


Article original : KNN Algorithm – K-Nearest Neighbors Classifiers and Model Example
L'algorithme des K Plus Proches Voisins (K-NN) est un algorithme populaire d'apprentissage automatique, principalement utilisé pour résoudre des problèmes de classification.
Dans cet article, vous apprendrez comment fonctionne l'algorithme K-NN avec des exemples pratiques.
Nous utiliserons des diagrammes ainsi que des données d'exemple pour montrer comment vous pouvez classer des données en utilisant l'algorithme K-NN. Nous discuterons également des avantages et des inconvénients de l'utilisation de cet algorithme.
Comment Fonctionne l'Algorithme des K Plus Proches Voisins ?
L'algorithme K-NN compare une nouvelle entrée de données aux valeurs d'un ensemble de données donné (avec différentes classes ou catégories).
En fonction de sa proximité ou de ses similitudes dans une plage donnée (K) de voisins, l'algorithme attribue la nouvelle donnée à une classe ou catégorie dans l'ensemble de données (données d'entraînement).
Décomposons cela en étapes :
Étape #1 - Attribuer une valeur à K.
Étape #2 - Calculer la distance entre la nouvelle entrée de données et toutes les autres entrées de données existantes (vous apprendrez comment faire cela bientôt). Les organiser par ordre croissant.
Étape #3 - Trouver les K voisins les plus proches de la nouvelle entrée en fonction des distances calculées.
Étape #4 - Attribuer la nouvelle entrée de données à la classe majoritaire parmi les voisins les plus proches.
Ne vous inquiétez pas si les étapes ci-dessus semblent confuses pour le moment. Les exemples dans les sections suivantes vous aideront à mieux comprendre.
Classifieurs et Exemple de Modèle des K Plus Proches Voisins Avec des Diagrammes
À l'aide de diagrammes, cette section vous aidera à comprendre les étapes énumérées dans la section précédente.
Considérez le diagramme ci-dessous :
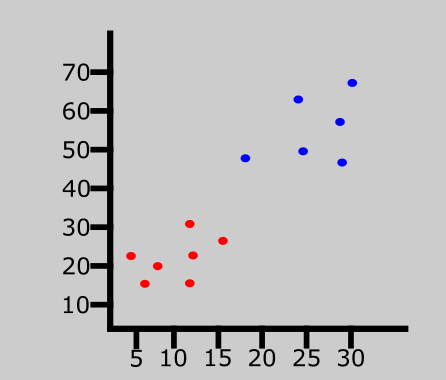
Le graphique ci-dessus représente un ensemble de données composé de deux classes — rouge et bleu.
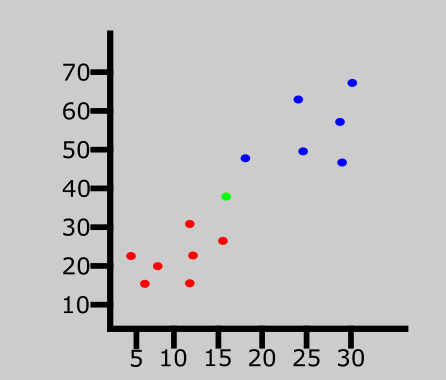
Une nouvelle entrée de données a été introduite dans l'ensemble de données. Cela est représenté par le point vert dans le graphique ci-dessus.
Nous attribuerons ensuite une valeur à K, qui désigne le nombre de voisins à considérer avant de classer la nouvelle entrée de données. Supposons que la valeur de K soit 3.
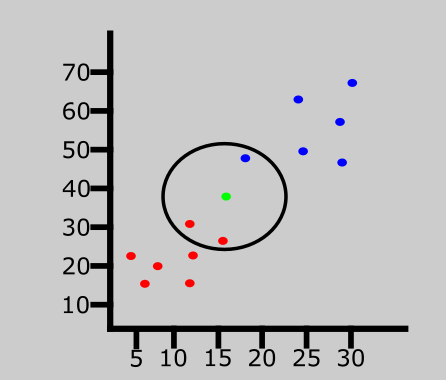
Puisque la valeur de K est 3, l'algorithme ne considérera que les 3 voisins les plus proches du point vert (nouvelle entrée). Cela est représenté dans le graphique ci-dessus.
