = requests.get(url)
roster_data = r.json()
df = pd.json_normalize(roster_data['roster'])
for index, row in df.iterrows():
newrow = row['person.id']
url = 'https://statsapi.web.nhl.com/api/v1/people/{}'.format(newrow)
newerdata = requests.get(url)
player_stats = newerdata.json()
birthday = (player_stats['people'][0]['birthDate'])
newmonth = int(birthday.split('-')[1])
df3 = df3.append({'months': newmonth}, ignore_index=True)
df3.months.hist()
Avant de continuer, je devrais ajouter quelques notes :
- Faites attention à la manière et à la fréquence d'utilisation de ce code. Il y a des boucles for imbriquées, donc l'exécution du script même une fois enverra plus de mille requêtes à l'API de la NHL. Et cela en supposant que tout se passe comme prévu. Si vous faites une erreur, vous pourriez finir par vraiment énerver des gens que vous ne voulez pas énerver.
- Ce code (
for team_id in range(1, 11, 1):) n'extrait en réalité les données que de 11 des 30 équipes de la NHL. Pour une raison quelconque, certains points de terminaison de l'API de l'effectif n'ont pas répondu à mes requêtes et ont en fait fait planter le script. Donc, pour obtenir autant de données que possible, j'ai exécuté le script plusieurs fois. Celui-ci était le premier de ces exécutions. Si vous voulez essayer cela vous-même, retirez la lignedf3 = pd.DataFrame(columns=['months'])des itérations suivantes afin de ne pas réinitialiser par inadvertance la valeur de votre DataFrame à zéro. - Une fois que vous avez extrait vos données avec succès, utilisez quelque chose comme
df3.to_csv('player_data.csv')pour copier vos données dans un fichier CSV, ce qui vous permettra d'analyser davantage le contenu même si le DataFrame original est perdu. Il est toujours bon d'éviter de mettre une charge inutile sur l'origine de l'API.
Comment visualiser les données brutes
D'accord. Où en étais-je ? Exactement. J'ai mes données - les mois de naissance de près de 1 100 joueurs actuels de la NHL - et je veux voir à quoi elles ressemblent. Eh bien, attendez, les voici dans toute leur gloire :
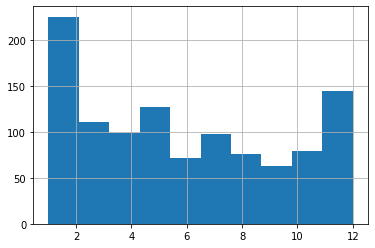
Qu'avons-nous ici ? Il me semble que les naissances de janvier représentent effectivement un nombre disproportionnellement élevé de joueurs, mais il en va de même pour les naissances de décembre. Et, dans l'ensemble, je ne vois tout simplement pas le schéma que l'idée de Gladwell avait prédit. Ah ! Abattu en flammes. Ne faites jamais confiance à un intellectuel !
Erreur. Pas si vite, jeune homme. Sommes-nous sûrs de lire correctement cet histogramme ? Rappelez-vous : je commence tout juste dans ce domaine et j'apprends sur le "tas".
Les paramètres par défaut ne nous ont peut-être pas donné ce que nous pensions. Notez, par exemple, comment nous mesurons la fréquence des naissances sur 12 mois, mais il n'y a que dix barres dans le graphique !
Que se passe-t-il ici ?
Que nous disent vraiment les histogrammes ?
Regardons les chiffres réels derrière cet histogramme. Vous pouvez obtenir ces chiffres en chargeant le fichier CSV que vous avez peut-être exporté plus tôt en utilisant df3.to_csv('player_data.csv'). Voici comment vous pourriez procéder pour faire cela :
import pandas as pd
df = pd.read_csv('player_data.csv')
df['months'].value_counts()
Et voici à quoi ressemblait ma sortie (j'ai ajouté les en-têtes de colonne manuellement) :
Month Frequecy
5 127
2 121
3 111
1 104
4 99
7 98
10 79
8 76
12 75
6 71
11 69
9 63
Il semble qu'il y ait eu 127 naissances en mai, 121 en février et 111 en mars. Décembre n'en avait que 75.
Oups. Désolé Malcolm. J'aurais dû avoir plus de foi. Voyez-vous comment les cinq mois avec les fréquences de naissance les plus élevées sont les cinq premiers mois de l'année ? Maintenant, c'est exactement ce que la prédiction de Gladwell attendrait. Alors, qu'en est-il de l'histogramme ?
Relançons-le, mais cette fois, je vais spécifier 12 bins plutôt que les dix par défaut.
import pandas as pd
df = pd.read_csv('player_data.csv')
df.hist(column='months', bins=12);
Un "bin" est en fait une approximation d'un intervalle statistiquement approprié entre les ensembles de vos données. Les bins tentent de deviner la fonction de densité de probabilité (PDF) qui représentera le mieux les valeurs que vous utilisez réellement. Mais ils peuvent ne pas s'afficher exactement comme vous le pensez - surtout lorsque vous utilisez les paramètres par défaut. Voici ce qui nous est montré en utilisant 12 bins :
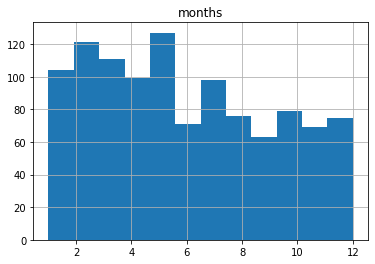
Celui-ci nous montre probablement une représentation exacte de nos données telle que nous nous attendrions à la voir. Je dis "probablement", car il pourrait y avoir quelques idiosyncrasies avec la manière dont les histogrammes divisent leurs bins dont je ne suis pas conscient.
Assurez-vous d'utiliser les bons outils pour le travail
Mais il s'avère que le modeste histogramme était en fait le mauvais outil de visualisation pour nos besoins.
Les histogrammes sont excellents pour montrer les distributions de fréquence en regroupant les points de données ensemble dans des bins. Cela peut nous aider à visualiser rapidement l'état d'un très grand ensemble de données où la précision granulaire se mettra en travers. Mais cela peut être trompeur pour des cas d'utilisation comme le nôtre.
Au lieu de cela, utilisons un bon vieux graphique à barres qui incorpore les arguments groupby et count.
df.groupby('months').count().plot(kind='bar')
L'exécution de cela nous donnera quelque chose de plus facile à lire et aussi plus intuitivement fiable :
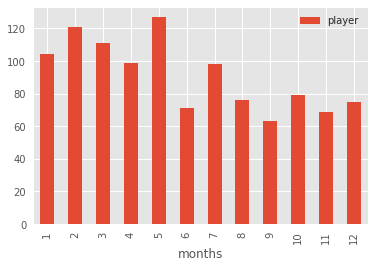
C'est mieux, non ? Nous pouvons voir que les cinq mois avec les fréquences de naissance les plus élevées sont au début de l'année.
La morale de l'histoire ? Les données sont bonnes. Les histogrammes sont bons. Mais il est aussi bon de savoir comment les lire et quand les utiliser.
_Il y a beaucoup plus de bonnes pratiques d'administration sous forme de livres, de cours et d'articles disponibles sur mon site : bootstrap-it.com.