Parmi les 3 voisins les plus proches dans le diagramme ci-dessus, la classe majoritaire est rouge, donc la nouvelle entrée sera attribuée à cette classe.
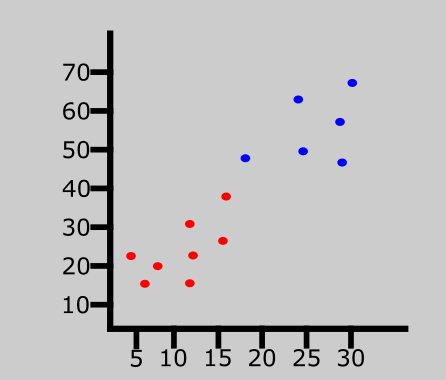
La dernière entrée de données a été classée comme rouge.
Classifieurs et Exemple de Modèle des K Plus Proches Voisins Avec un Ensemble de Données
Dans la dernière section, nous avons vu un exemple de l'algorithme K-NN utilisant des diagrammes. Mais nous n'avons pas discuté de la manière de connaître la distance entre la nouvelle entrée et les autres valeurs de l'ensemble de données.
Dans cette section, nous approfondirons un peu. En plus des étapes suivies dans la dernière section, vous apprendrez comment calculer la distance entre une nouvelle entrée et d'autres valeurs existantes en utilisant la formule de distance euclidienne.
Notez que vous pouvez également calculer la distance en utilisant les formules de distance de Manhattan et de Minkowski.
Commençons !
| Luminosité | Saturation | Classe |
| 40 | 20 | Rouge |
| 50 | 50 | Bleu |
| 60 | 90 | Bleu |
| 10 | 25 | Rouge |
| 70 | 70 | Bleu |
| 60 | 10 | Rouge |
| 25 | 80 | Bleu |
Le tableau ci-dessus représente notre ensemble de données. Nous avons deux colonnes — Luminosité et Saturation. Chaque ligne du tableau a une classe soit Rouge soit Bleu.
Avant d'introduire une nouvelle entrée de données, supposons que la valeur de K est 5.
Comment Calculer la Distance Euclidienne dans l'Algorithme des K Plus Proches Voisins
Voici la nouvelle entrée de données :
| Luminosité | Saturation | Classe |
| 20 | 35 | ? |
Nous avons une nouvelle entrée, mais elle n'a pas encore de classe. Pour connaître sa classe, nous devons calculer la distance de la nouvelle entrée aux autres entrées de l'ensemble de données en utilisant la formule de distance euclidienne.
Voici la formule : √(X₂-X₁)²+(Y₂-Y₁)²
Où :
- X₂ = Luminosité de la nouvelle entrée (20).
- X₁ = Luminosité de l'entrée existante.
- Y₂ = Saturation de la nouvelle entrée (35).
- Y₁ = Saturation de l'entrée existante.
Faisons le calcul ensemble. Je vais calculer les trois premiers.
Distance #1
Pour la première ligne, d1 :
| Luminosité | Saturation | Classe |
| 40 | 20 | Rouge |
d1 = √(20 - 40)² + (35 - 20)²
= √400 + 225
= √625
= 25
Nous connaissons maintenant la distance de la nouvelle entrée de données à la première entrée du tableau. Mettons à jour le tableau.
| Luminosité | Saturation | Classe | Distance |
| 40 | 20 | Rouge | 25 |
| 50 | 50 | Bleu | ? |
| 60 | 90 | Bleu | ? |
| 10 | 25 | Rouge | ? |
| 70 | 70 | Bleu | ? |
| 60 | 10 | Rouge | ? |
| 25 | 80 | Bleu | ? |
Distance #2
Pour la deuxième ligne, d2 :
| Luminosité | Saturation | Classe | Distance |
| 50 | 50 | Bleu | ? |
d2 = √(20 - 50)² + (35 - 50)²
= √900 + 225
= √1125
= 33.54
Voici le tableau avec la distance mise à jour :
| Luminosité | Saturation | Classe | Distance |
| 40 | 20 | Rouge | 25 |
| 50 | 50 | Bleu | 33.54 |
| 60 | 90 | Bleu | ? |
| 10 | 25 | Rouge | ? |
| 70 | 70 | Bleu | ? |
| 60 | 10 | Rouge | ? |
| 25 | 80 | Bleu | ? |
Distance #3
Pour la troisième ligne, d3 :
| Luminosité | Saturation | Classe | Distance |
| 60 | 90 | Bleu | ? |
d2 = √(20 - 60)² + (35 - 90)²
= √1600 + 3025
= √4625
= 68.01
Tableau mis à jour :
| Luminosité | Saturation | Classe | Distance |
| 40 | 20 | Rouge | 25 |
| 50 | 50 | Bleu | 33.54 |
| 60 | 90 | Bleu | 68.01 |
| 10 | 25 | Rouge | ? |
| 70 | 70 | Bleu | ? |
| 60 | 10 | Rouge | ? |
| 25 | 80 | Bleu | ? |
À ce stade, vous devriez comprendre comment fonctionne le calcul. Essayez de calculer la distance pour les quatre dernières lignes.
Voici à quoi ressemblera le tableau après que toutes les distances aient été calculées :
| Luminosité | Saturation | Classe | Distance |
| 40 | 20 | Rouge | 25 |
| 50 | 50 | Bleu | 33.54 |
| 60 | 90 | Bleu | 68.01 |
| 10 | 25 | Rouge | 10 |
| 70 | 70 | Bleu | 61.03 |
| 60 | 10 | Rouge | 47.17 |
| 25 | 80 | Bleu | 45 |
Réorganisons les distances par ordre croissant :
| Luminosité | Saturation | Classe | Distance |
| 10 | 25 | Rouge | 10 |
| 40 | 20 | Rouge | 25 |
| 50 | 50 | Bleu | 33.54 |
| 25 | 80 | Bleu | 45 |
| 60 | 10 | Rouge | 47.17 |
| 70 | 70 | Bleu | 61.03 |
| 60 | 90 | Bleu | 68.01 |
Puisque nous avons choisi 5 comme valeur de K, nous ne considérerons que les cinq premières lignes. C'est-à-dire :
| Luminosité | Saturation | Classe | Distance |
| 10 | 25 | Rouge | 10 |
| 40 | 20 | Rouge | 25 |
| 50 | 50 | Bleu | 33.54 |
| 25 | 80 | Bleu | 45 |
| 60 | 10 | Rouge | 47.17 |
Comme vous pouvez le voir ci-dessus, la classe majoritaire parmi les 5 voisins les plus proches de la nouvelle entrée est Rouge. Par conséquent, nous classerons la nouvelle entrée comme Rouge.
Voici le tableau mis à jour :
| Luminosité | Saturation | Classe |
| 40 | 20 | Rouge |
| 50 | 50 | Bleu |
| 60 | 90 | Bleu |
| 10 | 25 | Rouge |
| 70 | 70 | Bleu |
| 60 | 10 | Rouge |
| 25 | 80 | Bleu |
| 20 | 35 | Rouge |
Comment Choisir la Valeur de K dans l'Algorithme K-NN
Il n'y a pas de méthode particulière pour choisir la valeur K, mais voici quelques conventions courantes à garder à l'esprit :
- Choisir une valeur très faible conduira probablement à des prédictions inexactes.
- La valeur couramment utilisée de K est 5.
- Utilisez toujours un nombre impair comme valeur de K.
Avantages de l'Algorithme K-NN
- Il est simple à implémenter.
- Aucun entraînement n'est requis avant la classification.
Inconvénients de l'Algorithme K-NN
- Peut être coûteux en termes de calcul lors de l'utilisation d'un grand ensemble de données.
- Une grande quantité de mémoire est requise pour traiter de grands ensembles de données.
- Choisir la bonne valeur de K peut être délicat.
Résumé
Dans cet article, nous avons parlé de l'algorithme des K Plus Proches Voisins. Il est souvent utilisé pour les problèmes de classification.
Nous avons vu un exemple utilisant des diagrammes pour expliquer comment fonctionne l'algorithme.
Nous avons également vu un exemple utilisant des données d'exemple pour voir les étapes impliquées dans la classification d'une nouvelle entrée de données.
Enfin, nous avons discuté des avantages et des inconvénients de l'algorithme, et de la manière dont vous pouvez choisir la valeur de K.
Bon codage !